 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Jun 05, 2024



In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
MEGA: A Memory-Efficient GNN Accelerator Exploiting Degree-Aware Mixed-Precision Quantization
Nov 16, 2023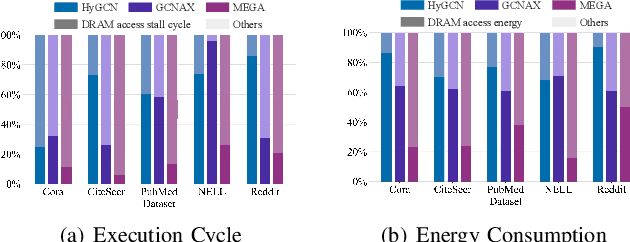
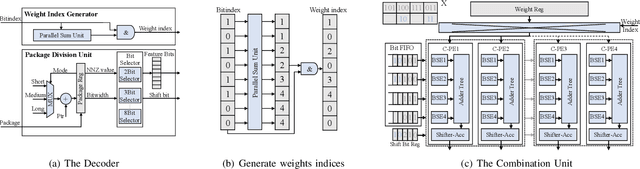
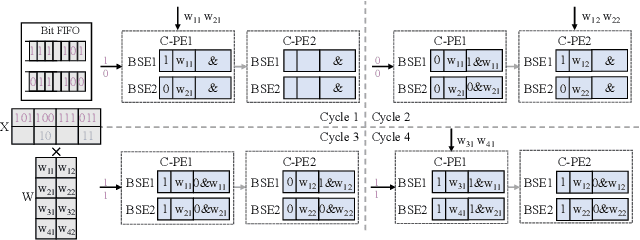

Graph Neural Networks (GNNs) are becoming a promising technique in various domains due to their excellent capabilities in modeling non-Euclidean data. Although a spectrum of accelerators has been proposed to accelerate the inference of GNNs, our analysis demonstrates that the latency and energy consumption induced by DRAM access still significantly impedes the improvement of performance and energy efficiency. To address this issue, we propose a Memory-Efficient GNN Accelerator (MEGA) through algorithm and hardware co-design in this work. Specifically, at the algorithm level, through an in-depth analysis of the node property, we observe that the data-independent quantization in previous works is not optimal in terms of accuracy and memory efficiency. This motivates us to propose the Degree-Aware mixed-precision quantization method, in which a proper bitwidth is learned and allocated to a node according to its in-degree to compress GNNs as much as possible while maintaining accuracy. At the hardware level, we employ a heterogeneous architecture design in which the aggregation and combination phases are implemented separately with different dataflows. In order to boost the performance and energy efficiency, we also present an Adaptive-Package format to alleviate the storage overhead caused by the fine-grained bitwidth and diverse sparsity, and a Condense-Edge scheduling method to enhance the data locality and further alleviate the access irregularity induced by the extremely sparse adjacency matrix in the graph. We implement our MEGA accelerator in a 28nm technology node. Extensive experiments demonstrate that MEGA can achieve an average speedup of 38.3x, 7.1x, 4.0x, 3.6x and 47.6x, 7.2x, 5.4x, 4.5x energy savings over four state-of-the-art GNN accelerators, HyGCN, GCNAX, GROW, and SGCN, respectively, while retaining task accuracy.
$\rm A^2Q$: Aggregation-Aware Quantization for Graph Neural Networks
Feb 01, 2023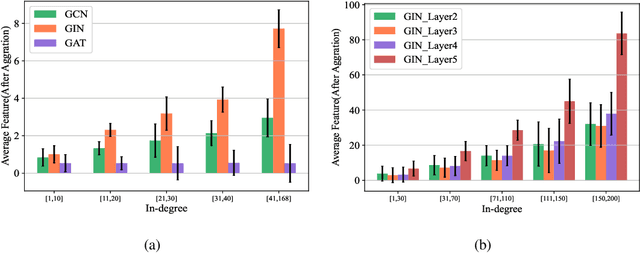

