 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicFight: Personalized Martial Arts Combat Video Generation
Jan 05, 2026Amid the surge in generic text-to-video generation, the field of personalized human video generation has witnessed notable advancements, primarily concentrated on single-person scenarios. However, to our knowledge, the domain of two-person interactions, particularly in the context of martial arts combat, remains uncharted. We identify a significant gap: existing models for single-person dancing generation prove insufficient for capturing the subtleties and complexities of two engaged fighters, resulting in challenges such as identity confusion, anomalous limbs, and action mismatches. To address this, we introduce a pioneering new task, Personalized Martial Arts Combat Video Generation. Our approach, MagicFight, is specifically crafted to overcome these hurdles. Given this pioneering task, we face a lack of appropriate datasets. Thus, we generate a bespoke dataset using the game physics engine Unity, meticulously crafting a multitude of 3D characters, martial arts moves, and scenes designed to represent the diversity of combat. MagicFight refines and adapts existing models and strategies to generate high-fidelity two-person combat videos that maintain individual identities and ensure seamless, coherent action sequences, thereby laying the groundwork for future innovations in the realm of interactive video content creation. Website: https://MingfuYAN.github.io/MagicFight/ Dataset: https://huggingface.co/datasets/MingfuYAN/KungFu-Fiesta
TARA: Token-Aware LoRA for Composable Personalization in Diffusion Models
Aug 12, 2025Personalized text-to-image generation aims to synthesize novel images of a specific subject or style using only a few reference images. Recent methods based on Low-Rank Adaptation (LoRA) enable efficient single-concept customization by injecting lightweight, concept-specific adapters into pre-trained diffusion models. However, combining multiple LoRA modules for multi-concept generation often leads to identity missing and visual feature leakage. In this work, we identify two key issues behind these failures: (1) token-wise interference among different LoRA modules, and (2) spatial misalignment between the attention map of a rare token and its corresponding concept-specific region. To address these issues, we propose Token-Aware LoRA (TARA), which introduces a token mask to explicitly constrain each module to focus on its associated rare token to avoid interference, and a training objective that encourages the spatial attention of a rare token to align with its concept region. Our method enables training-free multi-concept composition by directly injecting multiple independently trained TARA modules at inference time. Experimental results demonstrate that TARA enables efficient multi-concept inference and effectively preserving the visual identity of each concept by avoiding mutual interference between LoRA modules. The code and models are available at https://github.com/YuqiPeng77/TARA.
Contrast-Prior Enhanced Duality for Mask-Free Shadow Removal
Jul 29, 2025



Existing shadow removal methods often rely on shadow masks, which are challenging to acquire in real-world scenarios. Exploring intrinsic image cues, such as local contrast information, presents a potential alternative for guiding shadow removal in the absence of explicit masks. However, the cue's inherent ambiguity becomes a critical limitation in complex scenes, where it can fail to distinguish true shadows from low-reflectance objects and intricate background textures. To address this motivation, we propose the Adaptive Gated Dual-Branch Attention (AGBA) mechanism. AGBA dynamically filters and re-weighs the contrast prior to effectively disentangle shadow features from confounding visual elements. Furthermore, to tackle the persistent challenge of restoring soft shadow boundaries and fine-grained details, we introduce a diffusion-based Frequency-Contrast Fusion Network (FCFN) that leverages high-frequency and contrast cues to guide the generative process. Extensive experiments demonstrate that our method achieves state-of-the-art results among mask-free approaches while maintaining competitive performance relative to mask-based methods.
Component Adaptive Clustering for Generalized Category Discovery
Jul 02, 2025



Generalized Category Discovery (GCD) tackles the challenging problem of categorizing unlabeled images into both known and novel classes within a partially labeled dataset, without prior knowledge of the number of unknown categories. Traditional methods often rely on rigid assumptions, such as predefining the number of classes, which limits their ability to handle the inherent variability and complexity of real-world data. To address these shortcomings, we propose AdaGCD, a cluster-centric contrastive learning framework that incorporates Adaptive Slot Attention (AdaSlot) into the GCD framework. AdaSlot dynamically determines the optimal number of slots based on data complexity, removing the need for predefined slot counts. This adaptive mechanism facilitates the flexible clustering of unlabeled data into known and novel categories by dynamically allocating representational capacity. By integrating adaptive representation with dynamic slot allocation, our method captures both instance-specific and spatially clustered features, improving class discovery in open-world scenarios. Extensive experiments on public and fine-grained datasets validate the effectiveness of our framework, emphasizing the advantages of leveraging spatial local information for category discovery in unlabeled image datasets.
Leveraging Contrast Information for Efficient Document Shadow Removal
Apr 01, 2025Document shadows are a major obstacle in the digitization process. Due to the dense information in text and patterns covered by shadows, document shadow removal requires specialized methods. Existing document shadow removal methods, although showing some progress, still rely on additional information such as shadow masks or lack generalization and effectiveness across different shadow scenarios. This often results in incomplete shadow removal or loss of original document content and tones. Moreover, these methods tend to underutilize the information present in the original shadowed document image. In this paper, we refocus our approach on the document images themselves, which inherently contain rich information.We propose an end-to-end document shadow removal method guided by contrast representation, following a coarse-to-fine refinement approach. By extracting document contrast information, we can effectively and quickly locate shadow shapes and positions without the need for additional masks. This information is then integrated into the refined shadow removal process, providing better guidance for network-based removal and feature fusion. Extensive qualitative and quantitative experiments show that our method achieves state-of-the-art performance.
DIVE: Taming DINO for Subject-Driven Video Editing
Dec 04, 2024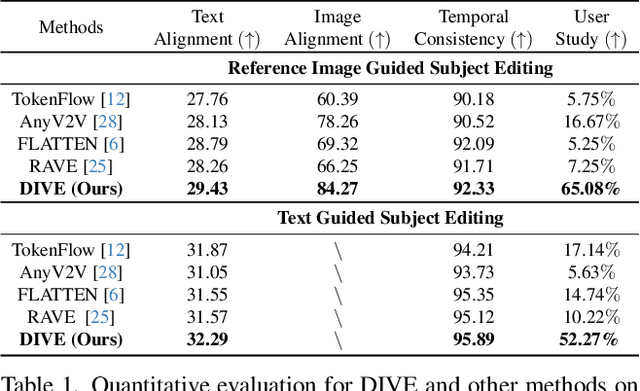

