 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diffeomorphism Groupoid and Algebroid Framework for Discontinuous Image Registration
Mar 12, 2026In this paper, we propose a novel mathematical framework for piecewise diffeomorphic image registration that involves discontinuous sliding motion using a diffeomorphism groupoid and algebroid approach. The traditional Large Deformation Diffeomorphic Metric Mapping (LDDMM) registration method builds on Lie groups, which assume continuity and smoothness in velocity fields, limiting its applicability in handling discontinuous sliding motion. To overcome this limitation, we extend the diffeomorphism Lie groups to a framework of discontinuous diffeomorphism Lie groupoids, allowing for discontinuities along sliding boundaries while maintaining diffeomorphism within homogeneous regions. We provide a rigorous analysis of the associated mathematical structures, including Lie algebroids and their duals, and derive specific Euler-Arnold equations to govern optimal flows for discontinuous deformations. Some numerical tests are performed to validate the efficiency of the proposed approach.
Hyper-KGGen: A Skill-Driven Knowledge Extractor for High-Quality Knowledge Hypergraph Generation
Feb 23, 2026Knowledge hypergraphs surpass traditional binary knowledge graphs by encapsulating complex $n$-ary atomic facts, providing a more comprehensive paradigm for semantic representation. However, constructing high-quality hypergraphs remains challenging due to the \textit{scenario gap}: generic extractors struggle to generalize across diverse domains with specific jargon, while existing methods often fail to balance structural skeletons with fine-grained details. To bridge this gap, we propose \textbf{Hyper-KGGen}, a skill-driven framework that reformulates extraction as a dynamic skill-evolving process. First, Hyper-KGGen employs a \textit{coarse-to-fine} mechanism to systematically decompose documents, ensuring full-dimensional coverage from binary links to complex hyperedges. Crucially, it incorporates an \textit{adaptive skill acquisition} module that actively distills domain expertise into a Global Skill Library. This is achieved via a stability-based feedback loop, where extraction stability serves as a relative reward signal to induce high-quality skills from unstable traces and missed predictions. Additionally, we present \textbf{HyperDocRED}, a rigorously annotated benchmark for document-level knowledge hypergraph extraction. Experiments demonstrate that Hyper-KGGen significantly outperforms strong baselines, validating that evolved skills provide substantially richer guidance than static few-shot examples in multi-scenario settings.
Overlap-aware meta-learning attention to enhance hypergraph neural networks for node classification
Mar 11, 2025
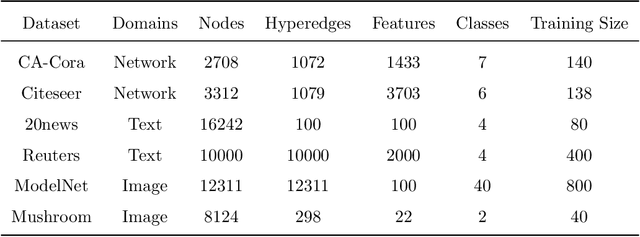
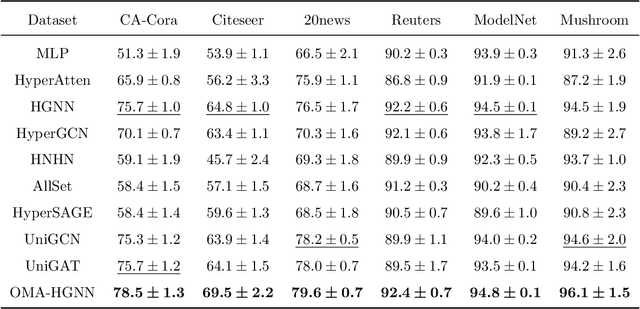
Although hypergraph neural networks (HGNNs) have emerged as a powerful framework for analyzing complex datasets, their practical performance often remains limited. On one hand, existing networks typically employ a single type of attention mechanism, focusing on either structural or feature similarities during message passing. On the other hand, assuming that all nodes in current hypergraph models have the same level of overlap may lead to suboptimal generalization. To overcome these limitations, we propose a novel framework, overlap-aware meta-learning attention for hypergraph neural networks (OMA-HGNN). First, we introduce a hypergraph attention mechanism that integrates both structural and feature similarities. Specifically, we linearly combine their respective losses with weighted factors for the HGNN model. Second, we partition nodes into different tasks based on their diverse overlap levels and develop a multi-task Meta-Weight-Net (MWN) to determine the corresponding weighted factors. Third, we jointly train the internal MWN model with the losses from the external HGNN model and train the external model with the weighted factors from the internal model. To evaluate the effectiveness of OMA-HGNN, we conducted experiments on six real-world datasets and benchmarked its perfor-mance against nine state-of-the-art methods for node classification. The results demonstrate that OMA-HGNN excels in learning superior node representations and outperforms these baselines.
