 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPCI-Bench: A Benchmark for Multimodal Pairwise Contextual Integrity Evaluation of Language Model Agents
Jan 13, 2026As language-model agents evolve from passive chatbots into proactive assistants that handle personal data, evaluating their adherence to social norms becomes increasingly critical, often through the lens of Contextual Integrity (CI). However, existing CI benchmarks are largely text-centric and primarily emphasize negative refusal scenarios, overlooking multimodal privacy risks and the fundamental trade-off between privacy and utility. In this paper, we introduce MPCI-Bench, the first Multimodal Pairwise Contextual Integrity benchmark for evaluating privacy behavior in agentic settings. MPCI-Bench consists of paired positive and negative instances derived from the same visual source and instantiated across three tiers: normative Seed judgments, context-rich Story reasoning, and executable agent action Traces. Data quality is ensured through a Tri-Principle Iterative Refinement pipeline. Evaluations of state-of-the-art multimodal models reveal systematic failures to balance privacy and utility and a pronounced modality leakage gap, where sensitive visual information is leaked more frequently than textual information. We will open-source MPCI-Bench to facilitate future research on agentic CI.
SKATER: Synthesized Kinematics for Advanced Traversing Efficiency on a Humanoid Robot via Roller Skate Swizzles
Jan 08, 2026Although recent years have seen significant progress of humanoid robots in walking and running, the frequent foot strikes with ground during these locomotion gaits inevitably generate high instantaneous impact forces, which leads to exacerbated joint wear and poor energy utilization. Roller skating, as a sport with substantial biomechanical value, can achieve fast and continuous sliding through rational utilization of body inertia, featuring minimal kinetic energy loss. Therefore, this study proposes a novel humanoid robot with each foot equipped with a row of four passive wheels for roller skating. A deep reinforcement learning control framework is also developed for the swizzle gait with the reward function design based on the intrinsic characteristics of roller skating. The learned policy is first analyzed in simulation and then deployed on the physical robot to demonstrate the smoothness and efficiency of the swizzle gait over traditional bipedal walking gait in terms of Impact Intensity and Cost of Transport during locomotion. A reduction of $75.86\%$ and $63.34\%$ of these two metrics indicate roller skating as a superior locomotion mode for enhanced energy efficiency and joint longevity.
MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
May 29, 2025Despite the promise of autonomous agentic reasoning, existing workflow generation methods frequently produce fragile, unexecutable plans due to unconstrained LLM-driven construction. We introduce MermaidFlow, a framework that redefines the agentic search space through safety-constrained graph evolution. At its core, MermaidFlow represent workflows as a verifiable intermediate representation using Mermaid, a structured and human-interpretable graph language. We formulate domain-aware evolutionary operators, i.e., crossover, mutation, insertion, and deletion, to preserve semantic correctness while promoting structural diversity, enabling efficient exploration of a high-quality, statically verifiable workflow space. Without modifying task settings or evaluation protocols, MermaidFlow achieves consistent improvements in success rates and faster convergence to executable plans on the agent reasoning benchmark. The experimental results demonstrate that safety-constrained graph evolution offers a scalable, modular foundation for robust and interpretable agentic reasoning systems.