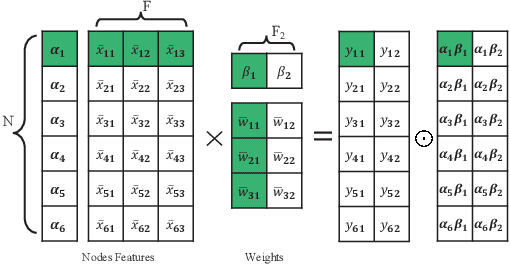
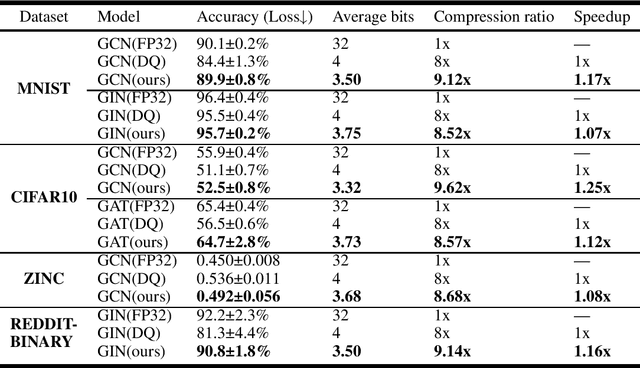
As graph data size increases, the vast latency and memory consumption during inference pose a significant challenge to the real-world deployment of Graph Neural Networks (GNNs). While quantization is a powerful approach to reducing GNNs complexity, most previous works on GNNs quantization fail to exploit the unique characteristics of GNNs, suffering from severe accuracy degradation. Through an in-depth analysis of the topology of GNNs, we observe that the topology of the graph leads to significant differences between nodes, and most of the nodes in a graph appear to have a small aggregation value. Motivated by this, in this paper, we propose the Aggregation-Aware mixed-precision Quantization ($\rm A^2Q$) for GNNs, where an appropriate bitwidth is automatically learned and assigned to each node in the graph. To mitigate the vanishing gradient problem caused by sparse connections between nodes, we propose a Local Gradient method to serve the quantization error of the node features as the supervision during training. We also develop a Nearest Neighbor Strategy to deal with the generalization on unseen graphs. Extensive experiments on eight public node-level and graph-level datasets demonstrate the generality and robustness of our proposed method. Compared to the FP32 models, our method can achieve up to a 18.6x (i.e., 1.70bit) compression ratio with negligible accuracy degradation. Morever, compared to the state-of-the-art quantization method, our method can achieve up to 11.4\% and 9.5\% accuracy improvements on the node-level and graph-level tasks, respectively, and up to 2x speedup on a dedicated hardware accelerator.
GLIF: A Unified Gated Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
Nov 03, 2022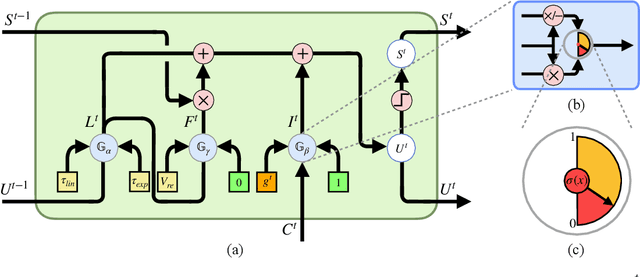
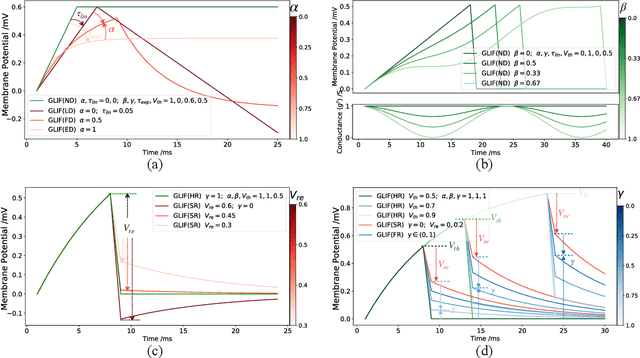
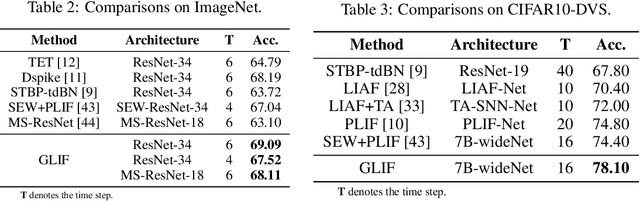
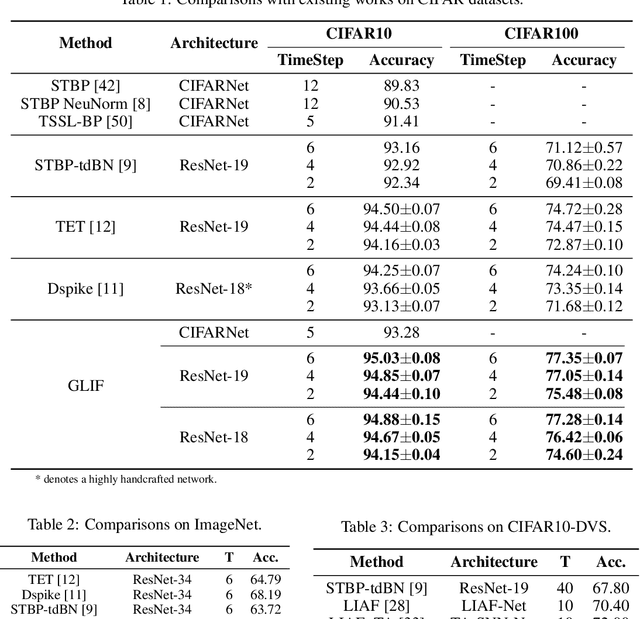
Spiking Neural Networks (SNNs) have been studied over decades to incorporate their biological plausibility and leverage their promising energy efficiency. Throughout existing SNNs, the leaky integrate-and-fire (LIF) model is commonly adopted to formulate the spiking neuron and evolves into numerous variants with different biological features. However, most LIF-based neurons support only single biological feature in different neuronal behaviors, limiting their expressiveness and neuronal dynamic diversity. In this paper, we propose GLIF, a unified spiking neuron, to fuse different bio-features in different neuronal behaviors, enlarging the representation space of spiking neurons. In GLIF, gating factors, which are exploited to determine the proportion of the fused bio-features, are learnable during training. Combining all learnable membrane-related parameters, our method can make spiking neurons different and constantly changing, thus increasing the heterogeneity and adaptivity of spiking neurons. Extensive experiments on a variety of datasets demonstrate that our method obtains superior performance compared with other SNNs by simply changing their neuronal formulations to GLIF. In particular, we train a spiking ResNet-19 with GLIF and achieve $77.35\%$ top-1 accuracy with six time steps on CIFAR-100, which has advanced the state-of-the-art. Codes are available at \url{https://github.com/Ikarosy/Gated-LIF}.
Grasp State Assessment of Deformable Objects Using Visual-Tactile Fusion Perception
Jun 23, 2020

