 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldReasonBench: Human-Aligned Stress Testing of Video Generators as Future World-State Predictors
May 11, 2026Commercial video generation systems such as Seedance2.0 and Veo3.1 have rapidly improved, strengthening the view that video generators may be evolving into "world simulators." Yet the community still lacks a benchmark that directly tests whether a model can reason about how an observed world should evolve over time. We introduce WorldReasonBench, which reframes video generation evaluation as world-state prediction: given an initial state and an action, can a model generate a future video whose state evolution remains physically, socially, logically, and informationally consistent? WorldReasonBench contains 436 curated test cases with structured ground-truth QA annotations spanning four reasoning dimensions and 22 subcategories. We evaluate generated videos with a human-aligned two-part methodology: Process-aware Reasoning Verification uses structured QA and reasoning-phase diagnostics to detect temporal and causal failures, while Multi-dimensional Quality Assessment scores reasoning quality, temporal consistency, and visual aesthetics for ranking and reward modeling. We further introduce WorldRewardBench, a preference benchmark with approximately 6K expert-annotated pairs over 1.4K videos, supporting pair-wise and point-wise reward-model evaluation. Across modern video generators, our results expose a persistent gap between visual plausibility and world reasoning: videos can look convincing while failing dynamics, causality, or information preservation. We will release our benchmarks and evaluation toolkit to support community research on genuinely world-aware video generation at https://github.com/UniX-AI-Lab/WorldReasonBench/.
DiffSparse: Accelerating Diffusion Transformers with Learned Token Sparsity
Apr 04, 2026Diffusion models demonstrate outstanding performance in image generation, but their multi-step inference mechanism requires immense computational cost. Previous works accelerate inference by leveraging layer or token cache techniques to reduce computational cost. However, these methods fail to achieve superior acceleration performance in few-step diffusion transformer models due to inefficient feature caching strategies, manually designed sparsity allocation, and the practice of retaining complete forward computations in several steps in these token cache methods. To tackle these challenges, we propose a differentiable layer-wise sparsity optimization framework for diffusion transformer models, leveraging token caching to reduce token computation costs and enhance acceleration. Our method optimizes layer-wise sparsity allocation in an end-to-end manner through a learnable network combined with a dynamic programming solver. Additionally, our proposed two-stage training strategy eliminates the need for full-step processing in existing methods, further improving efficiency. We conducted extensive experiments on a range of diffusion-transformer models, including DiT-XL/2, PixArt-$α$, FLUX, and Wan2.1. Across these architectures, our method consistently improves efficiency without degrading sample quality. For example, on PixArt-$α$ with 20 sampling steps, we reduce computational cost by $54\%$ while achieving generation metrics that surpass those of the original model, substantially outperforming prior approaches. These results demonstrate that our method delivers large efficiency gains while often improving generation quality.
Mango-GS: Enhancing Spatio-Temporal Consistency in Dynamic Scenes Reconstruction using Multi-Frame Node-Guided 4D Gaussian Splatting
Mar 12, 2026Reconstructing dynamic 3D scenes with photorealistic detail and strong temporal coherence remains a significant challenge. Existing Gaussian splatting approaches for dynamic scene modeling often rely on per-frame optimization, which can overfit to instantaneous states instead of capturing underlying motion dynamics. To address this, we present Mango-GS, a multi-frame, node-guided framework for high-fidelity 4D reconstruction. Mango-GS leverages a temporal Transformer to model motion dependencies within a short window of frames, producing temporally consistent deformations. For efficiency, temporal modeling is confined to a sparse set of control nodes. Each node is represented by a decoupled canonical position and a latent code, providing a stable semantic anchor for motion propagation and preventing correspondence drift under large motion. Our framework is trained end-to-end, enhanced by an input masking strategy and two multi-frame losses to improve robustness. Extensive experiments demonstrate that Mango-GS achieves state-of-the-art reconstruction quality and real-time rendering speed, enabling high-fidelity reconstruction and interactive rendering of dynamic scenes.
