 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Retrieval Augmentation for Dynamic Recommendation
Nov 16, 2025Dynamic recommendation systems aim to provide personalized suggestions by modeling temporal user-item interactions across time-series behavioral data. Recent studies have leveraged pre-trained dynamic graph neural networks (GNNs) to learn user-item representations over temporal snapshot graphs. However, fine-tuning GNNs on these graphs often results in generalization issues due to temporal discrepancies between pre-training and fine-tuning stages, limiting the model's ability to capture evolving user preferences. To address this, we propose TarDGR, a task-aware retrieval-augmented framework designed to enhance generalization capability by incorporating task-aware model and retrieval-augmentation. Specifically, TarDGR introduces a Task-Aware Evaluation Mechanism to identify semantically relevant historical subgraphs, enabling the construction of task-specific datasets without manual labeling. It also presents a Graph Transformer-based Task-Aware Model that integrates semantic and structural encodings to assess subgraph relevance. During inference, TarDGR retrieves and fuses task-aware subgraphs with the query subgraph, enriching its representation and mitigating temporal generalization issues. Experiments on multiple large-scale dynamic graph datasets demonstrate that TarDGR consistently outperforms state-of-the-art methods, with extensive empirical evidence underscoring its superior accuracy and generalization capabilities.
Single-View Graph Contrastive Learning with Soft Neighborhood Awareness
Dec 12, 2024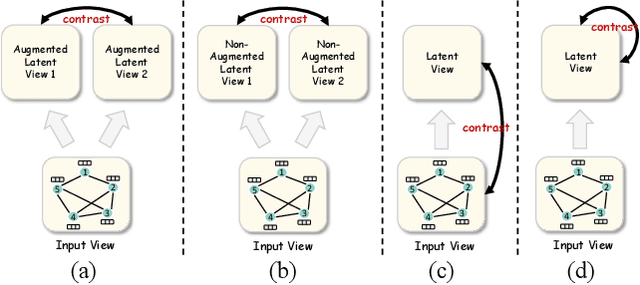

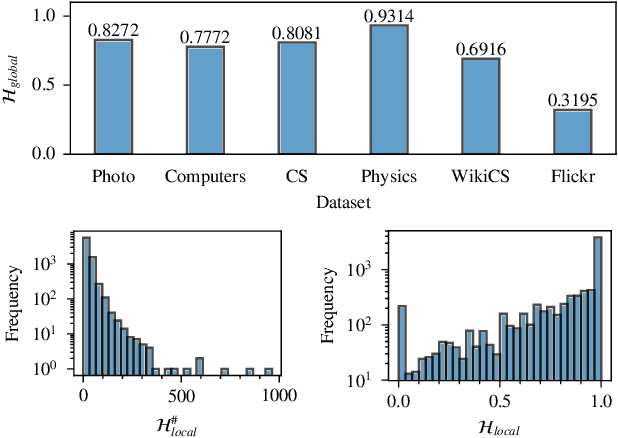

Most graph contrastive learning (GCL) methods heavily rely on cross-view contrast, thus facing several concomitant challenges, such as the complexity of designing effective augmentations, the potential for information loss between views, and increased computational costs. To mitigate reliance on cross-view contrasts, we propose \ttt{SIGNA}, a novel single-view graph contrastive learning framework. Regarding the inconsistency between structural connection and semantic similarity of neighborhoods, we resort to soft neighborhood awareness for GCL. Specifically, we leverage dropout to obtain structurally-related yet randomly-noised embedding pairs for neighbors, which serve as potential positive samples. At each epoch, the role of partial neighbors is switched from positive to negative, leading to probabilistic neighborhood contrastive learning effect. Furthermore, we propose a normalized Jensen-Shannon divergence estimator for a better effect of contrastive learning. Surprisingly, experiments on diverse node-level tasks demonstrate that our simple single-view GCL framework consistently outperforms existing methods by margins of up to 21.74% (PPI). In particular, with soft neighborhood awareness, SIGNA can adopt MLPs instead of complicated GCNs as the encoder to generate representations in transductive learning tasks, thus speeding up its inference process by 109 times to 331 times. The source code is available at https://github.com/sunisfighting/SIGNA.
Holistic Memory Diversification for Incremental Learning in Growing Graphs
Jun 11, 2024



