 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTG-Field: Geometry-Aware Radiative Gaussian Fields for Tomographic Reconstruction
Feb 12, 20263D Gaussian Splatting (3DGS) has revolutionized 3D scene representation with superior efficiency and quality. While recent adaptations for computed tomography (CT) show promise, they struggle with severe artifacts under highly sparse-view projections and dynamic motions. To address these challenges, we propose Tomographic Geometry Field (TG-Field), a geometry-aware Gaussian deformation framework tailored for both static and dynamic CT reconstruction. A multi-resolution hash encoder is employed to capture local spatial priors, regularizing primitive parameters under ultra-sparse settings. We further extend the framework to dynamic reconstruction by introducing time-conditioned representations and a spatiotemporal attention block to adaptively aggregate features, thereby resolving spatiotemporal ambiguities and enforcing temporal coherence. In addition, a motion-flow network models fine-grained respiratory motion to track local anatomical deformations. Extensive experiments on synthetic and real-world datasets demonstrate that TG-Field consistently outperforms existing methods, achieving state-of-the-art reconstruction accuracy under highly sparse-view conditions.
Back to Physics: Operator-Guided Generative Paths for SMS MRI Reconstruction
Feb 08, 2026Simultaneous multi-slice (SMS) imaging with in-plane undersampling enables highly accelerated MRI but yields a strongly coupled inverse problem with deterministic inter-slice interference and missing k-space data. Most diffusion-based reconstructions are formulated around Gaussian-noise corruption and rely on additional consistency steps to incorporate SMS physics, which can be mismatched to the operator-governed degradations in SMS acquisition. We propose an operator-guided framework that models the degradation trajectory using known acquisition operators and inverts this process via deterministic updates. Within this framework, we introduce an operator-conditional dual-stream interaction network (OCDI-Net) that explicitly disentangles target-slice content from inter-slice interference and predicts structured degradations for operator-aligned inversion, and we instantiate reconstruction as a two-stage chained inference procedure that performs SMS slice separation followed by in-plane completion. Experiments on fastMRI brain data and prospectively acquired in vivo diffusion MRI data demonstrate improved fidelity and reduced slice leakage over conventional and learning-based SMS reconstructions.
Generalized Category Discovery via Token Manifold Capacity Learning
May 20, 2025Generalized category discovery (GCD) is essential for improving deep learning models' robustness in open-world scenarios by clustering unlabeled data containing both known and novel categories. Traditional GCD methods focus on minimizing intra-cluster variations, often sacrificing manifold capacity, which limits the richness of intra-class representations. In this paper, we propose a novel approach, Maximum Token Manifold Capacity (MTMC), that prioritizes maximizing the manifold capacity of class tokens to preserve the diversity and complexity of data. MTMC leverages the nuclear norm of singular values as a measure of manifold capacity, ensuring that the representation of samples remains informative and well-structured. This method enhances the discriminability of clusters, allowing the model to capture detailed semantic features and avoid the loss of critical information during clustering. Through theoretical analysis and extensive experiments on coarse- and fine-grained datasets, we demonstrate that MTMC outperforms existing GCD methods, improving both clustering accuracy and the estimation of category numbers. The integration of MTMC leads to more complete representations, better inter-class separability, and a reduction in dimensional collapse, establishing MTMC as a vital component for robust open-world learning. Code is in github.com/lytang63/MTMC.
OCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad
Mar 24, 2025Although foundation models (FMs) claim to be powerful, their generalization ability significantly decreases when faced with distribution shifts, weak supervision, or malicious attacks in the open world. On the other hand, most domain generalization or adversarial fine-tuning methods are task-related or model-specific, ignoring the universality in practical applications and the transferability between FMs. This paper delves into the problem of generalizing FMs to the out-of-domain data. We propose a novel framework, the Object-Concept-Relation Triad (OCRT), that enables FMs to extract sparse, high-level concepts and intricate relational structures from raw visual inputs. The key idea is to bind objects in visual scenes and a set of object-centric representations through unsupervised decoupling and iterative refinement. To be specific, we project the object-centric representations onto a semantic concept space that the model can readily interpret and estimate their importance to filter out irrelevant elements. Then, a concept-based graph, which has a flexible degree, is constructed to incorporate the set of concepts and their corresponding importance, enabling the extraction of high-order factors from informative concepts and facilitating relational reasoning among these concepts. Extensive experiments demonstrate that OCRT can substantially boost the generalizability and robustness of SAM and CLIP across multiple downstream tasks.
Single-View Graph Contrastive Learning with Soft Neighborhood Awareness
Dec 12, 2024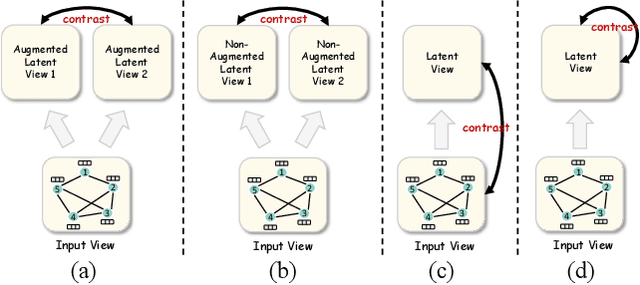


