 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEF-MAP: Subspace-Decomposed Expert Fusion for Robust Multimodal HD Map Prediction
Feb 25, 2026High-definition (HD) maps are essential for autonomous driving, yet multi-modal fusion often suffers from inconsistency between camera and LiDAR modalities, leading to performance degradation under low-light conditions, occlusions, or sparse point clouds. To address this, we propose SEFMAP, a Subspace-Expert Fusion framework for robust multimodal HD map prediction. The key idea is to explicitly disentangle BEV features into four semantic subspaces: LiDAR-private, Image-private, Shared, and Interaction. Each subspace is assigned a dedicated expert, thereby preserving modality-specific cues while capturing cross-modal consensus. To adaptively combine expert outputs, we introduce an uncertainty-aware gating mechanism at the BEV-cell level, where unreliable experts are down-weighted based on predictive variance, complemented by a usage balance regularizer to prevent expert collapse. To enhance robustness in degraded conditions and promote role specialization, we further propose distribution-aware masking: during training, modality-drop scenarios are simulated using EMA-statistical surrogate features, and a specialization loss enforces distinct behaviors of private, shared, and interaction experts across complete and masked inputs. Experiments on nuScenes and Argoverse2 benchmarks demonstrate that SEFMAP achieves state-of-the-art performance, surpassing prior methods by +4.2% and +4.8% in mAP, respectively. SEF-MAPprovides a robust and effective solution for multi-modal HD map prediction under diverse and degraded conditions.
Perceptual Quality Optimization of Image Super-Resolution
Feb 25, 2026Single-image super-resolution (SR) has achieved remarkable progress with deep learning, yet most approaches rely on distortion-oriented losses or heuristic perceptual priors, which often lead to a trade-off between fidelity and visual quality. To address this issue, we propose an \textit{Efficient Perceptual Bi-directional Attention Network (Efficient-PBAN)} that explicitly optimizes SR towards human-preferred quality. Unlike patch-based quality models, Efficient-PBAN avoids extensive patch sampling and enables efficient image-level perception. The proposed framework is trained on our self-constructed SR quality dataset that covers a wide range of state-of-the-art SR methods with corresponding human opinion scores. Using this dataset, Efficient-PBAN learns to predict perceptual quality in a way that correlates strongly with subjective judgments. The learned metric is further integrated into SR training as a differentiable perceptual loss, enabling closed-loop alignment between reconstruction and perceptual assessment. Extensive experiments demonstrate that our approach delivers superior perceptual quality. Code is publicly available at https://github.com/Lighting-YXLI/Efficient-PBAN.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
DriveWorld-VLA: Unified Latent-Space World Modeling with Vision-Language-Action for Autonomous Driving
Feb 06, 2026End-to-end (E2E) autonomous driving has recently attracted increasing interest in unifying Vision-Language-Action (VLA) with World Models to enhance decision-making and forward-looking imagination. However, existing methods fail to effectively unify future scene evolution and action planning within a single architecture due to inadequate sharing of latent states, limiting the impact of visual imagination on action decisions. To address this limitation, we propose DriveWorld-VLA, a novel framework that unifies world modeling and planning within a latent space by tightly integrating VLA and world models at the representation level, which enables the VLA planner to benefit directly from holistic scene-evolution modeling and reducing reliance on dense annotated supervision. Additionally, DriveWorld-VLA incorporates the latent states of the world model as core decision-making states for the VLA planner, facilitating the planner to assess how candidate actions impact future scene evolution. By conducting world modeling entirely in the latent space, DriveWorld-VLA supports controllable, action-conditioned imagination at the feature level, avoiding expensive pixel-level rollouts. Extensive open-loop and closed-loop evaluations demonstrate the effectiveness of DriveWorld-VLA, which achieves state-of-the-art performance with 91.3 PDMS on NAVSIMv1, 86.8 EPDMS on NAVSIMv2, and 0.16 3-second average collision rate on nuScenes. Code and models will be released in https://github.com/liulin815/DriveWorld-VLA.git.