StrucSum: Graph-Structured Reasoning for Long Document Extractive Summarization with LLMs
May 29, 2025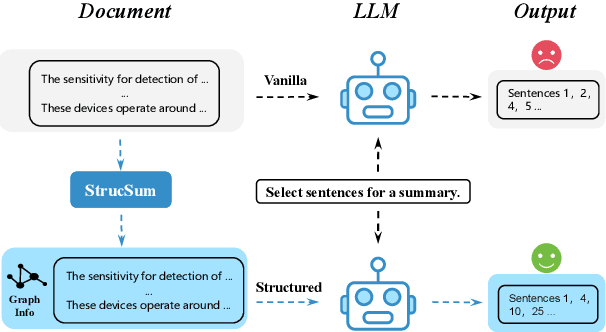
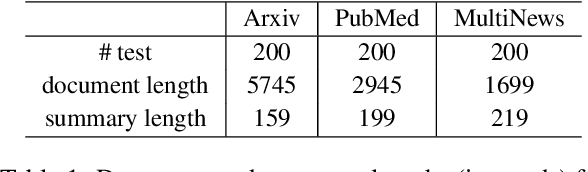
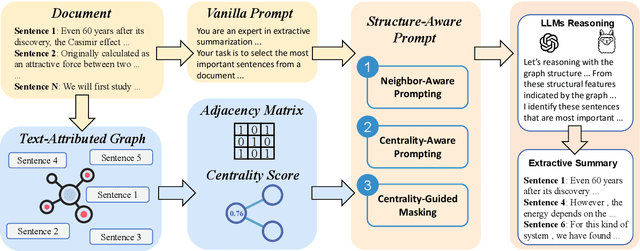
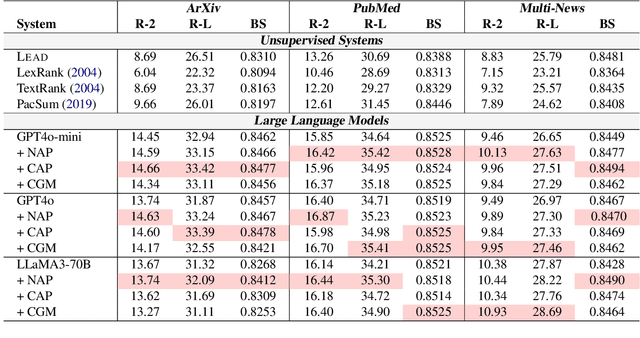
Large language models (LLMs) have shown strong performance in zero-shot summarization, but often struggle to model document structure and identify salient information in long texts. In this work, we introduce StrucSum, a training-free prompting framework that enhances LLM reasoning through sentence-level graph structures. StrucSum injects structural signals into prompts via three targeted strategies: Neighbor-Aware Prompting (NAP) for local context, Centrality-Aware Prompting (CAP) for importance estimation, and Centrality-Guided Masking (CGM) for efficient input reduction. Experiments on ArXiv, PubMed, and Multi-News demonstrate that StrucSum consistently improves both summary quality and factual consistency over unsupervised baselines and vanilla prompting. Notably, on ArXiv, it boosts FactCC and SummaC by 19.2 and 9.7 points, indicating stronger alignment between summaries and source content. These findings suggest that structure-aware prompting is a simple yet effective approach for zero-shot extractive summarization with LLMs, without any training or task-specific tuning.
Wi-Chat: Large Language Model Powered Wi-Fi Sensing
Feb 18, 2025



Recent advancements in Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks. However, their potential to integrate physical model knowledge for real-world signal interpretation remains largely unexplored. In this work, we introduce Wi-Chat, the first LLM-powered Wi-Fi-based human activity recognition system. We demonstrate that LLMs can process raw Wi-Fi signals and infer human activities by incorporating Wi-Fi sensing principles into prompts. Our approach leverages physical model insights to guide LLMs in interpreting Channel State Information (CSI) data without traditional signal processing techniques. Through experiments on real-world Wi-Fi datasets, we show that LLMs exhibit strong reasoning capabilities, achieving zero-shot activity recognition. These findings highlight a new paradigm for Wi-Fi sensing, expanding LLM applications beyond conventional language tasks and enhancing the accessibility of wireless sensing for real-world deployments.
DomainSum: A Hierarchical Benchmark for Fine-Grained Domain Shift in Abstractive Text Summarization
Oct 21, 2024Most research on abstractive summarization focuses on single-domain applications, often neglecting how domain shifts between documents affect performance and the generalization ability of summarization models. To address this issue, we introduce DomainSum, a hierarchical benchmark designed to capture fine-grained domain shifts in abstractive summarization. We categorize these shifts into three levels: genre, style, and topic, and demonstrate through comprehensive benchmark analysis that they follow a hierarchical structure. Furthermore, we evaluate the domain generalization capabilities of commonly used pre-trained language models (PLMs) and large language models (LLMs) in in-domain and cross-domain settings.
