 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Noise Resilience in Face Clustering via Sparse Differential Transformer
Dec 27, 2025The method used to measure relationships between face embeddings plays a crucial role in determining the performance of face clustering. Existing methods employ the Jaccard similarity coefficient instead of the cosine distance to enhance the measurement accuracy. However, these methods introduce too many irrelevant nodes, producing Jaccard coefficients with limited discriminative power and adversely affecting clustering performance. To address this issue, we propose a prediction-driven Top-K Jaccard similarity coefficient that enhances the purity of neighboring nodes, thereby improving the reliability of similarity measurements. Nevertheless, accurately predicting the optimal number of neighbors (Top-K) remains challenging, leading to suboptimal clustering results. To overcome this limitation, we develop a Transformer-based prediction model that examines the relationships between the central node and its neighboring nodes near the Top-K to further enhance the reliability of similarity estimation. However, vanilla Transformer, when applied to predict relationships between nodes, often introduces noise due to their overemphasis on irrelevant feature relationships. To address these challenges, we propose a Sparse Differential Transformer (SDT), instead of the vanilla Transformer, to eliminate noise and enhance the model's anti-noise capabilities. Extensive experiments on multiple datasets, such as MS-Celeb-1M, demonstrate that our approach achieves state-of-the-art (SOTA) performance, outperforming existing methods and providing a more robust solution for face clustering.
From Cradle to Cane: A Two-Pass Framework for High-Fidelity Lifespan Face Aging
Jun 26, 2025



Face aging has become a crucial task in computer vision, with applications ranging from entertainment to healthcare. However, existing methods struggle with achieving a realistic and seamless transformation across the entire lifespan, especially when handling large age gaps or extreme head poses. The core challenge lies in balancing age accuracy and identity preservation--what we refer to as the Age-ID trade-off. Most prior methods either prioritize age transformation at the expense of identity consistency or vice versa. In this work, we address this issue by proposing a two-pass face aging framework, named Cradle2Cane, based on few-step