EXaMCaP: Subset Selection with Entropy Gain Maximization for Probing Capability Gains of Large Chart Understanding Training Sets
Feb 04, 2026Recent works focus on synthesizing Chart Understanding (ChartU) training sets to inject advanced chart knowledge into Multimodal Large Language Models (MLLMs), where the sufficiency of the knowledge is typically verified by quantifying capability gains via the fine-tune-then-evaluate paradigm. However, full-set fine-tuning MLLMs to assess such gains incurs significant time costs, hindering the iterative refinement cycles of the ChartU dataset. Reviewing the ChartU dataset synthesis and data selection domains, we find that subsets can potentially probe the MLLMs' capability gains from full-set fine-tuning. Given that data diversity is vital for boosting MLLMs' performance and entropy reflects this feature, we propose EXaMCaP, which uses entropy gain maximization to select a subset. To obtain a high-diversity subset, EXaMCaP chooses the maximum-entropy subset from the large ChartU dataset. As enumerating all possible subsets is impractical, EXaMCaP iteratively selects samples to maximize the gain in set entropy relative to the current set, approximating the maximum-entropy subset of the full dataset. Experiments show that EXaMCaP outperforms baselines in probing the capability gains of the ChartU training set, along with its strong effectiveness across diverse subset sizes and compatibility with various MLLM architectures.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
Is Your VLM for Autonomous Driving Safety-Ready? A Comprehensive Benchmark for Evaluating External and In-Cabin Risks
Nov 19, 2025Vision-Language Models (VLMs) show great promise for autonomous driving, but their suitability for safety-critical scenarios is largely unexplored, raising safety concerns. This issue arises from the lack of comprehensive benchmarks that assess both external environmental risks and in-cabin driving behavior safety simultaneously. To bridge this critical gap, we introduce DSBench, the first comprehensive Driving Safety Benchmark designed to assess a VLM's awareness of various safety risks in a unified manner. DSBench encompasses two major categories: external environmental risks and in-cabin driving behavior safety, divided into 10 key categories and a total of 28 sub-categories. This comprehensive evaluation covers a wide range of scenarios, ensuring a thorough assessment of VLMs' performance in safety-critical contexts. Extensive evaluations across various mainstream open-source and closed-source VLMs reveal significant performance degradation under complex safety-critical situations, highlighting urgent safety concerns. To address this, we constructed a large dataset of 98K instances focused on in-cabin and external safety scenarios, showing that fine-tuning on this dataset significantly enhances the safety performance of existing VLMs and paves the way for advancing autonomous driving technology. The benchmark toolkit, code, and model checkpoints will be publicly accessible.
SocialNav-Map: Dynamic Mapping with Human Trajectory Prediction for Zero-Shot Social Navigation
Nov 18, 2025Social navigation in densely populated dynamic environments poses a significant challenge for autonomous mobile robots, requiring advanced strategies for safe interaction. Existing reinforcement learning (RL)-based methods require over 2000+ hours of extensive training and often struggle to generalize to unfamiliar environments without additional fine-tuning, limiting their practical application in real-world scenarios. To address these limitations, we propose SocialNav-Map, a novel zero-shot social navigation framework that combines dynamic human trajectory prediction with occupancy mapping, enabling safe and efficient navigation without the need for environment-specific training. Specifically, SocialNav-Map first transforms the task goal position into the constructed map coordinate system. Subsequently, it creates a dynamic occupancy map that incorporates predicted human movements as dynamic obstacles. The framework employs two complementary methods for human trajectory prediction: history prediction and orientation prediction. By integrating these predicted trajectories into the occupancy map, the robot can proactively avoid potential collisions with humans while efficiently navigating to its destination. Extensive experiments on the Social-HM3D and Social-MP3D datasets demonstrate that SocialNav-Map significantly outperforms state-of-the-art (SOTA) RL-based methods, which require 2,396 GPU hours of training. Notably, it reduces human collision rates by over 10% without necessitating any training in novel environments. By eliminating the need for environment-specific training, SocialNav-Map achieves superior navigation performance, paving the way for the deployment of social navigation systems in real-world environments characterized by diverse human behaviors. The code is available at: https://github.com/linglingxiansen/SocialNav-Map.