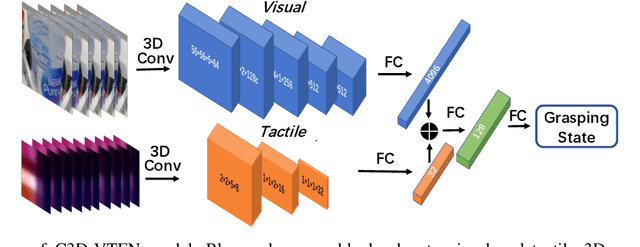

Humans can quickly determine the force required to grasp a deformable object to prevent its sliding or excessive deformation through vision and touch, which is still a challenging task for robots. To address this issue, we propose a novel 3D convolution-based visual-tactile fusion deep neural network (C3D-VTFN) to evaluate the grasp state of various deformable objects in this paper. Specifically, we divide the grasp states of deformable objects into three categories of sliding, appropriate and excessive. Also, a dataset for training and testing the proposed network is built by extensive grasping and lifting experiments with different widths and forces on 16 various deformable objects with a robotic arm equipped with a wrist camera and a tactile sensor. As a result, a classification accuracy as high as 99.97% is achieved. Furthermore, some delicate grasp experiments based on the proposed network are implemented in this paper. The experimental results demonstrate that the C3D-VTFN is accurate and efficient enough for grasp state assessment, which can be widely applied to automatic force control, adaptive grasping, and other visual-tactile spatiotemporal sequence learning problems.
A System-Level Solution for Low-Power Object Detection
Oct 19, 2019
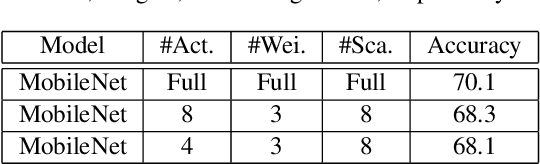
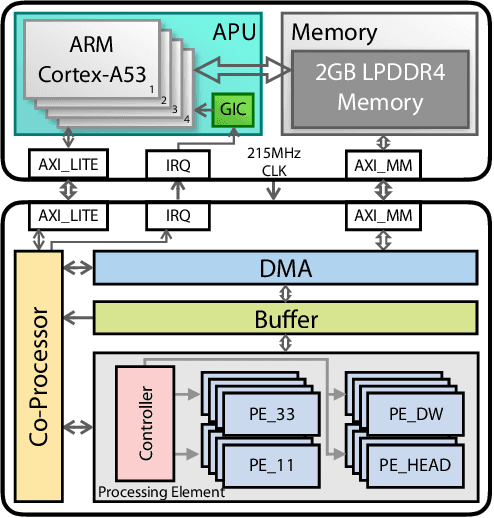

Object detection has made impressive progress in recent years with the help of deep learning. However, state-of-the-art algorithms are both computation and memory intensive. Though many lightweight networks are developed for a trade-off between accuracy and efficiency, it is still a challenge to make it practical on an embedded device. In this paper, we present a system-level solution for efficient object detection on a heterogeneous embedded device. The detection network is quantized to low bits and allows efficient implementation with shift operators. In order to make the most of the benefits of low-bit quantization, we design a dedicated accelerator with programmable logic. Inside the accelerator, a hybrid dataflow is exploited according to the heterogeneous property of different convolutional layers. We adopt a straightforward but resource-friendly column-prior tiling strategy to map the computation-intensive convolutional layers to the accelerator that can support arbitrary feature size. Other operations can be performed on the low-power CPU cores, and the entire system is executed in a pipelined manner. As a case study, we evaluate our object detection system on a real-world surveillance video with input size of 512x512, and it turns out that the system can achieve an inference speed of 18 fps at the cost of 6.9W (with display) with an mAP of 66.4 verified on the PASCAL VOC 2012 dataset.