 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
Mar 26, 2026Image restoration under real-world degradations is critical for downstream tasks such as autonomous driving and object detection. However, existing restoration models are often limited by the scale and distribution of their training data, resulting in poor generalization to real-world scenarios. Recently, large-scale image editing models have shown strong generalization ability in restoration tasks, especially for closed-source models like Nano Banana Pro, which can restore images while preserving consistency. Nevertheless, achieving such performance with those large universal models requires substantial data and computational costs. To address this issue, we construct a large-scale dataset covering nine common real-world degradation types and train a state-of-the-art open-source model to narrow the gap with closed-source alternatives. Furthermore, we introduce RealIR-Bench, which contains 464 real-world degraded images and tailored evaluation metrics focusing on degradation removal and consistency preservation. Extensive experiments demonstrate our model ranks first among open-source methods, achieving state-of-the-art performance.
MagicSeg: Open-World Segmentation Pretraining via Counterfactural Diffusion-Based Auto-Generation
Mar 20, 2026Open-world semantic segmentation presently relies significantly on extensive image-text pair datasets, which often suffer from a lack of fine-grained pixel annotations on sufficient categories. The acquisition of such data is rendered economically prohibitive due to the substantial investments of both human labor and time. In light of the formidable image generation capabilities of diffusion models, we introduce a novel diffusion model-driven pipeline for automatically generating datasets tailored to the needs of open-world semantic segmentation, named "MagicSeg". Our MagicSeg initiates from class labels and proceeds to generate high-fidelity textual descriptions, which in turn serve as guidance for the diffusion model to generate images. Rather than only generating positive samples for each label, our process encompasses the simultaneous generation of corresponding negative images, designed to serve as paired counterfactual samples for contrastive training. Then, to provide a self-supervised signal for open-world segmentation pretraining, our MagicSeg integrates an open-vocabulary detection model and an interactive segmentation model to extract object masks as precise segmentation labels from images based on the provided category labels. By applying our dataset to the contrastive language-image pretraining model with the pseudo mask supervision and the auxiliary counterfactual contrastive training, the downstream model obtains strong performance on open-world semantic segmentation. We evaluate our model on PASCAL VOC, PASCAL Context, and COCO, achieving SOTA with performance of 62.9%, 26.7%, and 40.2%, respectively, demonstrating our dataset's effectiveness in enhancing open-world semantic segmentation capabilities. Project website: https://github.com/ckxhp/magicseg.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
TARA: Token-Aware LoRA for Composable Personalization in Diffusion Models
Aug 12, 2025Personalized text-to-image generation aims to synthesize novel images of a specific subject or style using only a few reference images. Recent methods based on Low-Rank Adaptation (LoRA) enable efficient single-concept customization by injecting lightweight, concept-specific adapters into pre-trained diffusion models. However, combining multiple LoRA modules for multi-concept generation often leads to identity missing and visual feature leakage. In this work, we identify two key issues behind these failures: (1) token-wise interference among different LoRA modules, and (2) spatial misalignment between the attention map of a rare token and its corresponding concept-specific region. To address these issues, we propose Token-Aware LoRA (TARA), which introduces a token mask to explicitly constrain each module to focus on its associated rare token to avoid interference, and a training objective that encourages the spatial attention of a rare token to align with its concept region. Our method enables training-free multi-concept composition by directly injecting multiple independently trained TARA modules at inference time. Experimental results demonstrate that TARA enables efficient multi-concept inference and effectively preserving the visual identity of each concept by avoiding mutual interference between LoRA modules. The code and models are available at https://github.com/YuqiPeng77/TARA.
GLAD: Generalizable Tuning for Vision-Language Models
Jul 17, 2025Pre-trained vision-language models, such as CLIP, show impressive zero-shot recognition ability and can be easily transferred to specific downstream tasks via prompt tuning, even with limited training data. However, existing prompt tuning methods face two main challenges: (1) In few-shot scenarios, data scarcity often leads to overfitting, making the model sensitive to changes in the input domain. (2) To mitigate overfitting, these methods typically rely on complex task-specific model architectures and sensitive hyperparameter tuning, severely restricting their general applicability. To address these issues, we propose a simpler and more general framework called GLAD (Generalizable LoRA tuning with RegulArized GraDient). We show that merely applying LoRA achieves performance in downstream tasks comparable to current state-of-the-art prompt-based methods. While LoRA is effective and easy to use, it remains susceptible to overfitting in few-shot learning scenarios. To mitigate this risk, we introduce a gradient-based regularization technique. This technique effectively steers the optimization trajectory, encouraging the model to find a more stable parameter region that is robust to variations in data distribution. Through extensive experiments conducted on 15 benchmark datasets, we demonstrate that GLAD outperforms previous tuning approaches in terms of base-to-novel class generalization, image domain generalization, and cross-dataset generalization. The code will be publicly available.
Zero-P-to-3: Zero-Shot Partial-View Images to 3D Object
May 29, 2025



Generative 3D reconstruction shows strong potential in incomplete observations. While sparse-view and single-image reconstruction are well-researched, partial observation remains underexplored. In this context, dense views are accessible only from a specific angular range, with other perspectives remaining inaccessible. This task presents two main challenges: (i) limited View Range: observations confined to a narrow angular scope prevent effective traditional interpolation techniques that require evenly distributed perspectives. (ii) inconsistent Generation: views created for invisible regions often lack coherence with both visible regions and each other, compromising reconstruction consistency. To address these challenges, we propose \method, a novel training-free approach that integrates the local dense observations and multi-source priors for reconstruction. Our method introduces a fusion-based strategy to effectively align these priors in DDIM sampling, thereby generating multi-view consistent images to supervise invisible views. We further design an iterative refinement strategy, which uses the geometric structures of the object to enhance reconstruction quality. Extensive experiments on multiple datasets show the superiority of our method over SOTAs, especially in invisible regions.
Direction-Aware Hybrid Representation Learning for 3D Hand Pose and Shape Estimation
Apr 03, 2025



