 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCTR: Bidirectional Conditioning Transformer for Scene Graph Generation
Jul 26, 2024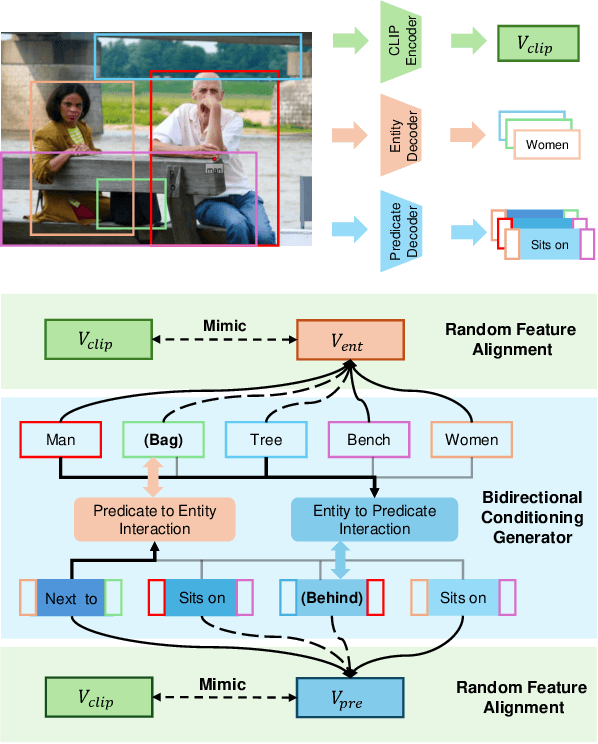
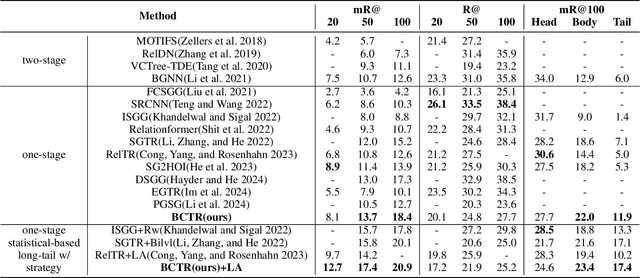
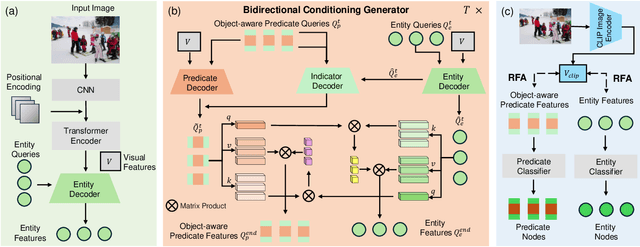
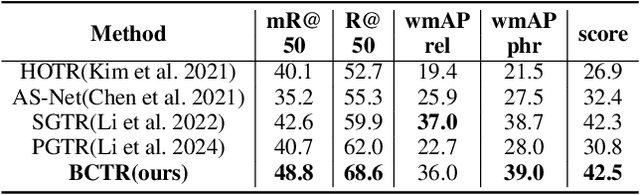
Scene Graph Generation (SGG) remains a challenging task due to its compositional property. Previous approaches improve prediction efficiency by learning in an end-to-end manner. However, these methods exhibit limited performance as they assume unidirectional conditioning between entities and predicates, leading to insufficient information interaction. To address this limitation, we propose a novel bidirectional conditioning factorization for SGG, introducing efficient interaction between entities and predicates. Specifically, we develop an end-to-end scene graph generation model, Bidirectional Conditioning Transformer (BCTR), to implement our factorization. BCTR consists of two key modules. First, the Bidirectional Conditioning Generator (BCG) facilitates multi-stage interactive feature augmentation between entities and predicates, enabling mutual benefits between the two predictions. Second, Random Feature Alignment (RFA) regularizes the feature space by distilling multi-modal knowledge from pre-trained models, enhancing BCTR's ability on tailed categories without relying on statistical priors. We conduct a series of experiments on Visual Genome and Open Image V6, demonstrating that BCTR achieves state-of-the-art performance on both benchmarks. The code will be available upon acceptance of the paper.
