 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCount Anything
May 29, 2026Object counting remains fragmented across domain-specific datasets and task formulations, despite rapid progress in generalist vision models. Existing counting models are often tailored to scenarios such as crowds, vehicles, cells, crops, or remote-sensing objects, and thus struggle to generalize across categories, visual domains, object scales, and density distributions. In this paper, we study text-guided object counting across domains, where a model takes an image and a natural-language query as input and returns an instance-grounded set of target points whose cardinality gives the count. This formulation unifies category-conditioned counting with interpretable spatial localization. To support this setting, we construct CLOC, a Cross-domain Large-scale Object Counting dataset that reorganizes diverse public data sources into a unified benchmark. CLOC covers six visual domains: General Scene, Remote Sensing, Histopathology, Cellular Microscopy, Agriculture, and Microbiology, with about 220K images, 619 categories, and 15M object instances. Based on CLOC, we propose Count Anything, a generalist model for text-guided object counting. Unlike density-map-based methods, which dominate counting models, Count Anything adopts discrete instance points and performs dual-granularity instance enumeration. A Region-level Sparse Counter provides object-level anchors for large and sparse targets, while a Pixel-level Dense Counter handles small, crowded, and weakly bounded targets via dense point prediction. A point-centric supervision strategy enables learning from heterogeneous annotations, and Complementary Count Fusion combines both counters in a parameter-free manner. Extensive experiments show that Count Anything achieves strong accuracy and multi-domain generalization, outperforming existing open-world counting methods. Code is available at: https://github.com/Mengqi-Lei/count-anything.
Hypergraph as Language
May 21, 2026Large language models (LLMs) have recently shown strong potential in modeling relational structures. However, existing approaches remain fundamentally graph-centric: they focus on processing pairwise graph structures into tokens that LLMs can understand. In contrast, many real-world relational patterns do not naturally conform to the pairwise-edge assumption, and are better modeled as high-order associations in hypergraphs. For hypergraph structures, existing methods often fail to preserve the native semantics that multiple objects are jointly connected by the same high-order relation, limiting their ability to exploit complex structures. To address this limitation, we put forth the "Hypergraph as Language" perspective and propose Hyper-Align, a hypergraph-native alignment framework for large language models. Hyper-Align compiles the query-object-centered hypergraph context into hypergraph tokens directly consumable by a base LLM. Specifically, we introduce Hypergraph Incidence Detail Template with Overview (HIDT-O), which serializes high-order association structures into a fixed-shape hybrid template combining local incidence details and overview-level summaries. We then design a Hypergraph Incidence Projector (HIP), which maps native high-order incidence structures into the LLM token space through explicit semantic-structural decoupling and bidirectional message passing between vertices and hyperedges. We further define a concrete Hypergraph-as-Language input protocol, which jointly feeds hypergraph tokens and textual prompts into a frozen base LLM, supporting both vertex-level and hyperedge-level tasks under a unified question-answering paradigm. To systematically evaluate different methods in hypergraph structural modeling, we introduce HyperAlign-Bench. Extensive experiments show that Hyper-Align significantly outperforms existing methods across in-domain and zero-shot evaluations.
Hyper-KGGen: A Skill-Driven Knowledge Extractor for High-Quality Knowledge Hypergraph Generation
Feb 23, 2026Knowledge hypergraphs surpass traditional binary knowledge graphs by encapsulating complex $n$-ary atomic facts, providing a more comprehensive paradigm for semantic representation. However, constructing high-quality hypergraphs remains challenging due to the \textit{scenario gap}: generic extractors struggle to generalize across diverse domains with specific jargon, while existing methods often fail to balance structural skeletons with fine-grained details. To bridge this gap, we propose \textbf{Hyper-KGGen}, a skill-driven framework that reformulates extraction as a dynamic skill-evolving process. First, Hyper-KGGen employs a \textit{coarse-to-fine} mechanism to systematically decompose documents, ensuring full-dimensional coverage from binary links to complex hyperedges. Crucially, it incorporates an \textit{adaptive skill acquisition} module that actively distills domain expertise into a Global Skill Library. This is achieved via a stability-based feedback loop, where extraction stability serves as a relative reward signal to induce high-quality skills from unstable traces and missed predictions. Additionally, we present \textbf{HyperDocRED}, a rigorously annotated benchmark for document-level knowledge hypergraph extraction. Experiments demonstrate that Hyper-KGGen significantly outperforms strong baselines, validating that evolved skills provide substantially richer guidance than static few-shot examples in multi-scenario settings.
DiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024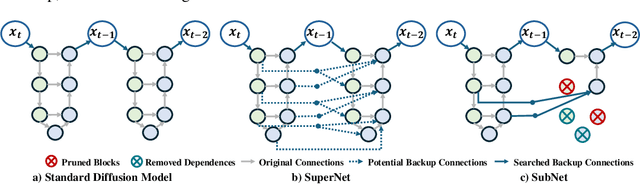
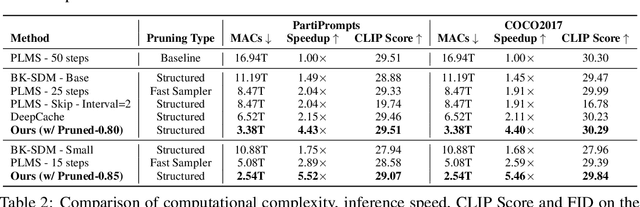
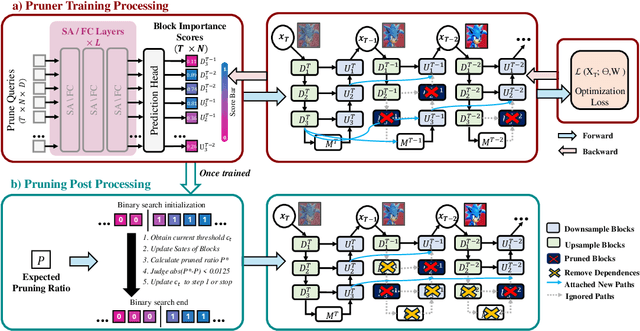

Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
Aug 09, 2024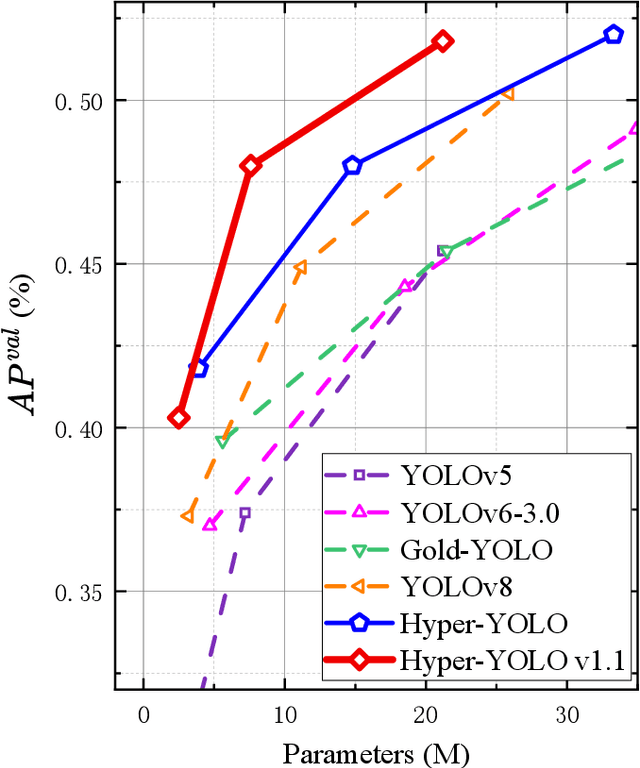
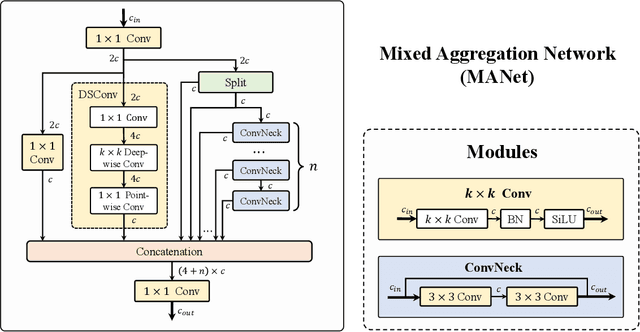
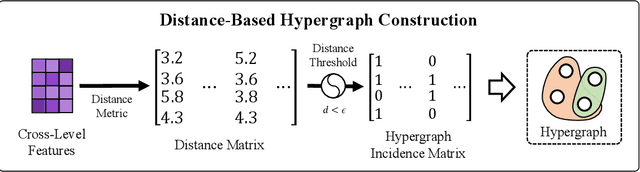
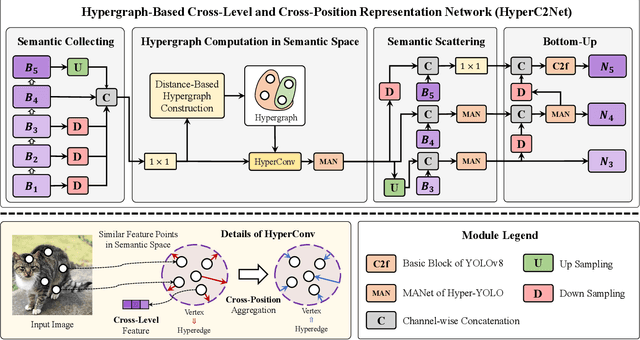
We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-of-the-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, Hyper-YOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12\% $\text{AP}^{val}$ and 9\% $\text{AP}^{val}$ improvements. The source codes are at ttps://github.com/iMoonLab/Hyper-YOLO.
Hand-Object Interaction Controller (HOIC): Deep Reinforcement Learning for Reconstructing Interactions with Physics
May 04, 2024
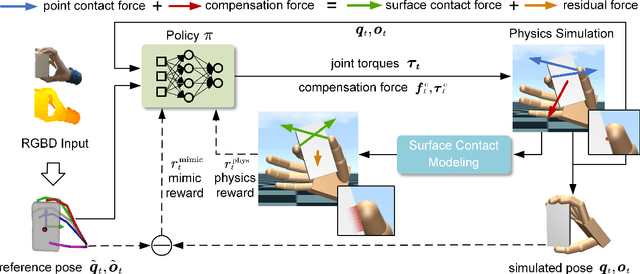
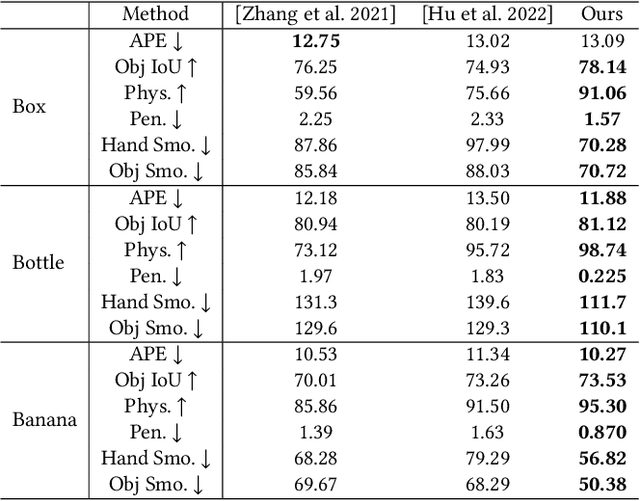
Hand manipulating objects is an important interaction motion in our daily activities. We faithfully reconstruct this motion with a single RGBD camera by a novel deep reinforcement learning method to leverage physics. Firstly, we propose object compensation control which establishes direct object control to make the network training more stable. Meanwhile, by leveraging the compensation force and torque, we seamlessly upgrade the simple point contact model to a more physical-plausible surface contact model, further improving the reconstruction accuracy and physical correctness. Experiments indicate that without involving any heuristic physical rules, this work still successfully involves physics in the reconstruction of hand-object interactions which are complex motions hard to imitate with deep reinforcement learning. Our code and data are available at https://github.com/hu-hy17/HOIC.
