 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering
Jan 23, 2026With the rapid growth of scientific literature, scientific question answering (SciQA) has become increasingly critical for exploring and utilizing scientific knowledge. Retrieval-Augmented Generation (RAG) enhances LLMs by incorporating knowledge from external sources, thereby providing credible evidence for scientific question answering. But existing retrieval and reranking methods remain vulnerable to passages that are semantically similar but logically irrelevant, often reducing factual reliability and amplifying hallucinations.To address this challenge, we propose a Deep Evidence Reranking Agent (DeepEra) that integrates step-by-step reasoning, enabling more precise evaluation of candidate passages beyond surface-level semantics. To support systematic evaluation, we construct SciRAG-SSLI (Scientific RAG - Semantically Similar but Logically Irrelevant), a large-scale dataset comprising about 300K SciQA instances across 10 subjects, constructed from 10M scientific corpus. The dataset combines naturally retrieved contexts with systematically generated distractors to test logical robustness and factual grounding. Comprehensive evaluations confirm that our approach achieves superior retrieval performance compared to leading rerankers. To our knowledge, this work is the first to comprehensively study and empirically validate innegligible SSLI issues in two-stage RAG frameworks.
SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
Jan 21, 2026Large language models (LLMs) have shown growing promise in biomedical research, particularly for knowledge-driven interpretation tasks. However, their ability to reliably reason from gene-level knowledge to functional understanding, a core requirement for knowledge-enhanced cell atlas interpretation, remains largely underexplored. To address this gap, we introduce SciHorizon-GENE, a large-scale gene-centric benchmark constructed from authoritative biological databases. The benchmark integrates curated knowledge for over 190K human genes and comprises more than 540K questions covering diverse gene-to-function reasoning scenarios relevant to cell type annotation, functional interpretation, and mechanism-oriented analysis. Motivated by behavioral patterns observed in preliminary examinations, SciHorizon-GENE evaluates LLMs along four biologically critical perspectives: research attention sensitivity, hallucination tendency, answer completeness, and literature influence, explicitly targeting failure modes that limit the safe adoption of LLMs in biological interpretation pipelines. We systematically evaluate a wide range of state-of-the-art general-purpose and biomedical LLMs, revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations. Our benchmark establishes a systematic foundation for analyzing LLM behavior at the gene scale and offers insights for model selection and development, with direct relevance to knowledge-enhanced biological interpretation.
SciRerankBench: Benchmarking Rerankers Towards Scientific Retrieval-Augmented Generated LLMs
Aug 12, 2025Scientific literature question answering is a pivotal step towards new scientific discoveries. Recently, \textit{two-stage} retrieval-augmented generated large language models (RAG-LLMs) have shown impressive advancements in this domain. Such a two-stage framework, especially the second stage (reranker), is particularly essential in the scientific domain, where subtle differences in terminology may have a greatly negative impact on the final factual-oriented or knowledge-intensive answers. Despite this significant progress, the potential and limitations of these works remain unexplored. In this work, we present a Scientific Rerank-oriented RAG Benchmark (SciRerankBench), for evaluating rerankers within RAG-LLMs systems, spanning five scientific subjects. To rigorously assess the reranker performance in terms of noise resilience, relevance disambiguation, and factual consistency, we develop three types of question-context-answer (Q-C-A) pairs, i.e., Noisy Contexts (NC), Semantically Similar but Logically Irrelevant Contexts (SSLI), and Counterfactual Contexts (CC). Through systematic evaluation of 13 widely used rerankers on five families of LLMs, we provide detailed insights into their relative strengths and limitations. To the best of our knowledge, SciRerankBench is the first benchmark specifically developed to evaluate rerankers within RAG-LLMs, which provides valuable observations and guidance for their future development.