TAP: A Token-Adaptive Predictor Framework for Training-Free Diffusion Acceleration
Mar 04, 2026Diffusion models achieve strong generative performance but remain slow at inference due to the need for repeated full-model denoising passes. We present Token-Adaptive Predictor (TAP), a training-free, probe-driven framework that adaptively selects a predictor for each token at every sampling step. TAP uses a single full evaluation of the model's first layer as a low-cost probe to compute proxy losses for a compact family of candidate predictors (instantiated primarily with Taylor expansions of varying order and horizon), then assigns each token the predictor with the smallest proxy error. This per-token "probe-then-select" strategy exploits heterogeneous temporal dynamics, requires no additional training, and is compatible with various predictor designs. TAP incurs negligible overhead while enabling large speedups with little or no perceptual quality loss. Extensive experiments across multiple diffusion architectures and generation tasks show that TAP substantially improves the accuracy-efficiency frontier compared to fixed global predictors and caching-only baselines.
DiffBench Meets DiffAgent: End-to-End LLM-Driven Diffusion Acceleration Code Generation
Jan 06, 2026Diffusion models have achieved remarkable success in image and video generation. However, their inherently multiple step inference process imposes substantial computational overhead, hindering real-world deployment. Accelerating diffusion models is therefore essential, yet determining how to combine multiple model acceleration techniques remains a significant challenge. To address this issue, we introduce a framework driven by large language models (LLMs) for automated acceleration code generation and evaluation. First, we present DiffBench, a comprehensive benchmark that implements a three stage automated evaluation pipeline across diverse diffusion architectures, optimization combinations and deployment scenarios. Second, we propose DiffAgent, an agent that generates optimal acceleration strategies and codes for arbitrary diffusion models. DiffAgent employs a closed-loop workflow in which a planning component and a debugging component iteratively refine the output of a code generation component, while a genetic algorithm extracts performance feedback from the execution environment to guide subsequent code refinements. We provide a detailed explanation of the DiffBench construction and the design principles underlying DiffAgent. Extensive experiments show that DiffBench offers a thorough evaluation of generated codes and that DiffAgent significantly outperforms existing LLMs in producing effective diffusion acceleration strategies.
Accelerating Diffusion-based Super-Resolution with Dynamic Time-Spatial Sampling
May 17, 2025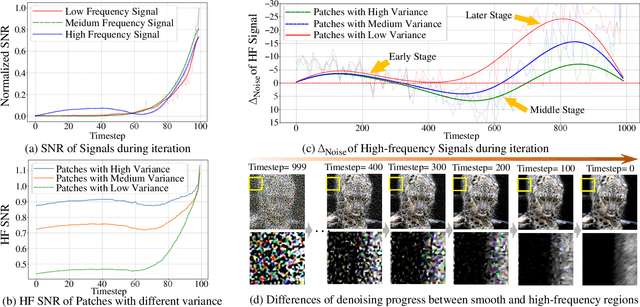
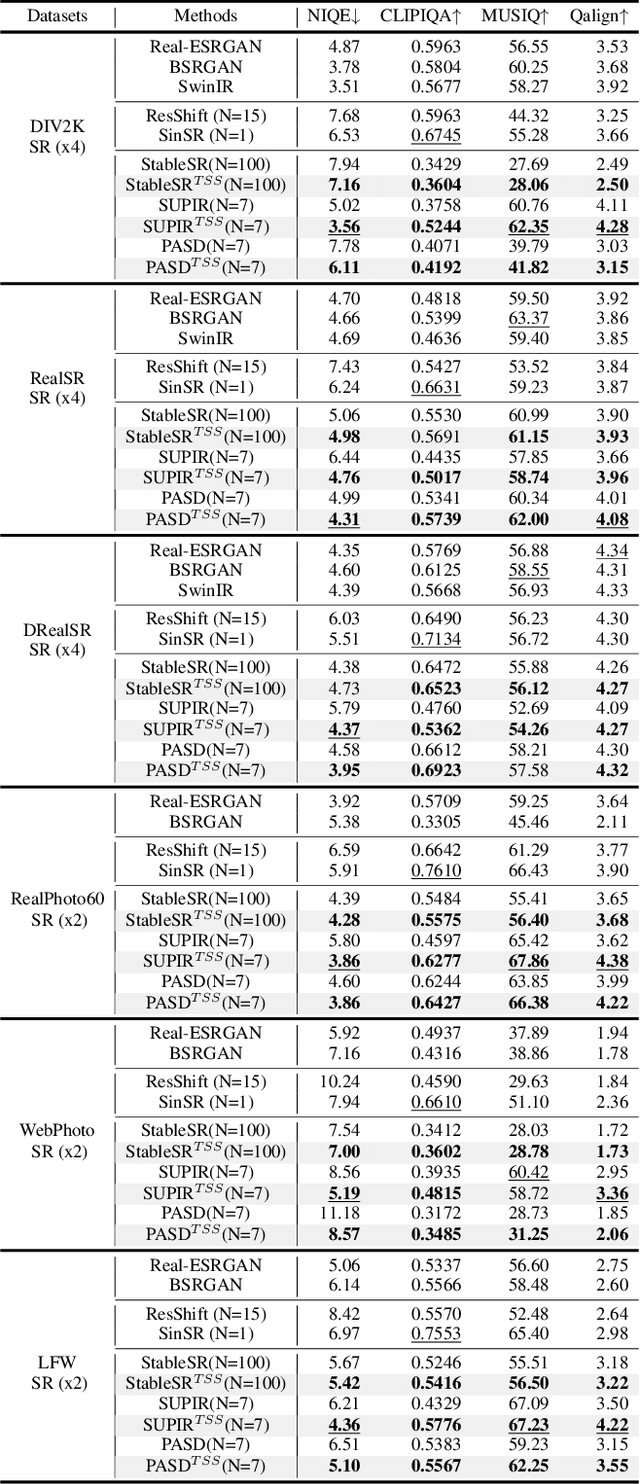
