 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Data Expansion with Diffusion Models
Paper and Code
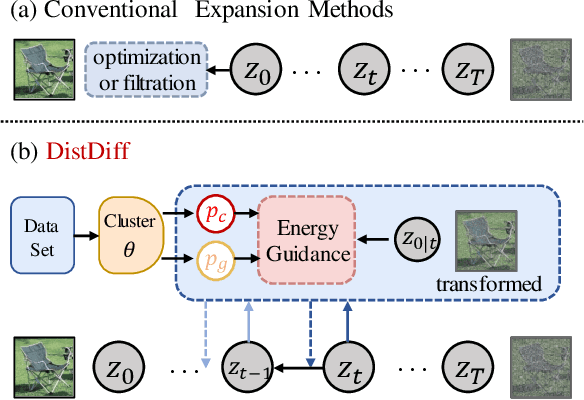

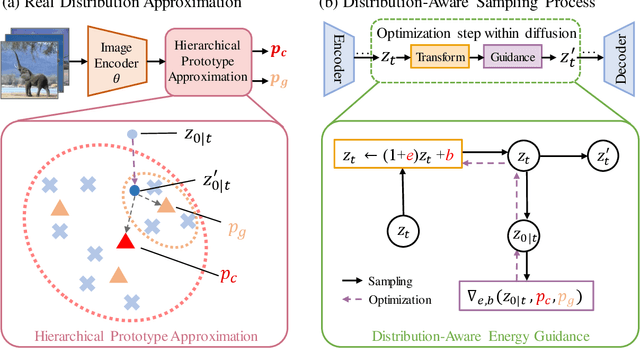
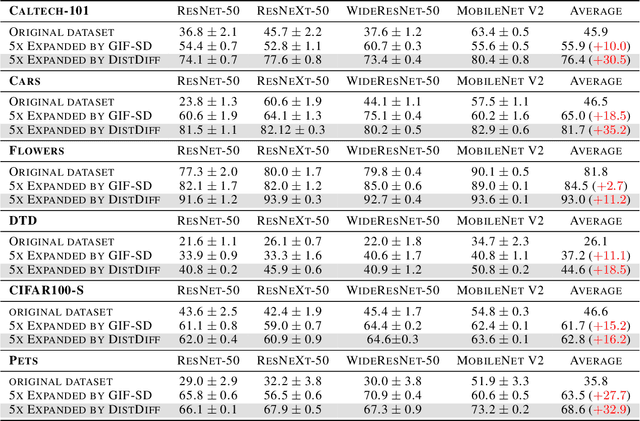
The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion methods encompass image transformation-based and synthesis-based methods. The transformation-based methods introduce only local variations, resulting in poor diversity. While image synthesis-based methods can create entirely new content, significantly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, an effective data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its ability to generate distribution-consistent samples, achieving substantial improvements in data expansion tasks. Specifically, without additional training, DistDiff achieves a 30.7% improvement in accuracy across six image datasets compared to the model trained on original datasets and a 9.8% improvement compared to the state-of-the-art diffusion-based method. Our code is available at https://github.com/haoweiz23/DistDiff