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025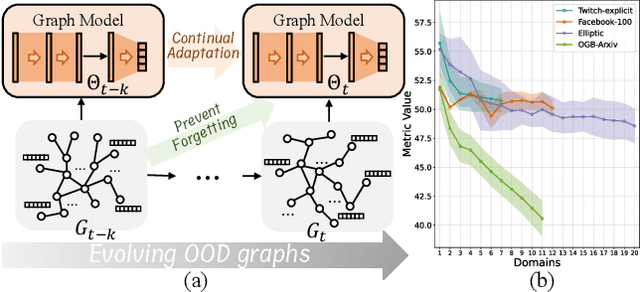
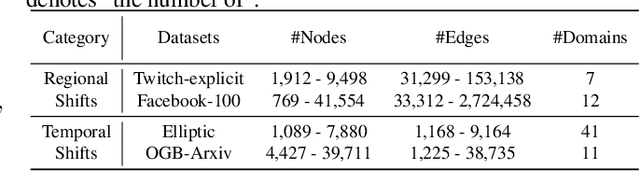
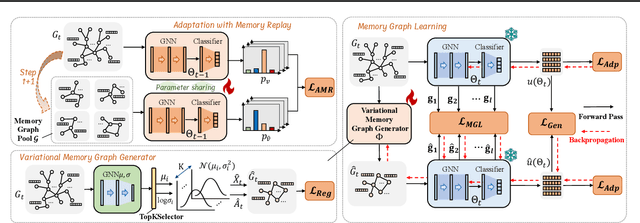
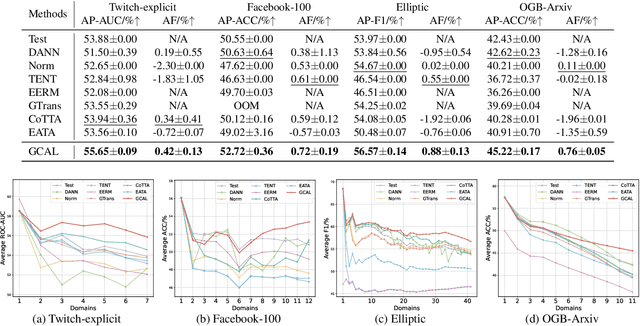
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
m-KAILIN: Knowledge-Driven Agentic Scientific Corpus Distillation Framework for Biomedical Large Language Models Training
Apr 28, 2025The rapid progress of large language models (LLMs) in biomedical research has underscored the limitations of existing open-source annotated scientific corpora, which are often insufficient in quantity and quality. Addressing the challenge posed by the complex hierarchy of biomedical knowledge, we propose a knowledge-driven, multi-agent framework for scientific corpus distillation tailored for LLM training in the biomedical domain. Central to our approach is a collaborative multi-agent architecture, where specialized agents, each guided by the Medical Subject Headings (MeSH) hierarchy, work in concert to autonomously extract, synthesize, and self-evaluate high-quality textual data from vast scientific literature. These agents collectively generate and refine domain-specific question-answer pairs, ensuring comprehensive coverage and consistency with biomedical ontologies while minimizing manual involvement. Extensive experimental results show that language models trained on our multi-agent distilled datasets achieve notable improvements in biomedical question-answering tasks, outperforming both strong life sciences LLM baselines and advanced proprietary models. Notably, our AI-Ready dataset enables Llama3-70B to surpass GPT-4 with MedPrompt and Med-PaLM-2, despite their larger scale. Detailed ablation studies and case analyses further validate the effectiveness and synergy of each agent within the framework, highlighting the potential of multi-agent collaboration in biomedical LLM training.
Comprehend, Divide, and Conquer: Feature Subspace Exploration via Multi-Agent Hierarchical Reinforcement Learning
Apr 24, 2025



Feature selection aims to preprocess the target dataset, find an optimal and most streamlined feature subset, and enhance the downstream machine learning task. Among filter, wrapper, and embedded-based approaches, the reinforcement learning (RL)-based subspace exploration strategy provides a novel objective optimization-directed perspective and promising performance. Nevertheless, even with improved performance, current reinforcement learning approaches face challenges similar to conventional methods when dealing with complex datasets. These challenges stem from the inefficient paradigm of using one agent per feature and the inherent complexities present in the datasets. This observation motivates us to investigate and address the above issue and propose a novel approach, namely HRLFS. Our methodology initially employs a Large Language Model (LLM)-based hybrid state extractor to capture each feature's mathematical and semantic characteristics. Based on this information, features are clustered, facilitating the construction of hierarchical agents for each cluster and sub-cluster. Extensive experiments demonstrate the efficiency, scalability, and robustness of our approach. Compared to contemporary or the one-feature-one-agent RL-based approaches, HRLFS improves the downstream ML performance with iterative feature subspace exploration while accelerating total run time by reducing the number of agents involved.