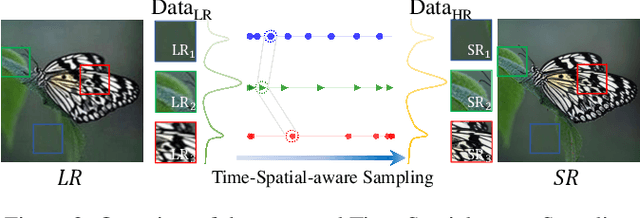
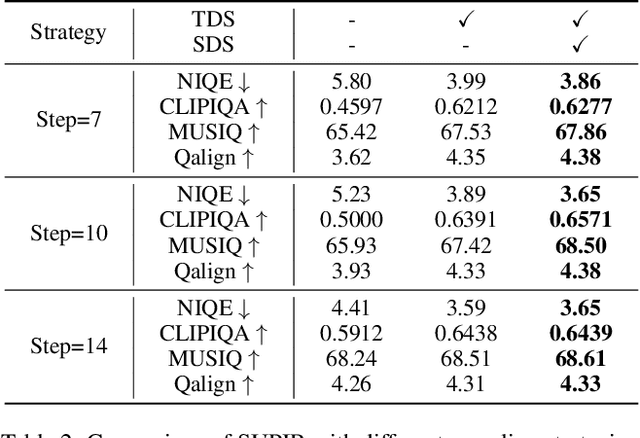
Diffusion models have gained attention for their success in modeling complex distributions, achieving impressive perceptual quality in SR tasks. However, existing diffusion-based SR methods often suffer from high computational costs, requiring numerous iterative steps for training and inference. Existing acceleration techniques, such as distillation and solver optimization, are generally task-agnostic and do not fully leverage the specific characteristics of low-level tasks like super-resolution (SR). In this study, we analyze the frequency- and spatial-domain properties of diffusion-based SR methods, revealing key insights into the temporal and spatial dependencies of high-frequency signal recovery. Specifically, high-frequency details benefit from concentrated optimization during early and late diffusion iterations, while spatially textured regions demand adaptive denoising strategies. Building on these observations, we propose the Time-Spatial-aware Sampling strategy (TSS) for the acceleration of Diffusion SR without any extra training cost. TSS combines Time Dynamic Sampling (TDS), which allocates more iterations to refining textures, and Spatial Dynamic Sampling (SDS), which dynamically adjusts strategies based on image content. Extensive evaluations across multiple benchmarks demonstrate that TSS achieves state-of-the-art (SOTA) performance with significantly fewer iterations, improving MUSIQ scores by 0.2 - 3.0 and outperforming the current acceleration methods with only half the number of steps.
Collaborative Multi-Agent Reinforcement Learning for Automated Feature Transformation with Graph-Driven Path Optimization
Apr 24, 2025



Feature transformation methods aim to find an optimal mathematical feature-feature crossing process that generates high-value features and improves the performance of downstream machine learning tasks. Existing frameworks, though designed to mitigate manual costs, often treat feature transformations as isolated operations, ignoring dynamic dependencies between transformation steps. To address the limitations, we propose TCTO, a collaborative multi-agent reinforcement learning framework that automates feature engineering through graph-driven path optimization. The framework's core innovation lies in an evolving interaction graph that models features as nodes and transformations as edges. Through graph pruning and backtracking, it dynamically eliminates low-impact edges, reduces redundant operations, and enhances exploration stability. This graph also provides full traceability to empower TCTO to reuse high-utility subgraphs from historical transformations. To demonstrate the efficacy and adaptability of our approach, we conduct comprehensive experiments and case studies, which show superior performance across a range of datasets.