Is your VLM Sky-Ready? A Comprehensive Spatial Intelligence Benchmark for UAV Navigation
Nov 17, 2025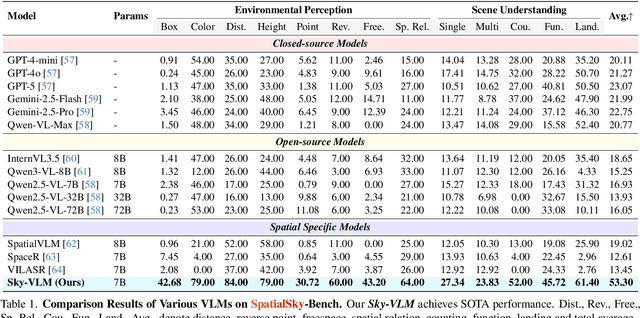
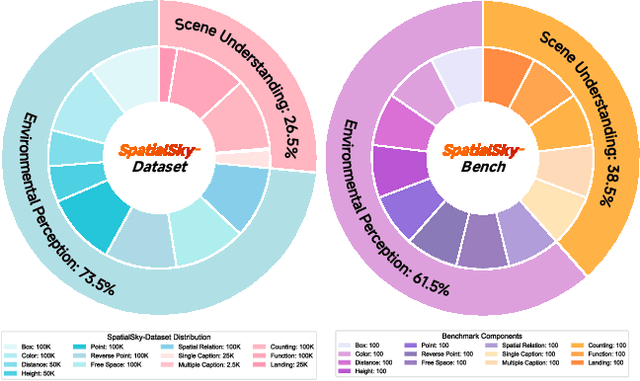
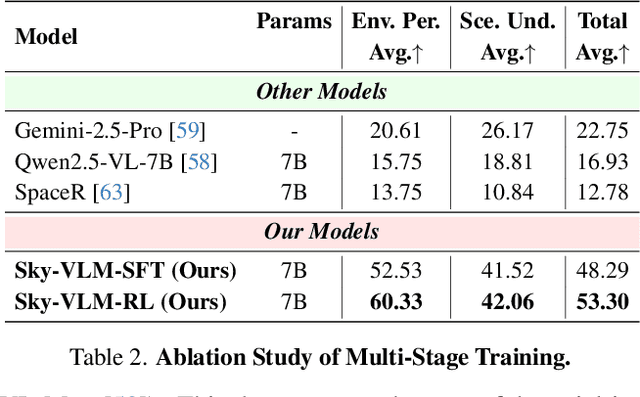
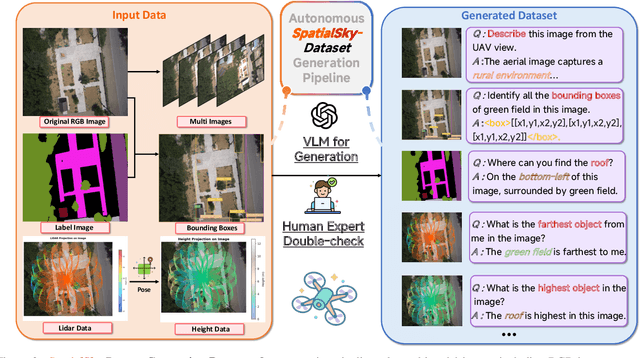
Vision-Language Models (VLMs), leveraging their powerful visual perception and reasoning capabilities, have been widely applied in Unmanned Aerial Vehicle (UAV) tasks. However, the spatial intelligence capabilities of existing VLMs in UAV scenarios remain largely unexplored, raising concerns about their effectiveness in navigating and interpreting dynamic environments. To bridge this gap, we introduce SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation. Our benchmark comprises two categories-Environmental Perception and Scene Understanding-divided into 13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others. Extensive evaluations of various mainstream open-source and closed-source VLMs reveal unsatisfactory performance in complex UAV navigation scenarios, highlighting significant gaps in their spatial capabilities. To address this challenge, we developed the SpatialSky-Dataset, a comprehensive dataset containing 1M samples with diverse annotations across various scenarios. Leveraging this dataset, we introduce Sky-VLM, a specialized VLM designed for UAV spatial reasoning across multiple granularities and contexts. Extensive experimental results demonstrate that Sky-VLM achieves state-of-the-art performance across all benchmark tasks, paving the way for the development of VLMs suitable for UAV scenarios. The source code is available at https://github.com/linglingxiansen/SpatialSKy.