Collaborative Multi-Agent Reinforcement Learning for Automated Feature Transformation with Graph-Driven Path Optimization
Apr 24, 2025



Feature transformation methods aim to find an optimal mathematical feature-feature crossing process that generates high-value features and improves the performance of downstream machine learning tasks. Existing frameworks, though designed to mitigate manual costs, often treat feature transformations as isolated operations, ignoring dynamic dependencies between transformation steps. To address the limitations, we propose TCTO, a collaborative multi-agent reinforcement learning framework that automates feature engineering through graph-driven path optimization. The framework's core innovation lies in an evolving interaction graph that models features as nodes and transformations as edges. Through graph pruning and backtracking, it dynamically eliminates low-impact edges, reduces redundant operations, and enhances exploration stability. This graph also provides full traceability to empower TCTO to reuse high-utility subgraphs from historical transformations. To demonstrate the efficacy and adaptability of our approach, we conduct comprehensive experiments and case studies, which show superior performance across a range of datasets.
DynMoLE: Boosting Mixture of LoRA Experts Fine-Tuning with a Hybrid Routing Mechanism
Apr 01, 2025Instruction-based fine-tuning of large language models (LLMs) has achieved remarkable success in various natural language processing (NLP) tasks. Parameter-efficient fine-tuning (PEFT) methods, such as Mixture of LoRA Experts (MoLE), combine the efficiency of Low-Rank Adaptation (LoRA) with the versatility of Mixture of Experts (MoE) models, demonstrating significant potential for handling multiple downstream tasks. However, the existing routing mechanisms for MoLE often involve a trade-off between computational efficiency and predictive accuracy, and they fail to fully address the diverse expert selection demands across different transformer layers. In this work, we propose DynMoLE, a hybrid routing strategy that dynamically adjusts expert selection based on the Tsallis entropy of the router's probability distribution. This approach mitigates router uncertainty, enhances stability, and promotes more equitable expert participation, leading to faster convergence and improved model performance. Additionally, we introduce an auxiliary loss based on Tsallis entropy to further guide the model toward convergence with reduced uncertainty, thereby improving training stability and performance. Our extensive experiments on commonsense reasoning benchmarks demonstrate that DynMoLE achieves substantial performance improvements, outperforming LoRA by 9.6% and surpassing the state-of-the-art MoLE method, MoLA, by 2.3%. We also conduct a comprehensive ablation study to evaluate the contributions of DynMoLE's key components.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
FastFT: Accelerating Reinforced Feature Transformation via Advanced Exploration Strategies
Mar 26, 2025



Feature Transformation is crucial for classic machine learning that aims to generate feature combinations to enhance the performance of downstream tasks from a data-centric perspective. Current methodologies, such as manual expert-driven processes, iterative-feedback techniques, and exploration-generative tactics, have shown promise in automating such data engineering workflow by minimizing human involvement. However, three challenges remain in those frameworks: (1) It predominantly depends on downstream task performance metrics, as assessment is time-consuming, especially for large datasets. (2) The diversity of feature combinations will hardly be guaranteed after random exploration ends. (3) Rare significant transformations lead to sparse valuable feedback that hinders the learning processes or leads to less effective results. In response to these challenges, we introduce FastFT, an innovative framework that leverages a trio of advanced strategies.We first decouple the feature transformation evaluation from the outcomes of the generated datasets via the performance predictor. To address the issue of reward sparsity, we developed a method to evaluate the novelty of generated transformation sequences. Incorporating this novelty into the reward function accelerates the model's exploration of effective transformations, thereby improving the search productivity. Additionally, we combine novelty and performance to create a prioritized memory buffer, ensuring that essential experiences are effectively revisited during exploration. Our extensive experimental evaluations validate the performance, efficiency, and traceability of our proposed framework, showcasing its superiority in handling complex feature transformation tasks.