Multi-view Spectral Clustering on the Grassmannian Manifold With Hypergraph Representation
Mar 08, 2025Graph-based multi-view spectral clustering methods have achieved notable progress recently, yet they often fall short in either oversimplifying pairwise relationships or struggling with inefficient spectral decompositions in high-dimensional Euclidean spaces. In this paper, we introduce a novel approach that begins to generate hypergraphs by leveraging sparse representation learning from data points. Based on the generated hypergraph, we propose an optimization function with orthogonality constraints for multi-view hypergraph spectral clustering, which incorporates spectral clustering for each view and ensures consistency across different views. In Euclidean space, solving the orthogonality-constrained optimization problem may yield local maxima and approximation errors. Innovately, we transform this problem into an unconstrained form on the Grassmannian manifold. Finally, we devise an alternating iterative Riemannian optimization algorithm to solve the problem. To validate the effectiveness of the proposed algorithm, we test it on four real-world multi-view datasets and compare its performance with seven state-of-the-art multi-view clustering algorithms. The experimental results demonstrate that our method outperforms the baselines in terms of clustering performance due to its superior low-dimensional and resilient feature representation.
LMS-Net: A Learned Mumford-Shah Network For Few-Shot Medical Image Segmentation
Feb 08, 2025



Few-shot semantic segmentation (FSS) methods have shown great promise in handling data-scarce scenarios, particularly in medical image segmentation tasks. However, most existing FSS architectures lack sufficient interpretability and fail to fully incorporate the underlying physical structures of semantic regions. To address these issues, in this paper, we propose a novel deep unfolding network, called the Learned Mumford-Shah Network (LMS-Net), for the FSS task. Specifically, motivated by the effectiveness of pixel-to-prototype comparison in prototypical FSS methods and the capability of deep priors to model complex spatial structures, we leverage our learned Mumford-Shah model (LMS model) as a mathematical foundation to integrate these insights into a unified framework. By reformulating the LMS model into prototype update and mask update tasks, we propose an alternating optimization algorithm to solve it efficiently. Further, the iterative steps of this algorithm are unfolded into corresponding network modules, resulting in LMS-Net with clear interpretability. Comprehensive experiments on three publicly available medical segmentation datasets verify the effectiveness of our method, demonstrating superior accuracy and robustness in handling complex structures and adapting to challenging segmentation scenarios. These results highlight the potential of LMS-Net to advance FSS in medical imaging applications. Our code will be available at: https://github.com/SDZhang01/LMSNet
Open set label noise learning with robust sample selection and margin-guided module
Jan 08, 2025
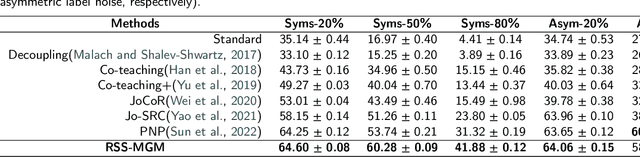
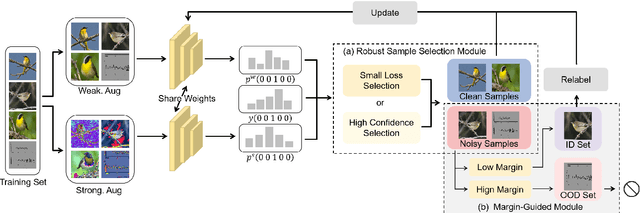
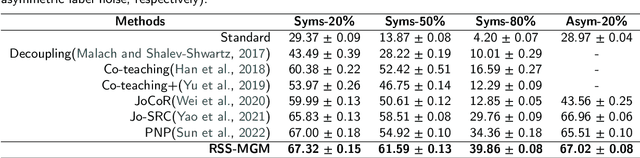
In recent years, the remarkable success of deep neural networks (DNNs) in computer vision is largely due to large-scale, high-quality labeled datasets. Training directly on real-world datasets with label noise may result in overfitting. The traditional method is limited to deal with closed set label noise, where noisy training data has true class labels within the known label space. However, there are some real-world datasets containing open set label noise, which means that some samples belong to an unknown class outside the known label space. To address the open set label noise problem, we introduce a method based on Robust Sample Selection and Margin-Guided Module (RSS-MGM). Firstly, unlike the prior clean sample selection approach, which only select a limited number of clean samples, a robust sample selection module combines small loss selection or high-confidence sample selection to obtain more clean samples. Secondly, to efficiently distinguish open set label noise and closed set ones, margin functions are designed to filter open-set data and closed set data. Thirdly, different processing methods are selected for different types of samples in order to fully utilize the data's prior information and optimize the whole model. Furthermore, extensive experimental results with noisy labeled data from benchmark datasets and real-world datasets, such as CIFAR-100N-C, CIFAR80N-O, WebFG-469, and Food101N, indicate that our approach outperforms many state-of-the-art label noise learning methods. Especially, it can more accurately divide open set label noise samples and closed set ones.
