 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVLW-DETR: Open-Vocabulary Light-Weighted Detection Transformer
Jul 15, 2024

Open-vocabulary object detection focusing on detecting novel categories guided by natural language. In this report, we propose Open-Vocabulary Light-Weighted Detection Transformer (OVLW-DETR), a deployment friendly open-vocabulary detector with strong performance and low latency. Building upon OVLW-DETR, we provide an end-to-end training recipe that transferring knowledge from vision-language model (VLM) to object detector with simple alignment. We align detector with the text encoder from VLM by replacing the fixed classification layer weights in detector with the class-name embeddings extracted from the text encoder. Without additional fusing module, OVLW-DETR is flexible and deployment friendly, making it easier to implement and modulate. improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time open-vocabulary detectors on standard Zero-Shot LVIS benchmark. Source code and pre-trained models are available at [https://github.com/Atten4Vis/LW-DETR].
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Jun 05, 2024



In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
Aug 14, 2023In this paper, we study the problem of end-to-end multi-person pose estimation. State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e.g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR. We present a simple yet effective transformer approach, named Group Pose. We simply regard $K$-keypoint pose estimation as predicting a set of $N\times K$ keypoint positions, each from a keypoint query, as well as representing each pose with an instance query for scoring $N$ pose predictions. Motivated by the intuition that the interaction, among across-instance queries of different types, is not directly helpful, we make a simple modification to decoder self-attention. We replace single self-attention over all the $N\times(K+1)$ queries with two subsequent group self-attentions: (i) $N$ within-instance self-attention, with each over $K$ keypoint queries and one instance query, and (ii) $(K+1)$ same-type across-instance self-attention, each over $N$ queries of the same type. The resulting decoder removes the interaction among across-instance type-different queries, easing the optimization and thus improving the performance. Experimental results on MS COCO and CrowdPose show that our approach without human box supervision is superior to previous methods with complex decoders, and even is slightly better than ED-Pose that uses human box supervision. $\href{https://github.com/Michel-liu/GroupPose-Paddle}{\rm Paddle}$ and $\href{https://github.com/Michel-liu/GroupPose}{\rm PyTorch}$ code are available.
PointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Jul 03, 2020
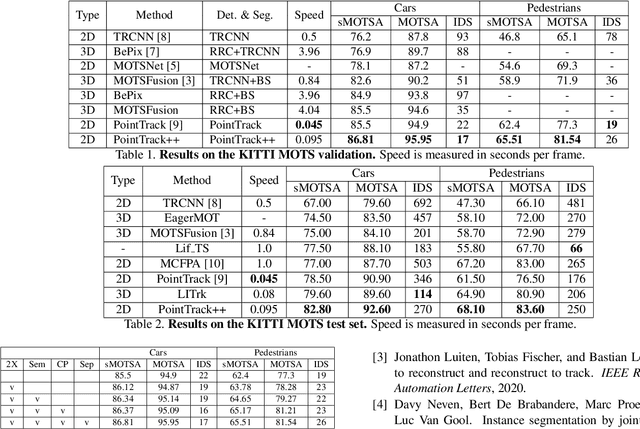
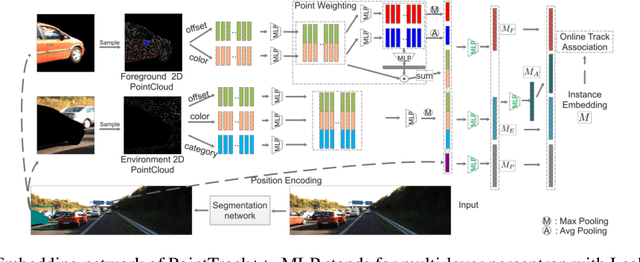
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.
One-Two-One Networks for Compression Artifacts Reduction in Remote Sensing
Apr 01, 2018

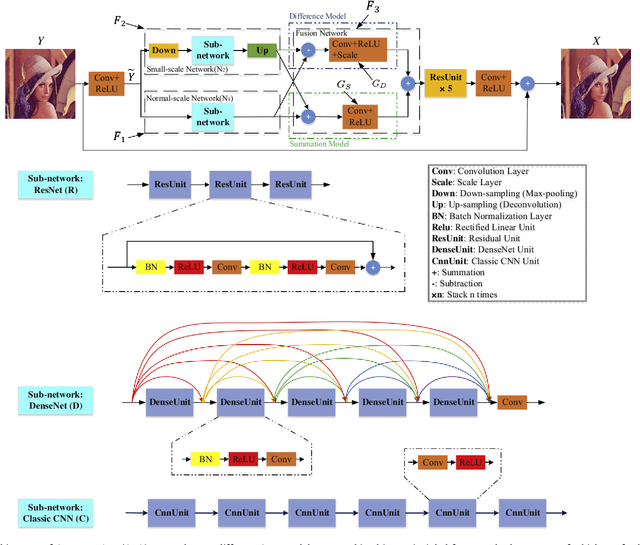
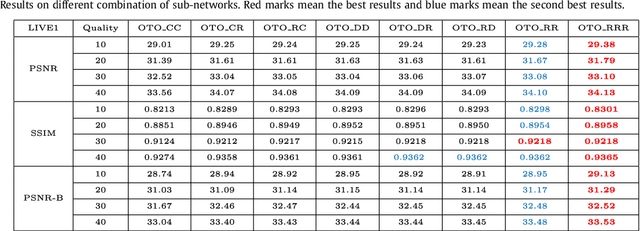
Compression artifacts reduction (CAR) is a challenging problem in the field of remote sensing. Most recent deep learning based methods have demonstrated superior performance over the previous hand-crafted methods. In this paper, we propose an end-to-end one-two-one (OTO) network, to combine different deep models, i.e., summation and difference models, to solve the CAR problem. Particularly, the difference model motivated by the Laplacian pyramid is designed to obtain the high frequency information, while the summation model aggregates the low frequency information. We provide an in-depth investigation into our OTO architecture based on the Taylor expansion, which shows that these two kinds of information can be fused in a nonlinear scheme to gain more capacity of handling complicated image compression artifacts, especially the blocking effect in compression. Extensive experiments are conducted to demonstrate the superior performance of the OTO networks, as compared to the state-of-the-arts on remote sensing datasets and other benchmark datasets.