 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-CLTP: Fine-Grained Contrastive Language Tactile Pretraining for Robotic Manipulation
Mar 11, 2026Recent advancements in integrating tactile sensing into vision-language-action (VLA) models have demonstrated transformative potential for robotic perception. However, existing tactile representations predominantly rely on qualitative descriptors (e.g., texture), neglecting quantitative contact states such as force magnitude, contact geometry, and principal axis orientation, which are indispensable for fine-grained manipulation. To bridge this gap, we propose FG-CLTP, a fine-grained contrastive language tactile pretraining framework. We first introduce a novel dataset comprising over 100k tactile 3D point cloud-language pairs that explicitly capture multidimensional contact states from the sensor's perspective. We then implement a discretized numerical tokenization mechanism to achieve quantitative-semantic alignment, effectively injecting explicit physical metrics into the multimodal feature space. The proposed FG-CLTP model yields a 95.9% classification accuracy and reduces the regression error (MAE) by 52.6% compared to state-of-the-art methods. Furthermore, the integration of 3D point cloud representations establishes a sensor-agnostic foundation with a minimal sim-to-real gap of 3.5%. Building upon this fine-grained representation, we develop a 3D tactile-language-action (3D-TLA) architecture driven by a flow matching policy to enable multimodal reasoning and control. Extensive experiments demonstrate that our framework significantly outperforms strong baselines in contact-rich manipulation tasks, providing a robust and generalizable foundation for tactile-language-action models.
SpikingTac: A Miniaturized Neuromorphic Visuotactile Sensor for High-Precision Dynamic Tactile Imprint Tracking
Feb 27, 2026High-speed event-driven tactile sensors are essential for achieving human-like dynamic manipulation, yet their integration is often limited by the bulkiness of standard event cameras. This paper presents SpikingTac, a miniaturized, highly integrated neuromorphic tactile sensor featuring a custom standalone event camera module, achieved with a total material cost of less than \$150. We construct a global dynamic state map coupled with an unsupervised denoising network to enable precise tracking at a 1000~Hz perception rate and 350~Hz tracking frequency. Addressing the viscoelastic hysteresis of silicone elastomers, we propose a hysteresis-aware incremental update law with a spatial gain damping mechanism. Experimental results demonstrate exceptional zero-point stability, achieving a 100\% return-to-origin success rate with a minimal mean bias of 0.8039 pixels, even under extreme torsional deformations. In dynamic tasks, SpikingTac limits the obstacle-avoidance overshoot to 6.2~mm, representing a 5-fold performance improvement over conventional frame-based sensors. Furthermore, the sensor achieves sub-millimeter geometric accuracy, with Root Mean Square Error (RMSE) of 0.0952~mm in localization and 0.0452~mm in radius measurement.
AnyTouch 2: General Optical Tactile Representation Learning For Dynamic Tactile Perception
Feb 10, 2026Real-world contact-rich manipulation demands robots to perceive temporal tactile feedback, capture subtle surface deformations, and reason about object properties as well as force dynamics. Although optical tactile sensors are uniquely capable of providing such rich information, existing tactile datasets and models remain limited. These resources primarily focus on object-level attributes (e.g., material) while largely overlooking fine-grained tactile temporal dynamics during physical interactions. We consider that advancing dynamic tactile perception requires a systematic hierarchy of dynamic perception capabilities to guide both data collection and model design. To address the lack of tactile data with rich dynamic information, we present ToucHD, a large-scale hierarchical tactile dataset spanning tactile atomic actions, real-world manipulations, and touch-force paired data. Beyond scale, ToucHD establishes a comprehensive tactile dynamic data ecosystem that explicitly supports hierarchical perception capabilities from the data perspective. Building on it, we propose AnyTouch 2, a general tactile representation learning framework for diverse optical tactile sensors that unifies object-level understanding with fine-grained, force-aware dynamic perception. The framework captures both pixel-level and action-specific deformations across frames, while explicitly modeling physical force dynamics, thereby learning multi-level dynamic perception capabilities from the model perspective. We evaluate our model on benchmarks that covers static object properties and dynamic physical attributes, as well as real-world manipulation tasks spanning multiple tiers of dynamic perception capabilities-from basic object-level understanding to force-aware dexterous manipulation. Experimental results demonstrate consistent and strong performance across sensors and tasks.
DexTac: Learning Contact-aware Visuotactile Policies via Hand-by-hand Teaching
Jan 29, 2026For contact-intensive tasks, the ability to generate policies that produce comprehensive tactile-aware motions is essential. However, existing data collection and skill learning systems for dexterous manipulation often suffer from low-dimensional tactile information. To address this limitation, we propose DexTac, a visuo-tactile manipulation learning framework based on kinesthetic teaching. DexTac captures multi-dimensional tactile data-including contact force distributions and spatial contact regions-directly from human demonstrations. By integrating these rich tactile modalities into a policy network, the resulting contact-aware agent enables a dexterous hand to autonomously select and maintain optimal contact regions during complex interactions. We evaluate our framework on a challenging unimanual injection task. Experimental results demonstrate that DexTac achieves a 91.67% success rate. Notably, in high-precision scenarios involving small-scale syringes, our approach outperforms force-only baselines by 31.67%. These results underscore that learning multi-dimensional tactile priors from human demonstrations is critical for achieving robust, human-like dexterous manipulation in contact-rich environments.