Re-Visible Dual-Domain Self-Supervised Deep Unfolding Network for MRI Reconstruction
Jan 07, 2025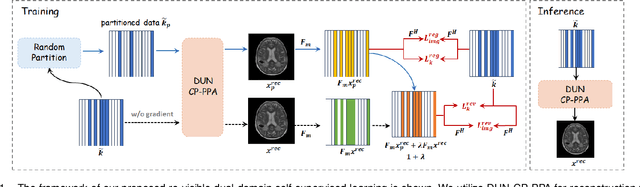



Magnetic Resonance Imaging (MRI) is widely used in clinical practice, but suffered from prolonged acquisition time. Although deep learning methods have been proposed to accelerate acquisition and demonstrate promising performance, they rely on high-quality fully-sampled datasets for training in a supervised manner. However, such datasets are time-consuming and expensive-to-collect, which constrains their broader applications. On the other hand, self-supervised methods offer an alternative by enabling learning from under-sampled data alone, but most existing methods rely on further partitioned under-sampled k-space data as model's input for training, resulting in a loss of valuable information. Additionally, their models have not fully incorporated image priors, leading to degraded reconstruction performance. In this paper, we propose a novel re-visible dual-domain self-supervised deep unfolding network to address these issues when only under-sampled datasets are available. Specifically, by incorporating re-visible dual-domain loss, all under-sampled k-space data are utilized during training to mitigate information loss caused by further partitioning. This design enables the model to implicitly adapt to all under-sampled k-space data as input. Additionally, we design a deep unfolding network based on Chambolle and Pock Proximal Point Algorithm (DUN-CP-PPA) to achieve end-to-end reconstruction, incorporating imaging physics and image priors to guide the reconstruction process. By employing a Spatial-Frequency Feature Extraction (SFFE) block to capture global and local feature representation, we enhance the model's efficiency to learn comprehensive image priors. Experiments conducted on the fastMRI and IXI datasets demonstrate that our method significantly outperforms state-of-the-art approaches in terms of reconstruction performance.
Beyond Graphs: Can Large Language Models Comprehend Hypergraphs?
Oct 14, 2024



Existing benchmarks like NLGraph and GraphQA evaluate LLMs on graphs by focusing mainly on pairwise relationships, overlooking the high-order correlations found in real-world data. Hypergraphs, which can model complex beyond-pairwise relationships, offer a more robust framework but are still underexplored in the context of LLMs. To address this gap, we introduce LLM4Hypergraph, the first comprehensive benchmark comprising 21,500 problems across eight low-order, five high-order, and two isomorphism tasks, utilizing both synthetic and real-world hypergraphs from citation networks and protein structures. We evaluate six prominent LLMs, including GPT-4o, demonstrating our benchmark's effectiveness in identifying model strengths and weaknesses. Our specialized prompting framework incorporates seven hypergraph languages and introduces two novel techniques, Hyper-BAG and Hyper-COT, which enhance high-order reasoning and achieve an average 4% (up to 9%) performance improvement on structure classification tasks. This work establishes a foundational testbed for integrating hypergraph computational capabilities into LLMs, advancing their comprehension.