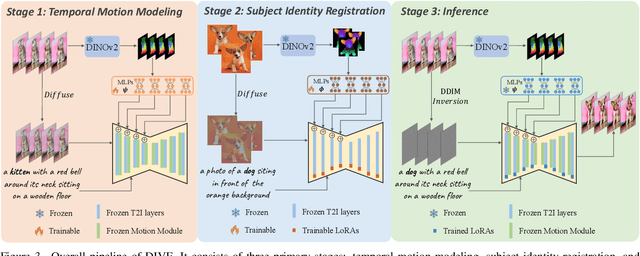
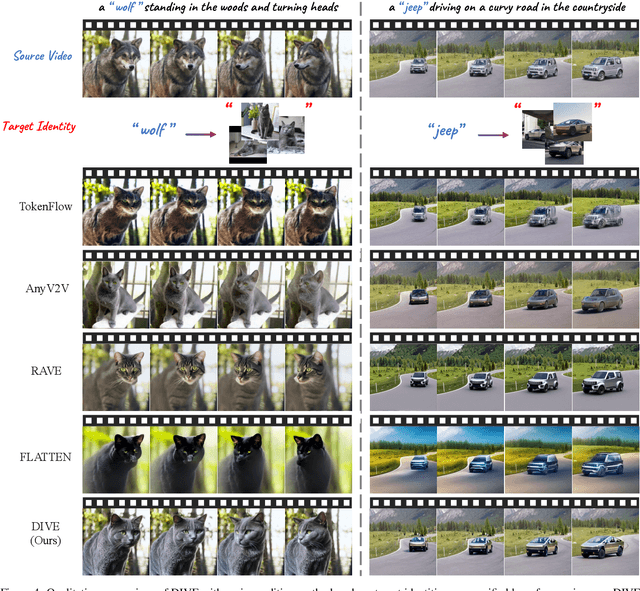
Building on the success of diffusion models in image generation and editing, video editing has recently gained substantial attention. However, maintaining temporal consistency and motion alignment still remains challenging. To address these issues, this paper proposes DINO-guided Video Editing (DIVE), a framework designed to facilitate subject-driven editing in source videos conditioned on either target text prompts or reference images with specific identities. The core of DIVE lies in leveraging the powerful semantic features extracted from a pretrained DINOv2 model as implicit correspondences to guide the editing process. Specifically, to ensure temporal motion consistency, DIVE employs DINO features to align with the motion trajectory of the source video. Extensive experiments on diverse real-world videos demonstrate that our framework can achieve high-quality editing results with robust motion consistency, highlighting the potential of DINO to contribute to video editing. For precise subject editing, DIVE incorporates the DINO features of reference images into a pretrained text-to-image model to learn Low-Rank Adaptations (LoRAs), effectively registering the target subject's identity. Project page: https://dino-video-editing.github.io
Diffusion Model-Based Image Editing: A Survey
Feb 27, 2024



Denoising diffusion models have emerged as a powerful tool for various image generation and editing tasks, facilitating the synthesis of visual content in an unconditional or input-conditional manner. The core idea behind them is learning to reverse the process of gradually adding noise to images, allowing them to generate high-quality samples from a complex distribution. In this survey, we provide an exhaustive overview of existing methods using diffusion models for image editing, covering both theoretical and practical aspects in the field. We delve into a thorough analysis and categorization of these works from multiple perspectives, including learning strategies, user-input conditions, and the array of specific editing tasks that can be accomplished. In addition, we pay special attention to image inpainting and outpainting, and explore both earlier traditional context-driven and current multimodal conditional methods, offering a comprehensive analysis of their methodologies. To further evaluate the performance of text-guided image editing algorithms, we propose a systematic benchmark, EditEval, featuring an innovative metric, LMM Score. Finally, we address current limitations and envision some potential directions for future research. The accompanying repository is released at https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods.
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Nov 21, 2023Recent advances in text-to-video generation have harnessed the power of diffusion models to create visually compelling content conditioned on text prompts. However, they usually encounter high computational costs and often struggle to produce videos with coherent physical motions. To tackle these issues, we propose GPT4Motion, a training-free framework that leverages the planning capability of large language models such as GPT, the physical simulation strength of Blender, and the excellent image generation ability of text-to-image diffusion models to enhance the quality of video synthesis. Specifically, GPT4Motion employs GPT-4 to generate a Blender script based on a user textual prompt, which commands Blender's built-in physics engine to craft fundamental scene components that encapsulate coherent physical motions across frames. Then these components are inputted into Stable Diffusion to generate a video aligned with the textual prompt. Experimental results on three basic physical motion scenarios, including rigid object drop and collision, cloth draping and swinging, and liquid flow, demonstrate that GPT4Motion can generate high-quality videos efficiently in maintaining motion coherency and entity consistency. GPT4Motion offers new insights in text-to-video research, enhancing its quality and broadening its horizon for future explorations.