Trajectory Optimization for UAV-Based Medical Delivery with Temporal Logic Constraints and Convex Feasible Set Collision Avoidance
Jun 06, 2025This paper addresses the problem of trajectory optimization for unmanned aerial vehicles (UAVs) performing time-sensitive medical deliveries in urban environments. Specifically, we consider a single UAV with 3 degree-of-freedom dynamics tasked with delivering blood packages to multiple hospitals, each with a predefined time window and priority. Mission objectives are encoded using Signal Temporal Logic (STL), enabling the formal specification of spatial-temporal constraints. To ensure safety, city buildings are modeled as 3D convex obstacles, and obstacle avoidance is handled through a Convex Feasible Set (CFS) method. The entire planning problem-combining UAV dynamics, STL satisfaction, and collision avoidance-is formulated as a convex optimization problem that ensures tractability and can be solved efficiently using standard convex programming techniques. Simulation results demonstrate that the proposed method generates dynamically feasible, collision-free trajectories that satisfy temporal mission goals, providing a scalable and reliable approach for autonomous UAV-based medical logistics.
VTLA: Vision-Tactile-Language-Action Model with Preference Learning for Insertion Manipulation
May 14, 2025
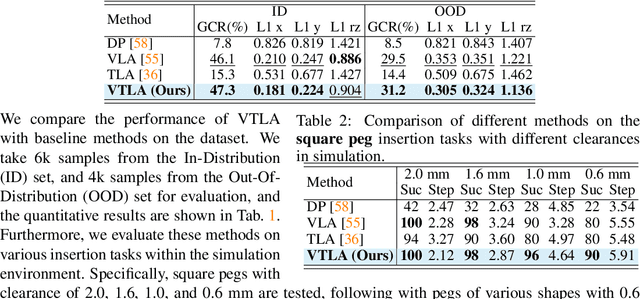


While vision-language models have advanced significantly, their application in language-conditioned robotic manipulation is still underexplored, especially for contact-rich tasks that extend beyond visually dominant pick-and-place scenarios. To bridge this gap, we introduce Vision-Tactile-Language-Action model, a novel framework that enables robust policy generation in contact-intensive scenarios by effectively integrating visual and tactile inputs through cross-modal language grounding. A low-cost, multi-modal dataset has been constructed in a simulation environment, containing vision-tactile-action-instruction pairs specifically designed for the fingertip insertion task. Furthermore, we introduce Direct Preference Optimization (DPO) to offer regression-like supervision for the VTLA model, effectively bridging the gap between classification-based next token prediction loss and continuous robotic tasks. Experimental results show that the VTLA model outperforms traditional imitation learning methods (e.g., diffusion policies) and existing multi-modal baselines (TLA/VLA), achieving over 90% success rates on unseen peg shapes. Finally, we conduct real-world peg-in-hole experiments to demonstrate the exceptional Sim2Real performance of the proposed VTLA model. For supplementary videos and results, please visit our project website: https://sites.google.com/view/vtla
CLTP: Contrastive Language-Tactile Pre-training for 3D Contact Geometry Understanding
May 13, 2025Recent advancements in integrating tactile sensing with vision-language models (VLMs) have demonstrated remarkable potential for robotic multimodal perception. However, existing tactile descriptions remain limited to superficial attributes like texture, neglecting critical contact states essential for robotic manipulation. To bridge this gap, we propose CLTP, an intuitive and effective language tactile pretraining framework that aligns tactile 3D point clouds with natural language in various contact scenarios, thus enabling contact-state-aware tactile language understanding for contact-rich manipulation tasks. We first collect a novel dataset of 50k+ tactile 3D point cloud-language pairs, where descriptions explicitly capture multidimensional contact states (e.g., contact location, shape, and force) from the tactile sensor's perspective. CLTP leverages a pre-aligned and frozen vision-language feature space to bridge holistic textual and tactile modalities. Experiments validate its superiority in three downstream tasks: zero-shot 3D classification, contact state classification, and tactile 3D large language model (LLM) interaction. To the best of our knowledge, this is the first study to align tactile and language representations from the contact state perspective for manipulation tasks, providing great potential for tactile-language-action model learning. Code and datasets are open-sourced at https://sites.google.com/view/cltp/.