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Jul 09, 2024


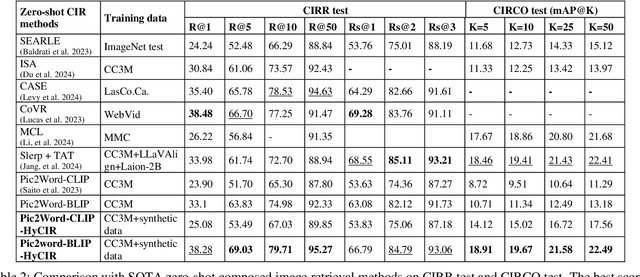
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
DMTNet: Dynamic Multi-scale Network for Dual-pixel Images Defocus Deblurring with Transformer
Sep 13, 2022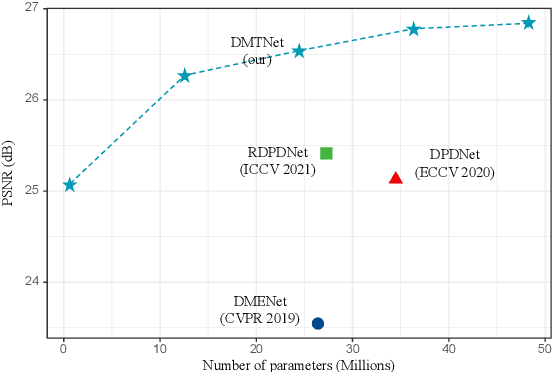



Recent works achieve excellent results in defocus deblurring task based on dual-pixel data using convolutional neural network (CNN), while the scarcity of data limits the exploration and attempt of vision transformer in this task. In addition, the existing works use fixed parameters and network architecture to deblur images with different distribution and content information, which also affects the generalization ability of the model. In this paper, we propose a dynamic multi-scale network, named DMTNet, for dual-pixel images defocus deblurring. DMTNet mainly contains two modules: feature extraction module and reconstruction module. The feature extraction module is composed of several vision transformer blocks, which uses its powerful feature extraction capability to obtain richer features and improve the robustness of the model. The reconstruction module is composed of several Dynamic Multi-scale Sub-reconstruction Module (DMSSRM). DMSSRM can restore images by adaptively assigning weights to features from different scales according to the blur distribution and content information of the input images. DMTNet combines the advantages of transformer and CNN, in which the vision transformer improves the performance ceiling of CNN, and the inductive bias of CNN enables transformer to extract more robust features without relying on a large amount of data. DMTNet might be the first attempt to use vision transformer to restore the blurring images to clarity. By combining with CNN, the vision transformer may achieve better performance on small datasets. Experimental results on the popular benchmarks demonstrate that our DMTNet significantly outperforms state-of-the-art methods.