Distribution-Aware Data Expansion with Diffusion Models
Mar 11, 2024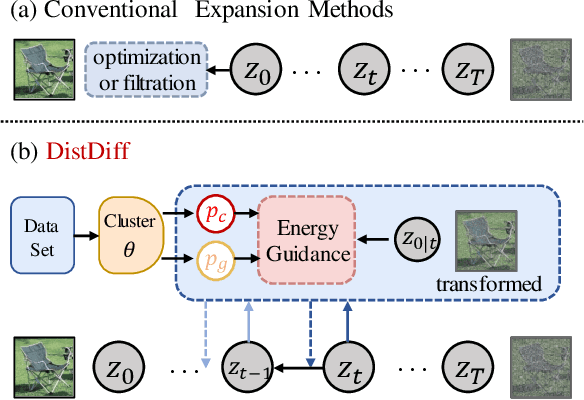

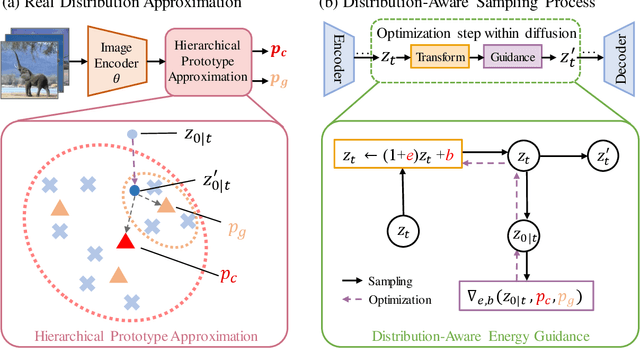
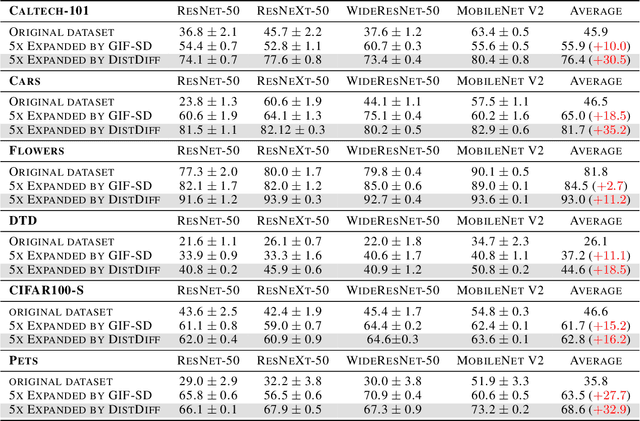
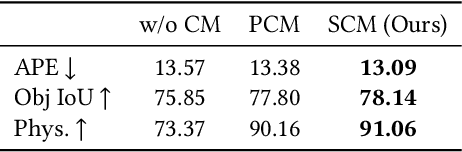
The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion methods encompass image transformation-based and synthesis-based methods. The transformation-based methods introduce only local variations, resulting in poor diversity. While image synthesis-based methods can create entirely new content, significantly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, an effective data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its ability to generate distribution-consistent samples, achieving substantial improvements in data expansion tasks. Specifically, without additional training, DistDiff achieves a 30.7% improvement in accuracy across six image datasets compared to the model trained on original datasets and a 9.8% improvement compared to the state-of-the-art diffusion-based method. Our code is available at https://github.com/haoweiz23/DistDiff
Relightable and Animatable Neural Avatars from Videos
Dec 20, 2023



Lightweight creation of 3D digital avatars is a highly desirable but challenging task. With only sparse videos of a person under unknown illumination, we propose a method to create relightable and animatable neural avatars, which can be used to synthesize photorealistic images of humans under novel viewpoints, body poses, and lighting. The key challenge here is to disentangle the geometry, material of the clothed body, and lighting, which becomes more difficult due to the complex geometry and shadow changes caused by body motions. To solve this ill-posed problem, we propose novel techniques to better model the geometry and shadow changes. For geometry change modeling, we propose an invertible deformation field, which helps to solve the inverse skinning problem and leads to better geometry quality. To model the spatial and temporal varying shading cues, we propose a pose-aware part-wise light visibility network to estimate light occlusion. Extensive experiments on synthetic and real datasets show that our approach reconstructs high-quality geometry and generates realistic shadows under different body poses. Code and data are available at \url{https://wenbin-lin.github.io/RelightableAvatar-page/}.