Semantic Hierarchical Prompt Tuning for Parameter-Efficient Fine-Tuning
Dec 24, 2024



As the scale of vision models continues to grow, Visual Prompt Tuning (VPT) has emerged as a parameter-efficient transfer learning technique, noted for its superior performance compared to full fine-tuning. However, indiscriminately applying prompts to every layer without considering their inherent correlations, can cause significant disturbances, leading to suboptimal transferability. Additionally, VPT disrupts the original self-attention structure, affecting the aggregation of visual features, and lacks a mechanism for explicitly mining discriminative visual features, which are crucial for classification. To address these issues, we propose a Semantic Hierarchical Prompt (SHIP) fine-tuning strategy. We adaptively construct semantic hierarchies and use semantic-independent and semantic-shared prompts to learn hierarchical representations. We also integrate attribute prompts and a prompt matching loss to enhance feature discrimination and employ decoupled attention for robustness and reduced inference costs. SHIP significantly improves performance, achieving a 4.9% gain in accuracy over VPT with a ViT-B/16 backbone on VTAB-1k tasks. Our code is available at https://github.com/haoweiz23/SHIP.
FTP: A Fine-grained Token-wise Pruner for Large Language Models via Token Routing
Dec 16, 2024Recently, large language models (LLMs) have demonstrated superior performance across various tasks by adhering to scaling laws, which significantly increase model size. However, the huge computation overhead during inference hinders the deployment in industrial applications. Many works leverage traditional compression approaches to boost model inference, but these always introduce additional training costs to restore the performance and the pruning results typically show noticeable performance drops compared to the original model when aiming for a specific level of acceleration. To address these issues, we propose a fine-grained token-wise pruning approach for the LLMs, which presents a learnable router to adaptively identify the less important tokens and skip them across model blocks to reduce computational cost during inference. To construct the router efficiently, we present a search-based sparsity scheduler for pruning sparsity allocation, a trainable router combined with our proposed four low-dimensional factors as input and three proposed losses. We conduct extensive experiments across different benchmarks on different LLMs to demonstrate the superiority of our method. Our approach achieves state-of-the-art (SOTA) pruning results, surpassing other existing pruning methods. For instance, our method outperforms BlockPruner and ShortGPT by approximately 10 points on both LLaMA2-7B and Qwen1.5-7B in accuracy retention at comparable token sparsity levels.
DiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024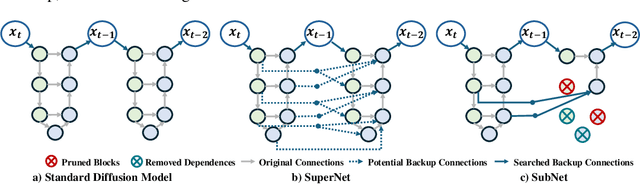
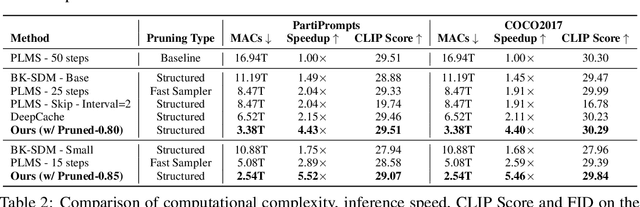
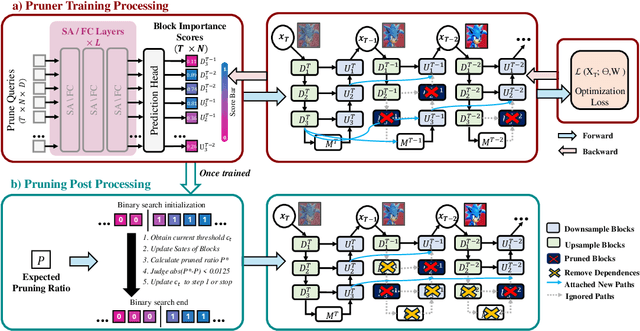

Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.