Most graph contrastive learning (GCL) methods heavily rely on cross-view contrast, thus facing several concomitant challenges, such as the complexity of designing effective augmentations, the potential for information loss between views, and increased computational costs. To mitigate reliance on cross-view contrasts, we propose \ttt{SIGNA}, a novel single-view graph contrastive learning framework. Regarding the inconsistency between structural connection and semantic similarity of neighborhoods, we resort to soft neighborhood awareness for GCL. Specifically, we leverage dropout to obtain structurally-related yet randomly-noised embedding pairs for neighbors, which serve as potential positive samples. At each epoch, the role of partial neighbors is switched from positive to negative, leading to probabilistic neighborhood contrastive learning effect. Furthermore, we propose a normalized Jensen-Shannon divergence estimator for a better effect of contrastive learning. Surprisingly, experiments on diverse node-level tasks demonstrate that our simple single-view GCL framework consistently outperforms existing methods by margins of up to 21.74% (PPI). In particular, with soft neighborhood awareness, SIGNA can adopt MLPs instead of complicated GCNs as the encoder to generate representations in transductive learning tasks, thus speeding up its inference process by 109 times to 331 times. The source code is available at https://github.com/sunisfighting/SIGNA.
DIVE: Taming DINO for Subject-Driven Video Editing
Dec 04, 2024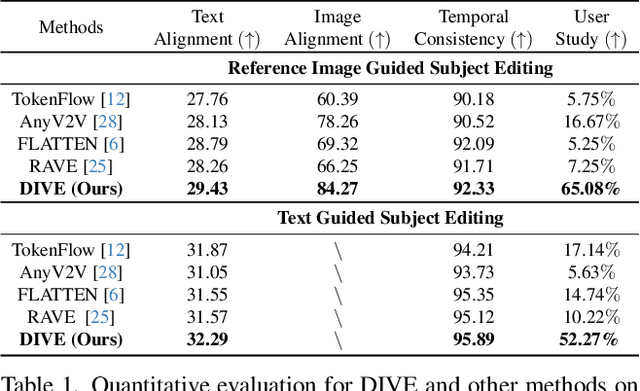