Focused and Collaborative Feedback Integration for Interactive Image Segmentation
Mar 21, 2023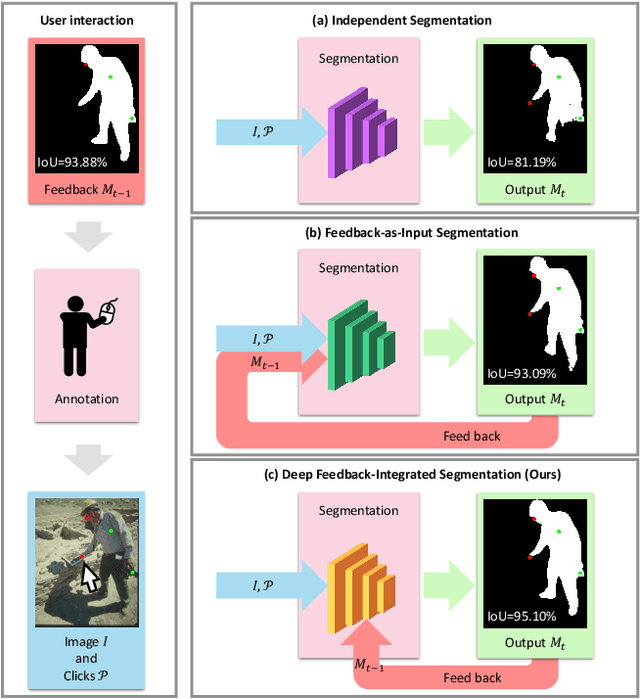
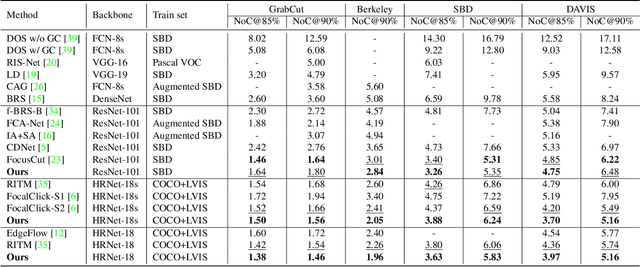


Interactive image segmentation aims at obtaining a segmentation mask for an image using simple user annotations. During each round of interaction, the segmentation result from the previous round serves as feedback to guide the user's annotation and provides dense prior information for the segmentation model, effectively acting as a bridge between interactions. Existing methods overlook the importance of feedback or simply concatenate it with the original input, leading to underutilization of feedback and an increase in the number of required annotations. To address this, we propose an approach called Focused and Collaborative Feedback Integration (FCFI) to fully exploit the feedback for click-based interactive image segmentation. FCFI first focuses on a local area around the new click and corrects the feedback based on the similarities of high-level features. It then alternately and collaboratively updates the feedback and deep features to integrate the feedback into the features. The efficacy and efficiency of FCFI were validated on four benchmarks, namely GrabCut, Berkeley, SBD, and DAVIS. Experimental results show that FCFI achieved new state-of-the-art performance with less computational overhead than previous methods. The source code is available at https://github.com/veizgyauzgyauz/FCFI.
Physical Interaction: Reconstructing Hand-object Interactions with Physics
Sep 22, 2022

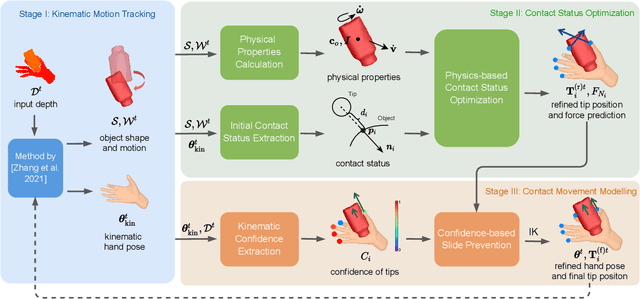

Single view-based reconstruction of hand-object interaction is challenging due to the severe observation missing caused by occlusions. This paper proposes a physics-based method to better solve the ambiguities in the reconstruction. It first proposes a force-based dynamic model of the in-hand object, which not only recovers the unobserved contacts but also solves for plausible contact forces. Next, a confidence-based slide prevention scheme is proposed, which combines both the kinematic confidences and the contact forces to jointly model static and sliding contact motion. Qualitative and quantitative experiments show that the proposed technique reconstructs both physically plausible and more accurate hand-object interaction and estimates plausible contact forces in real-time with a single RGBD sensor.