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022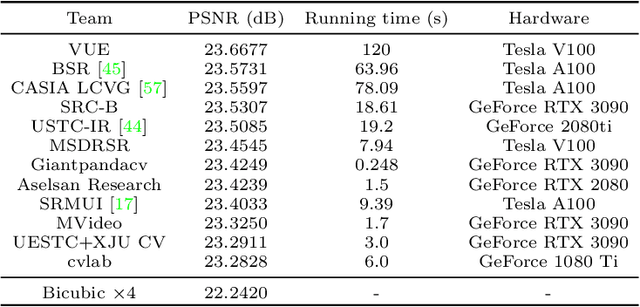
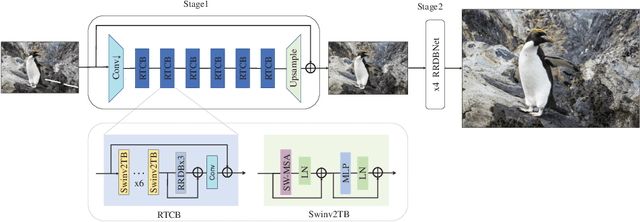

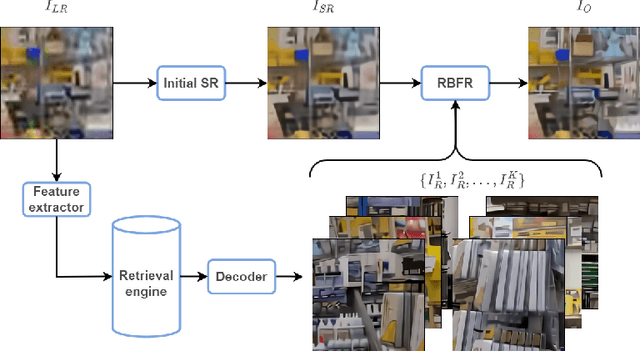
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
Aug 24, 2022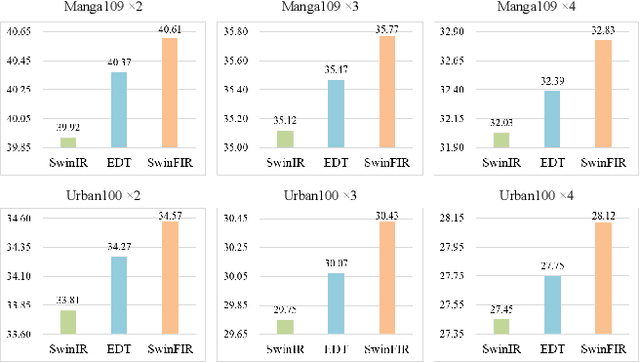
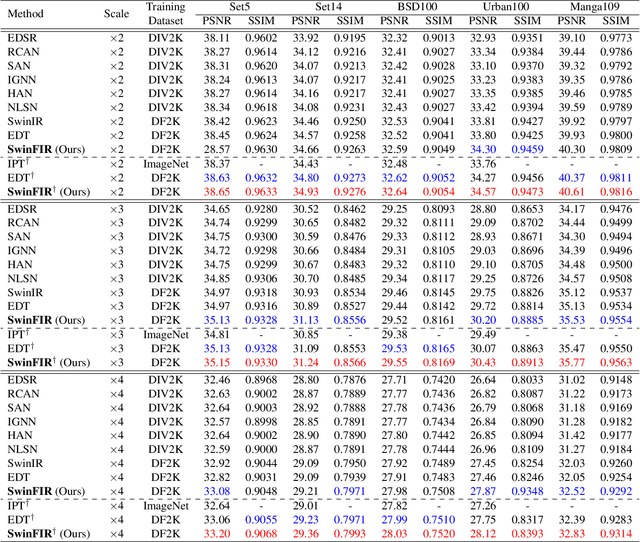

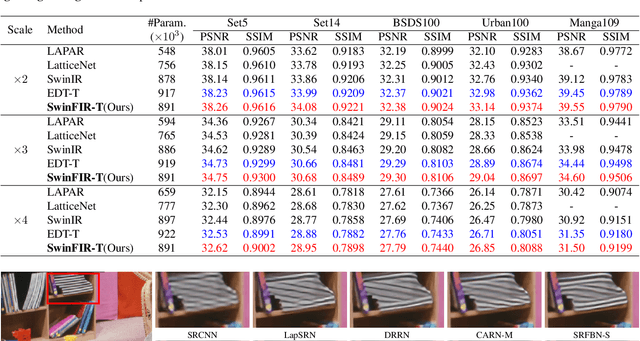
Transformer-based methods have achieved impressive image restoration performance due to their capacities to model long-range dependency compared to CNN-based methods. However, advances like SwinIR adopts the window-based and local attention strategy to balance the performance and computational overhead, which restricts employing large receptive fields to capture global information and establish long dependencies in the early layers. To further improve the efficiency of capturing global information, in this work, we propose SwinFIR to extend SwinIR by replacing Fast Fourier Convolution (FFC) components, which have the image-wide receptive field. We also revisit other advanced techniques, i.e, data augmentation, pre-training, and feature ensemble to improve the effect of image reconstruction. And our feature ensemble method enables the performance of the model to be considerably enhanced without increasing the training and testing time. We applied our algorithm on multiple popular large-scale benchmarks and achieved state-of-the-art performance comparing to the existing methods. For example, our SwinFIR achieves the PSNR of 32.83 dB on Manga109 dataset, which is 0.8 dB higher than the state-of-the-art SwinIR method.
Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
May 15, 2019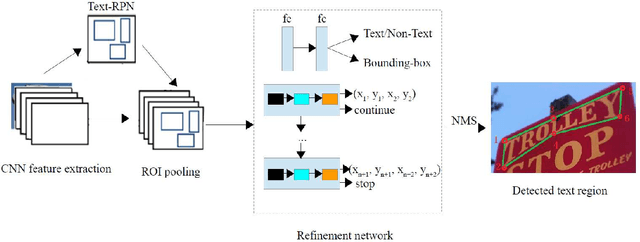
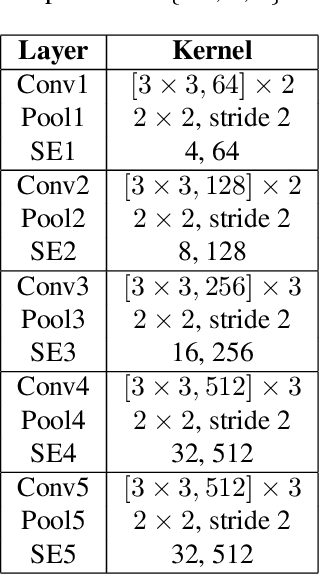

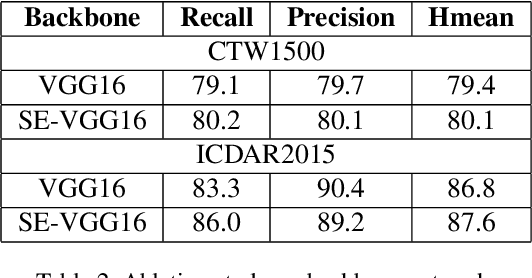
Scene text detection attracts much attention in computer vision, because it can be widely used in many applications such as real-time text translation, automatic information entry, blind person assistance, robot sensing and so on. Though many methods have been proposed for horizontal and oriented texts, detecting irregular shape texts such as curved texts is still a challenging problem. To solve the problem, we propose a robust scene text detection method with adaptive text region representation. Given an input image, a text region proposal network is first used for extracting text proposals. Then, these proposals are verified and refined with a refinement network. Here, recurrent neural network based adaptive text region representation is proposed for text region refinement, where a pair of boundary points are predicted each time step until no new points are found. In this way, text regions of arbitrary shapes are detected and represented with adaptive number of boundary points. This gives more accurate description of text regions. Experimental results on five benchmarks, namely, CTW1500, TotalText, ICDAR2013, ICDAR2015 and MSRATD500, show that the proposed method achieves state-of-the-art in scene text detection.
Deep Residual Text Detection Network for Scene Text
Nov 11, 2017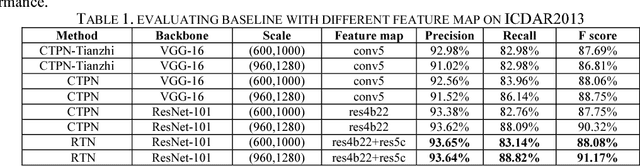

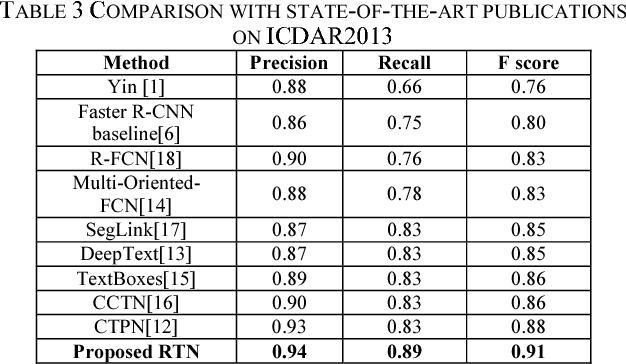
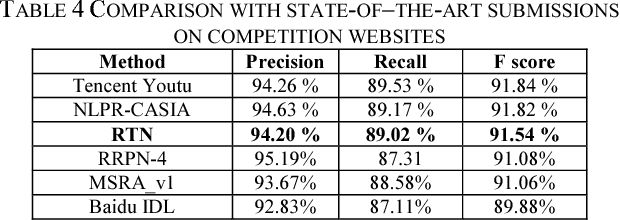
Scene text detection is a challenging problem in computer vision. In this paper, we propose a novel text detection network based on prevalent object detection frameworks. In order to obtain stronger semantic feature, we adopt ResNet as feature extraction layers and exploit multi-level feature by combining hierarchical convolutional networks. A vertical proposal mechanism is utilized to avoid proposal classification, while regression layer remains working to improve localization accuracy. Our approach evaluated on ICDAR2013 dataset achieves F-measure of 0.91, which outperforms previous state-of-the-art results in scene text detection.