text-to-image (T2I) diffusion models. The first pass focuses on solving age accuracy by introducing an adaptive noise injection (AdaNI) mechanism. This mechanism is guided by including prompt descriptions of age and gender for the given person as the textual condition. Also, by adjusting the noise level, we can control the strength of aging while allowing more flexibility in transforming the face. However, identity preservation is weakly ensured here to facilitate stronger age transformations. In the second pass, we enhance identity preservation while maintaining age-specific features by conditioning the model on two identity-aware embeddings (IDEmb): SVR-ArcFace and Rotate-CLIP. This pass allows for denoising the transformed image from the first pass, ensuring stronger identity preservation without compromising the aging accuracy. Both passes are jointly trained in an end-to-end way. Extensive experiments on the CelebA-HQ test dataset, evaluated through Face++ and Qwen-VL protocols, show that our Cradle2Cane outperforms existing face aging methods in age accuracy and identity consistency.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024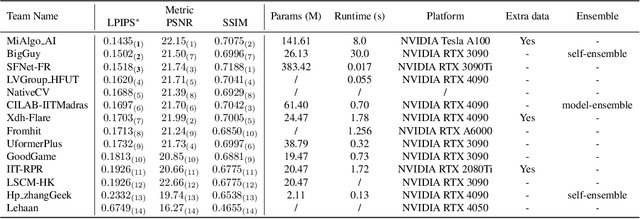
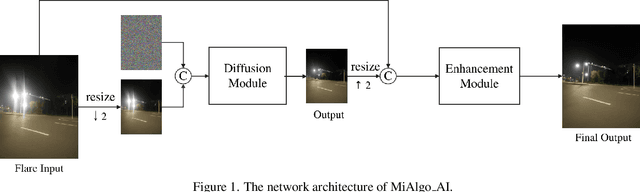
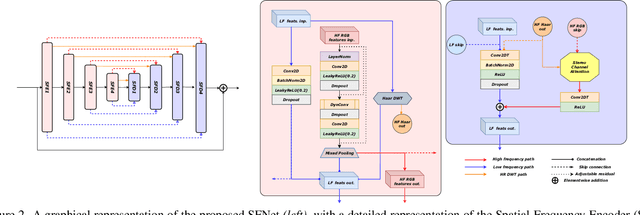
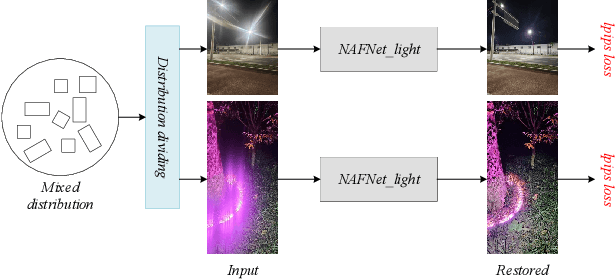
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
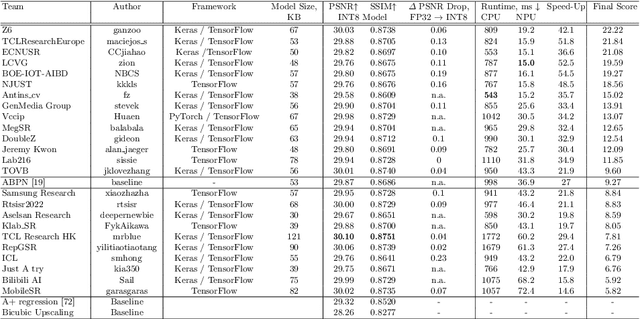
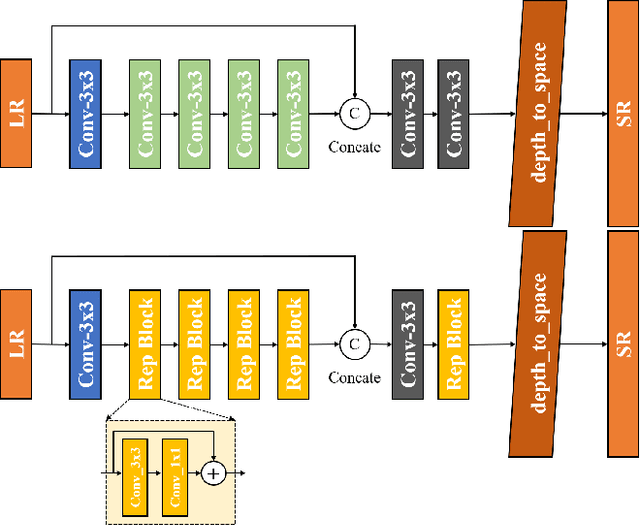
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
DMTNet: Dynamic Multi-scale Network for Dual-pixel Images Defocus Deblurring with Transformer
Sep 13, 2022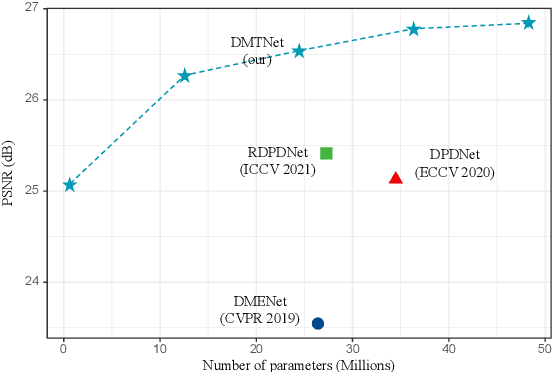



Recent works achieve excellent results in defocus deblurring task based on dual-pixel data using convolutional neural network (CNN), while the scarcity of data limits the exploration and attempt of vision transformer in this task. In addition, the existing works use fixed parameters and network architecture to deblur images with different distribution and content information, which also affects the generalization ability of the model. In this paper, we propose a dynamic multi-scale network, named DMTNet, for dual-pixel images defocus deblurring. DMTNet mainly contains two modules: feature extraction module and reconstruction module. The feature extraction module is composed of several vision transformer blocks, which uses its powerful feature extraction capability to obtain richer features and improve the