This paper addresses the challenge of incremental learning in growing graphs with increasingly complex tasks. The goal is to continually train a graph model to handle new tasks while retaining its inference ability on previous tasks. Existing methods usually neglect the importance of memory diversity, limiting in effectively selecting high-quality memory from previous tasks and remembering broad previous knowledge within the scarce memory on graphs. To address that, we introduce a novel holistic Diversified Memory Selection and Generation (DMSG) framework for incremental learning in graphs, which first introduces a buffer selection strategy that considers both intra-class and inter-class diversities, employing an efficient greedy algorithm for sampling representative training nodes from graphs into memory buffers after learning each new task. Then, to adequately rememorize the knowledge preserved in the memory buffer when learning new tasks, we propose a diversified memory generation replay method. This method first utilizes a variational layer to generate the distribution of buffer node embeddings and sample synthesized ones for replaying. Furthermore, an adversarial variational embedding learning method and a reconstruction-based decoder are proposed to maintain the integrity and consolidate the generalization of the synthesized node embeddings, respectively. Finally, we evaluate our model on node classification tasks involving increasing class numbers. Extensive experimental results on publicly accessible datasets demonstrate the superiority of DMSG over state-of-the-art methods.
Towards Higher-order Topological Consistency for Unsupervised Network Alignment
Aug 26, 2022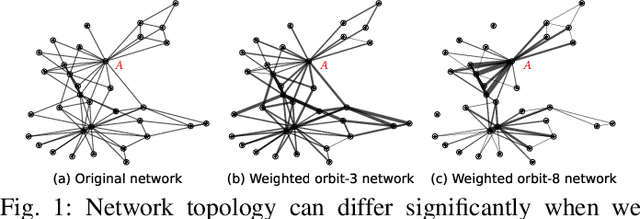
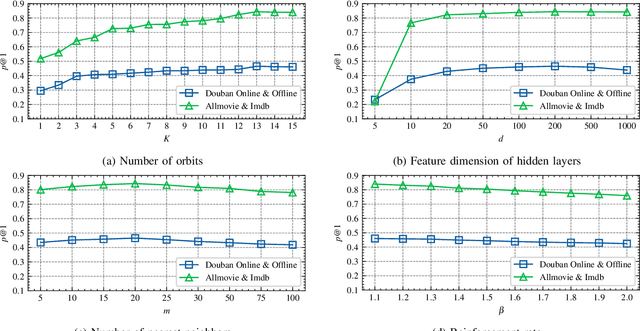
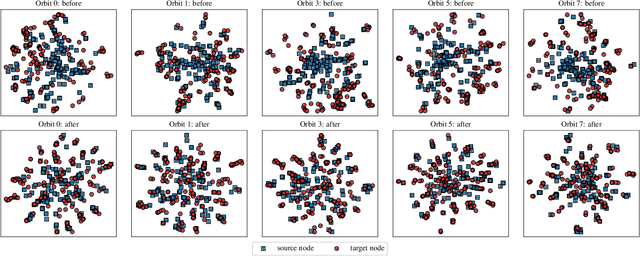
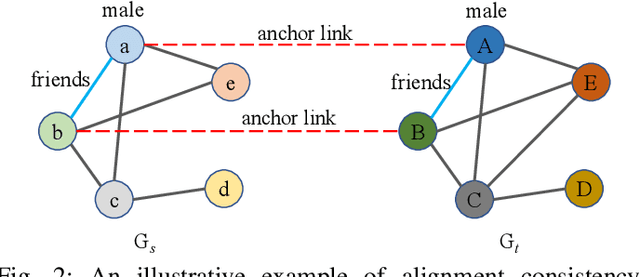
Network alignment task, which aims to identify corresponding nodes in different networks, is of great significance for many subsequent applications. Without the need for labeled anchor links, unsupervised alignment methods have been attracting more and more attention. However, the topological consistency assumptions defined by existing methods are generally low-order and less accurate because only the edge-indiscriminative topological pattern is considered, which is especially risky in an unsupervised setting. To reposition the focus of the alignment process from low-order to higher-order topological consistency, in this paper, we propose a fully unsupervised network alignment framework named HTC. The proposed higher-order topological consistency is formulated based on edge orbits, which is merged into the information aggregation process of a graph convolutional network so that the alignment consistencies are transformed into the similarity of node embeddings. Furthermore, the encoder is trained to be multi-orbit-aware and then be refined to identify more trusted anchor links. Node correspondence is comprehensively evaluated by integrating all different orders of consistency. {In addition to sound theoretical analysis, the superiority of the proposed method is also empirically demonstrated through extensive experimental evaluation. On three pairs of real-world datasets and two pairs of synthetic datasets, our HTC consistently outperforms a wide variety of unsupervised and supervised methods with the least or comparable time consumption. It also exhibits robustness to structural noise as a result of our multi-orbit-aware training mechanism.