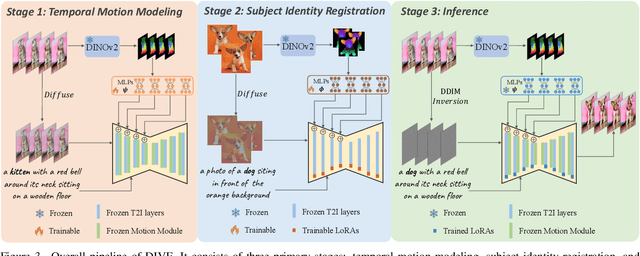
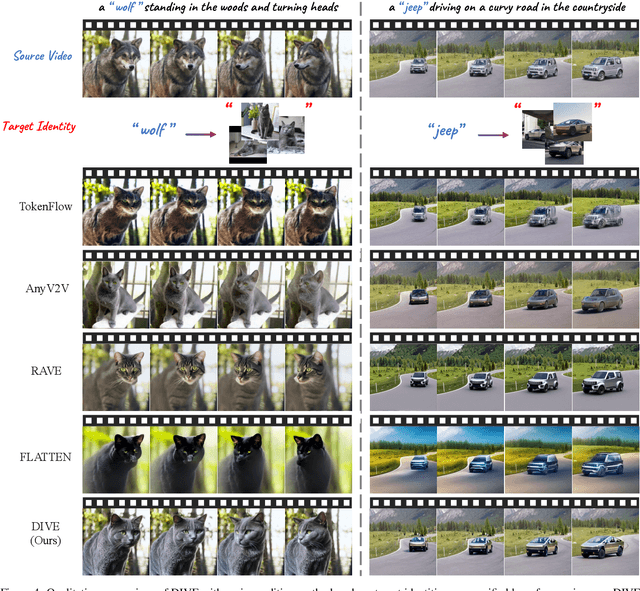
Building on the success of diffusion models in image generation and editing, video editing has recently gained substantial attention. However, maintaining temporal consistency and motion alignment still remains challenging. To address these issues, this paper proposes DINO-guided Video Editing (DIVE), a framework designed to facilitate subject-driven editing in source videos conditioned on either target text prompts or reference images with specific identities. The core of DIVE lies in leveraging the powerful semantic features extracted from a pretrained DINOv2 model as implicit correspondences to guide the editing process. Specifically, to ensure temporal motion consistency, DIVE employs DINO features to align with the motion trajectory of the source video. Extensive experiments on diverse real-world videos demonstrate that our framework can achieve high-quality editing results with robust motion consistency, highlighting the potential of DINO to contribute to video editing. For precise subject editing, DIVE incorporates the DINO features of reference images into a pretrained text-to-image model to learn Low-Rank Adaptations (LoRAs), effectively registering the target subject's identity. Project page: https://dino-video-editing.github.io
Bootstrap Segmentation Foundation Model under Distribution Shift via Object-Centric Learning
Aug 29, 2024



Foundation models have made incredible strides in achieving zero-shot or few-shot generalization, leveraging prompt engineering to mimic the problem-solving approach of human intelligence. However, when it comes to some foundation models like Segment Anything, there is still a challenge in performing well on out-of-distribution data, including camouflaged and medical images. Inconsistent prompting strategies during fine-tuning and testing further compound the issue, leading to decreased performance. Drawing inspiration from how human cognition processes new environments, we introduce SlotSAM, a method that reconstructs features from the encoder in a self-supervised manner to create object-centric representations. These representations are then integrated into the foundation model, bolstering its object-level perceptual capabilities while reducing the impact of distribution-related variables. The beauty of SlotSAM lies in its simplicity and adaptability to various tasks, making it a versatile solution that significantly enhances the generalization abilities of foundation models. Through limited parameter fine-tuning in a bootstrap manner, our approach paves the way for improved generalization in novel environments. The code is available at github.com/lytang63/SlotSAM.
Mixstyle-Entropy: Domain Generalization with Causal Intervention and Perturbation
Aug 22, 2024



Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
InPer: Whole-Process Domain Generalization via Causal Intervention and Perturbation
Aug 07, 2024Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
LaMamba-Diff: Linear-Time High-Fidelity Diffusion Models Based on Local Attention and Mamba
Aug 05, 2024



Recent Transformer-based diffusion models have shown remarkable performance, largely attributed to the ability of the self-attention mechanism to accurately capture both global and local contexts by computing all-pair interactions among input tokens. However, their quadratic complexity poses significant computational challenges for long-sequence inputs. Conversely, a recent state space model called Mamba offers linear complexity by compressing a filtered global context into a hidden state. Despite its efficiency, compression inevitably leads to information loss of fine-grained local dependencies among tokens, which are crucial for effective visual generative modeling. Motivated by these observations, we introduce Local Attentional Mamba (LaMamba) blocks that combine the strengths of self-attention and Mamba, capturing both global contexts and local details with linear complexity. Leveraging the efficient U-Net architecture, our model exhibits exceptional scalability and surpasses the performance of DiT across various model scales on ImageNet at 256x256 resolution, all while utilizing substantially fewer GFLOPs and a comparable number of parameters. Compared to state-of-the-art diffusion models on ImageNet 256x256 and 512x512, our largest model presents notable advantages, such as a reduction of up to 62\% GFLOPs compared to DiT-XL/2, while achieving superior performance with comparable or fewer parameters.