R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
Jun 30, 2017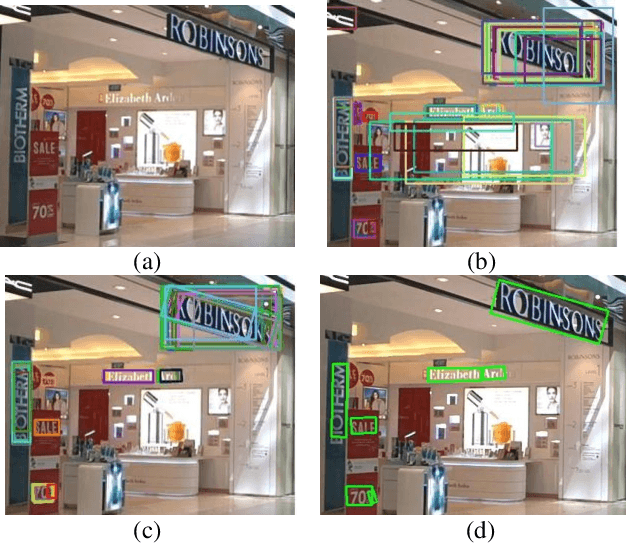
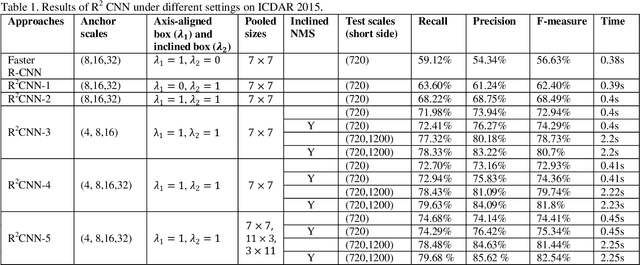

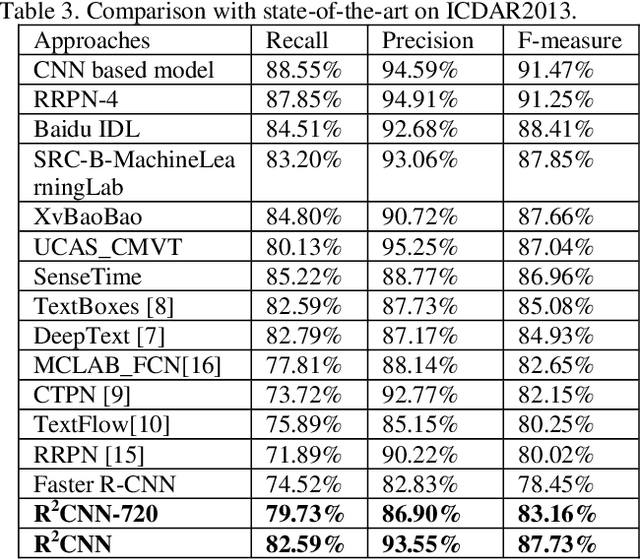
In this paper, we propose a novel method called Rotational Region CNN (R2CNN) for detecting arbitrary-oriented texts in natural scene images. The framework is based on Faster R-CNN [1] architecture. First, we use the Region Proposal Network (RPN) to generate axis-aligned bounding boxes that enclose the texts with different orientations. Second, for each axis-aligned text box proposed by RPN, we extract its pooled features with different pooled sizes and the concatenated features are used to simultaneously predict the text/non-text score, axis-aligned box and inclined minimum area box. At last, we use an inclined non-maximum suppression to get the detection results. Our approach achieves competitive results on text detection benchmarks: ICDAR 2015 and ICDAR 2013.