A Structure-aware Generative Model for Biomedical Event Extraction
Aug 20, 2024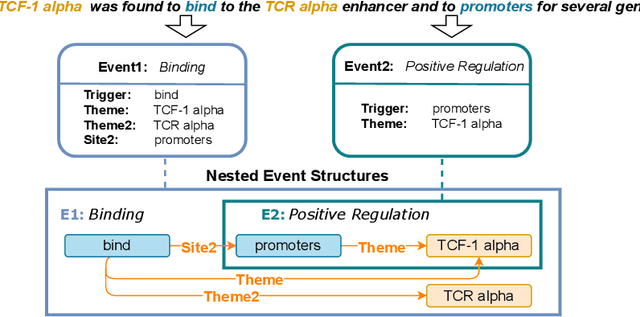

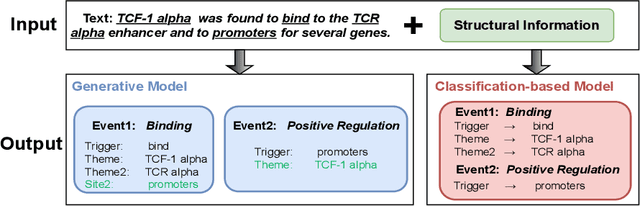

Biomedical Event Extraction (BEE) is a challenging task that involves modeling complex relationships between fine-grained entities in biomedical text. BEE has traditionally been formulated as a classification problem. With the recent technological advancements in large language models (LLMs), generation-based models that cast event extraction as a sequence generation problem have attracted much attention from the NLP research communities. However, current generative models often overlook the importance of cross-instance information from complex event structures such as nested events and overlapping events, which contribute to over 20% of the events in the benchmark datasets. In this paper, we propose an event structure-aware generative model named GenBEE, which can capture complex event structures in biomedical text for biomedical event extraction. In particular, GenBEE constructs event prompts that distill knowledge from LLMs for incorporating both label semantics and argument dependency relationships into the proposed model. In addition, GenBEE also generates prefixes with event structural prompts to incorporate structural features for improving the model's overall performance. We have evaluated the proposed GenBEE model on three widely used biomedical event extraction benchmark datasets, namely MLEE, GE11, and PHEE. Experimental results show that GenBEE has achieved state-of-the-art performance on the MLEE and GE11 datasets, and achieved competitive results when compared to the state-of-the-art classification-based models on the PHEE dataset.
An Event Structure-aware Generative Model for Biomedical Event Extraction
Aug 15, 2024Biomedical Event Extraction (BEE) is a challenging task that involves modeling complex relationships between fine-grained entities in biomedical text. BEE has traditionally been formulated as a classification problem. With the recent technological advancements in large language models (LLMs), generation-based models that cast event extraction as a sequence generation problem have attracted much attention from the NLP research communities. However, current generative models often overlook the importance of cross-instance information from complex event structures such as nested events and overlapping events, which contribute quite significantly in the benchmark datasets. In this paper, we propose an event structure-aware generative model called GenBEE, which can capture complex event structures in biomedical text for biomedical event extraction. In particular, GenBEE constructs event prompts that distill knowledge from LLMs for incorporating both label semantics and argument dependency relationships into the proposed model. In addition, GenBEE also generates prefixes with event structural prompts to incorporate structural features for improving the model's overall performance. We have evaluated the proposed GenBEE model on three widely used biomedical event extraction benchmark datasets, namely MLEE, GE11, and PHEE. Experimental results show that GenBEE has achieved state-of-the-art performance on the MLEE and GE11 datasets, and achieved competitive results when compared to the state-of-the-art classification-based models on the PHEE dataset.