robustness of the model. The reconstruction module is composed of several Dynamic Multi-scale Sub-reconstruction Module (DMSSRM). DMSSRM can restore images by adaptively assigning weights to features from different scales according to the blur distribution and content information of the input images. DMTNet combines the advantages of transformer and CNN, in which the vision transformer improves the performance ceiling of CNN, and the inductive bias of CNN enables transformer to extract more robust features without relying on a large amount of data. DMTNet might be the first attempt to use vision transformer to restore the blurring images to clarity. By combining with CNN, the vision transformer may achieve better performance on small datasets. Experimental results on the popular benchmarks demonstrate that our DMTNet significantly outperforms state-of-the-art methods.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022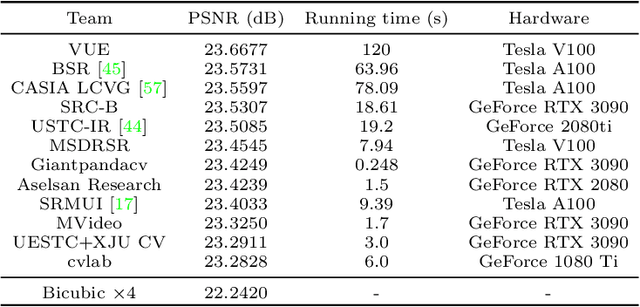
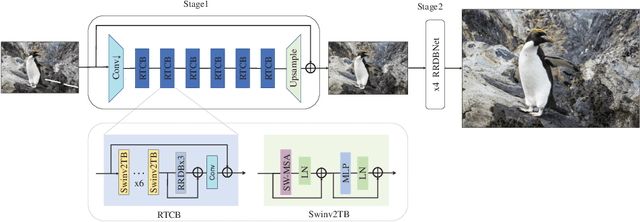

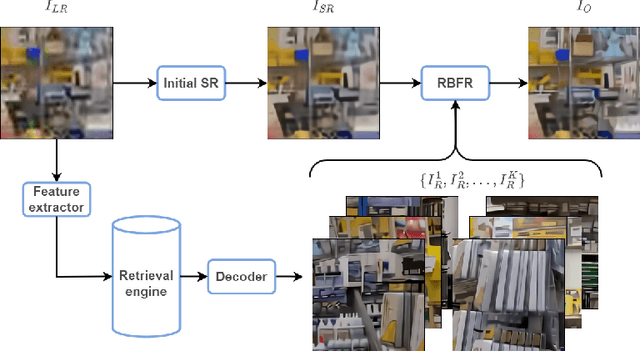
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
Aug 24, 2022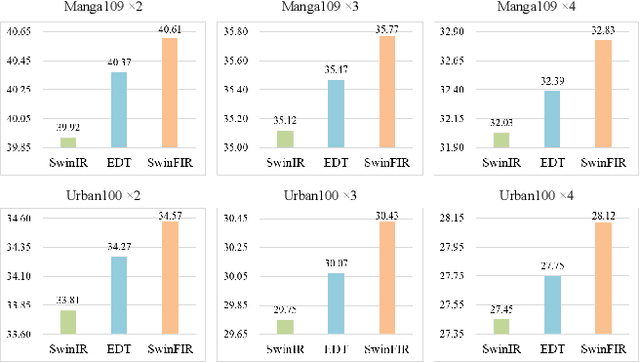
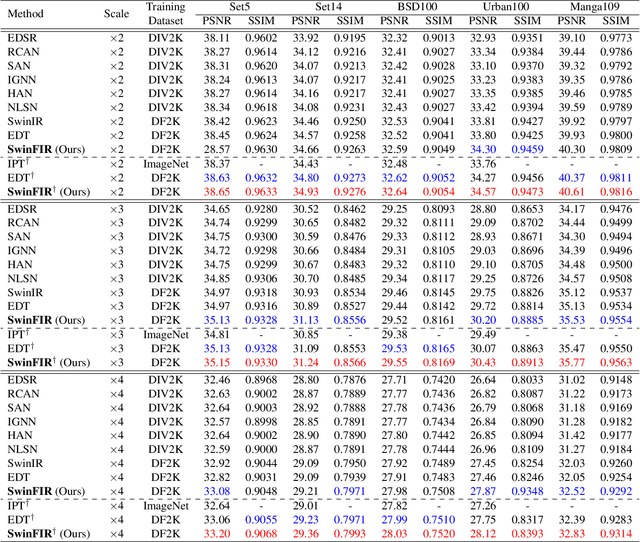

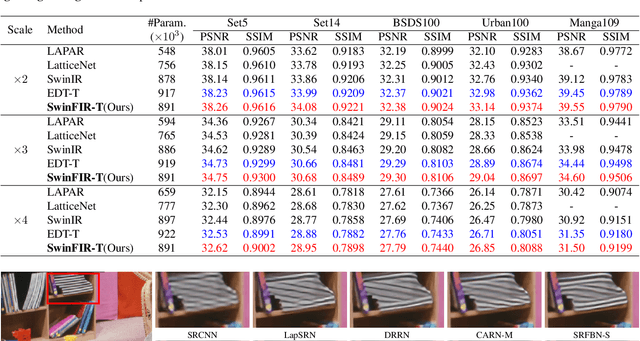
Transformer-based methods have achieved impressive image restoration performance due to their capacities to model long-range dependency compared to CNN-based methods. However, advances like SwinIR adopts the window-based and local attention strategy to balance the performance and computational overhead, which restricts employing large receptive fields to capture global information and establish long dependencies in the early layers. To further improve the efficiency of capturing global information, in this work, we propose SwinFIR to extend SwinIR by replacing Fast Fourier Convolution (FFC) components, which have the image-wide receptive field. We also revisit other advanced techniques, i.e, data augmentation, pre-training, and feature ensemble to improve the effect of image reconstruction. And our feature ensemble method enables the performance of the model to be considerably enhanced without increasing the training and testing time. We applied our algorithm on multiple popular large-scale benchmarks and achieved state-of-the-art performance comparing to the existing methods. For example, our SwinFIR achieves the PSNR of 32.83 dB on Manga109 dataset, which is 0.8 dB higher than the state-of-the-art SwinIR method.