Most model-based 3D hand pose and shape estimation methods directly regress the parametric model parameters from an image to obtain 3D joints under weak supervision. However, these methods involve solving a complex optimization problem with many local minima, making training difficult. To address this challenge, we propose learning direction-aware hybrid features (DaHyF) that fuse implicit image features and explicit 2D joint coordinate features. This fusion is enhanced by the pixel direction information in the camera coordinate system to estimate pose, shape, and camera viewpoint. Our method directly predicts 3D hand poses with DaHyF representation and reduces jittering during motion capture using prediction confidence based on contrastive learning. We evaluate our method on the FreiHAND dataset and show that it outperforms existing state-of-the-art methods by more than 33% in accuracy. DaHyF also achieves the top ranking on both the HO3Dv2 and HO3Dv3 leaderboards for the metric of Mean Joint Error (after scale and translation alignment). Compared to the second-best results, the largest improvement observed is 10%. We also demonstrate its effectiveness in real-time motion capture scenarios with hand position variability, occlusion, and motion blur.
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025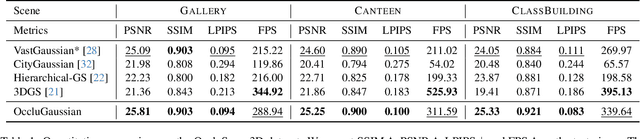
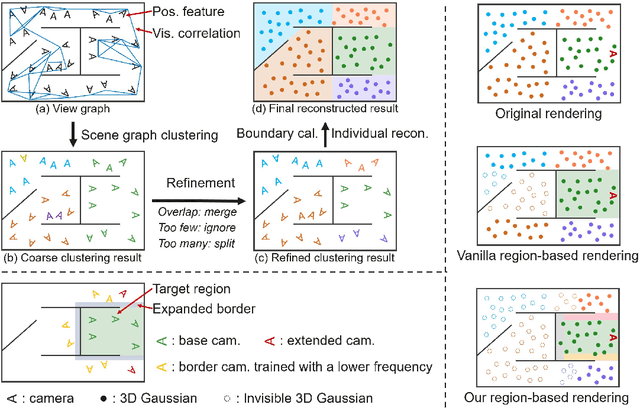
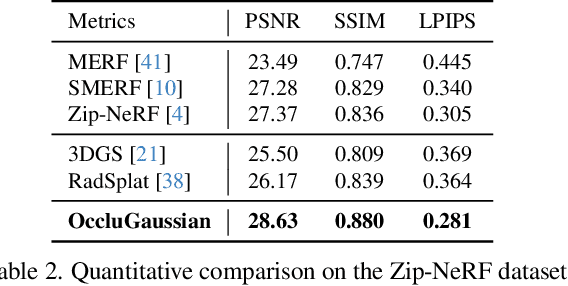
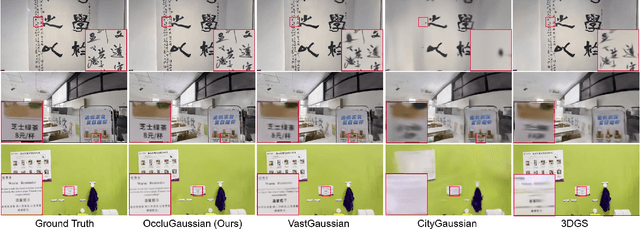
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
Decoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
Jan 18, 2025



Gaussian Splatting has emerged as a prominent 3D representation in novel view synthesis, but it still suffers from appearance variations, which are caused by various factors, such as modern camera ISPs, different time of day, weather conditions, and local light changes. These variations can lead to floaters and color distortions in the rendered images/videos. Recent appearance modeling approaches in Gaussian Splatting are either tightly coupled with the rendering process, hindering real-time rendering, or they only account for mild global variations, performing poorly in scenes with local light changes. In this paper, we propose DAVIGS, a method that decouples appearance variations in a plug-and-play and efficient manner. By transforming the rendering results at the image level instead of the Gaussian level, our approach can model appearance variations with minimal optimization time and memory overhead. Furthermore, our method gathers appearance-related information in 3D space to transform the rendered images, thus building 3D consistency across views implicitly. We validate our method on several appearance-variant scenes, and demonstrate that it achieves state-of-the-art rendering quality with minimal training time and memory usage, without compromising rendering speeds. Additionally, it provides performance improvements for different Gaussian Splatting baselines in a plug-and-play manner.
Dual-Schedule Inversion: Training- and Tuning-Free Inversion for Real Image Editing
Dec 15, 2024



Text-conditional image editing is a practical AIGC task that has recently emerged with great commercial and academic value. For real image editing, most diffusion model-based methods use DDIM Inversion as the first stage before editing. However, DDIM Inversion often results in reconstruction failure, leading to unsatisfactory performance for downstream editing. To address this problem, we first analyze why the reconstruction via DDIM Inversion fails. We then propose a new inversion and sampling method named Dual-Schedule Inversion. We also design a classifier to adaptively combine Dual-Schedule Inversion with different editing methods for user-friendly image editing. Our work can achieve superior reconstruction and editing performance with the following advantages: 1) It can reconstruct real images perfectly without fine-tuning, and its reversibility is guaranteed mathematically. 2) The edited object/scene conforms to the semantics of the text prompt. 3) The unedited parts of the object/scene retain the original identity.