Intermediate Distillation: Data-Efficient Distillation from Black-Box LLMs for Information Retrieval
Jun 18, 2024
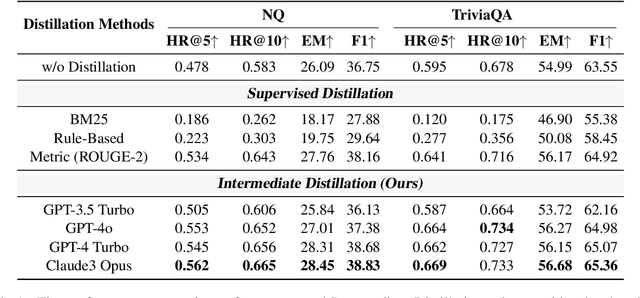
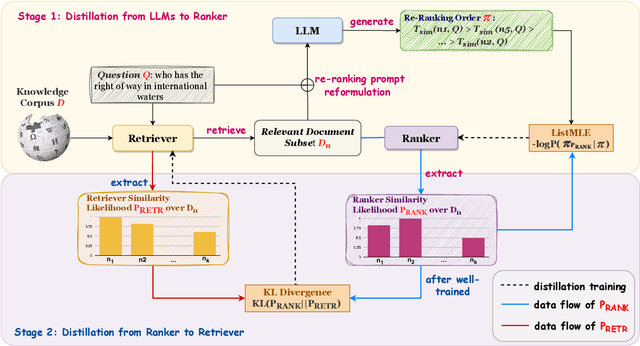
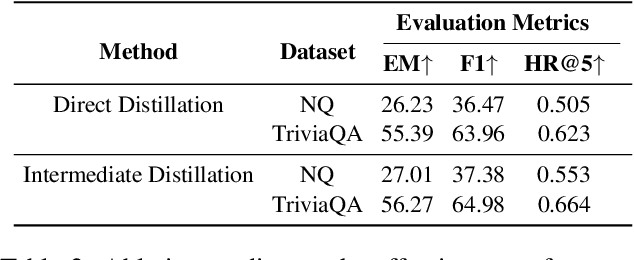
Recent research has explored distilling knowledge from large language models (LLMs) to optimize retriever models, especially within the retrieval-augmented generation (RAG) framework. However, most existing training methods rely on extracting supervision signals from LLMs' weights or their output probabilities, which is not only resource-intensive but also incompatible with black-box LLMs. In this paper, we introduce \textit{Intermediate Distillation}, a data-efficient knowledge distillation training scheme that treats LLMs as black boxes and distills their knowledge via an innovative LLM-ranker-retriever pipeline, solely using LLMs' ranking generation as the supervision signal. Extensive experiments demonstrate that our proposed method can significantly improve the performance of retriever models with only 1,000 training instances. Moreover, our distilled retriever model significantly boosts performance in question-answering tasks within the RAG framework, demonstrating the potential of LLMs to economically and effectively train smaller models.
A Systematic Survey of Text Summarization: From Statistical Methods to Large Language Models
Jun 17, 2024



Text summarization research has undergone several significant transformations with the advent of deep neural networks, pre-trained language models (PLMs), and recent large language models (LLMs). This survey thus provides a comprehensive review of the research progress and evolution in text summarization through the lens of these paradigm shifts. It is organized into two main parts: (1) a detailed overview of datasets, evaluation metrics, and summarization methods before the LLM era, encompassing traditional statistical methods, deep learning approaches, and PLM fine-tuning techniques, and (2) the first detailed examination of recent advancements in benchmarking, modeling, and evaluating summarization in the LLM era. By synthesizing existing literature and presenting a cohesive overview, this survey also discusses research trends, open challenges, and proposes promising research directions in summarization, aiming to guide researchers through the evolving landscape of summarization research.