TLA: Tactile-Language-Action Model for Contact-Rich Manipulation
Mar 11, 2025Significant progress has been made in vision-language models. However, language-conditioned robotic manipulation for contact-rich tasks remains underexplored, particularly in terms of tactile sensing. To address this gap, we introduce the Tactile-Language-Action (TLA) model, which effectively processes sequential tactile feedback via cross-modal language grounding to enable robust policy generation in contact-intensive scenarios. In addition, we construct a comprehensive dataset that contains 24k pairs of tactile action instruction data, customized for fingertip peg-in-hole assembly, providing essential resources for TLA training and evaluation. Our results show that TLA significantly outperforms traditional imitation learning methods (e.g., diffusion policy) in terms of effective action generation and action accuracy, while demonstrating strong generalization capabilities by achieving over 85\% success rate on previously unseen assembly clearances and peg shapes. We publicly release all data and code in the hope of advancing research in language-conditioned tactile manipulation skill learning. Project website: https://sites.google.com/view/tactile-language-action/
Real-Time Marker Localization Learning for GelStereo Tactile Sensing
Nov 24, 2022
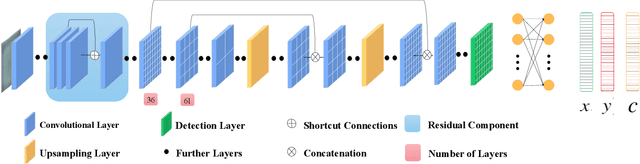
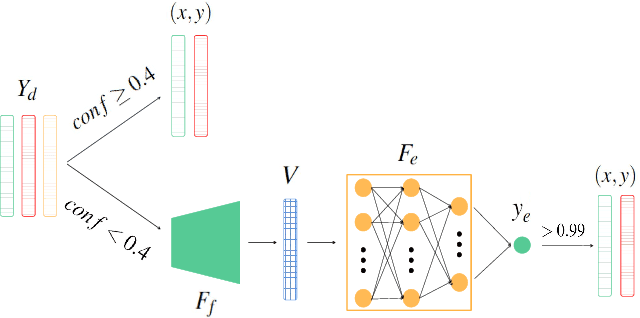
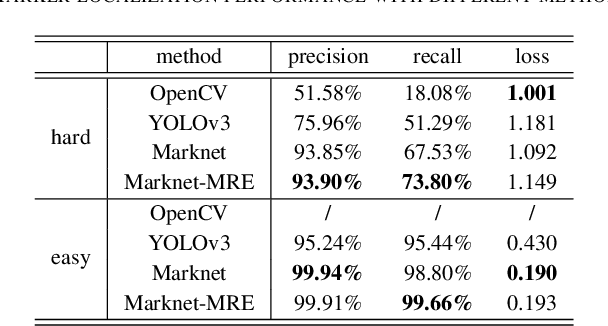
Visuotactile sensing technology is becoming more popular in tactile sensing, but the effectiveness of the existing marker detection localization methods remains to be further explored. Instead of contour-based blob detection, this paper presents a learning-based marker localization network for GelStereo visuotactile sensing called Marknet. Specifically, the Marknet presents a grid regression architecture to incorporate the distribution of the GelStereo markers. Furthermore, a marker rationality evaluator (MRE) is modelled to screen suitable prediction results. The experimental results show that the Marknet combined with MRE achieves 93.90% precision for irregular markers in contact areas, which outperforms the traditional contour-based blob detection method by a large margin of 42.32%. Meanwhile, the proposed learning-based marker localization method can achieve better real-time performance beyond the blob detection interface provided by the OpenCV library through GPU acceleration, which we believe will lead to considerable perceptual sensitivity gains in various robotic manipulation tasks.
Grasp State Assessment of Deformable Objects Using Visual-Tactile Fusion Perception
Jun 23, 2020

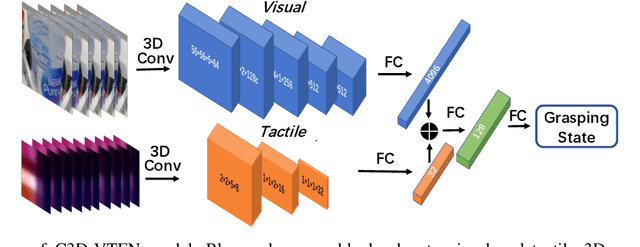

Humans can quickly determine the force required to grasp a deformable object to prevent its sliding or excessive deformation through vision and touch, which is still a challenging task for robots. To address this issue, we propose a novel 3D convolution-based visual-tactile fusion deep neural network (C3D-VTFN) to evaluate the grasp state of various deformable objects in this paper. Specifically, we divide the grasp states of deformable objects into three categories of sliding, appropriate and excessive. Also, a dataset for training and testing the proposed network is built by extensive grasping and lifting experiments with different widths and forces on 16 various deformable objects with a robotic arm equipped with a wrist camera and a tactile sensor. As a result, a classification accuracy as high as 99.97% is achieved. Furthermore, some delicate grasp experiments based on the proposed network are implemented in this paper. The experimental results demonstrate that the C3D-VTFN is accurate and efficient enough for grasp state assessment, which can be widely applied to automatic force control, adaptive grasping, and other visual-tactile spatiotemporal sequence learning problems.