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
Aug 09, 2024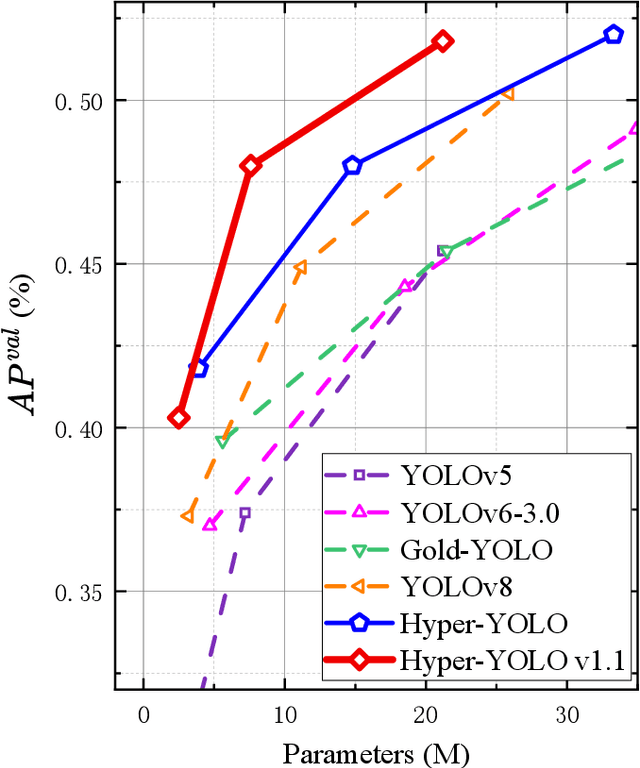
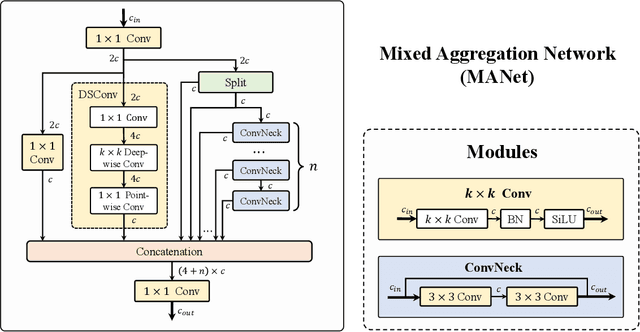
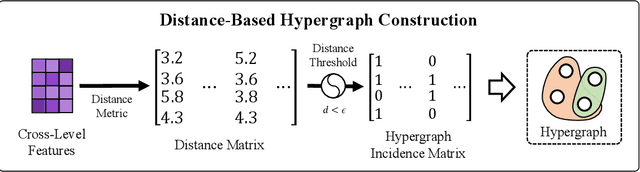
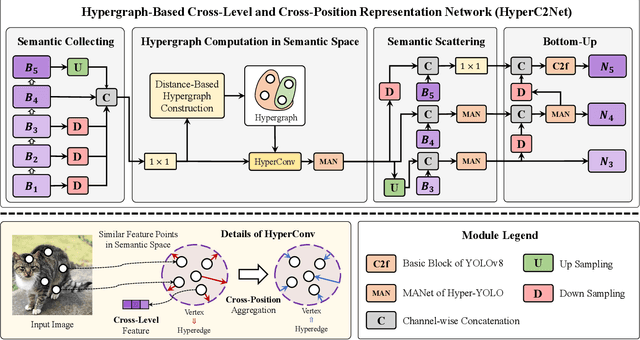
We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-of-the-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, Hyper-YOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12\% $\text{AP}^{val}$ and 9\% $\text{AP}^{val}$ improvements. The source codes are at ttps://github.com/iMoonLab/Hyper-YOLO.
LightHGNN: Distilling Hypergraph Neural Networks into MLPs for $100\times$ Faster Inference
Feb 18, 2024



Hypergraph Neural Networks (HGNNs) have recently attracted much attention and exhibited satisfactory performance due to their superiority in high-order correlation modeling. However, it is noticed that the high-order modeling capability of hypergraph also brings increased computation complexity, which hinders its practical industrial deployment. In practice, we find that one key barrier to the efficient deployment of HGNNs is the high-order structural dependencies during inference. In this paper, we propose to bridge the gap between the HGNNs and inference-efficient Multi-Layer Perceptron (MLPs) to eliminate the hypergraph dependency of HGNNs and thus reduce computational complexity as well as improve inference speed. Specifically, we introduce LightHGNN and LightHGNN$^+$ for fast inference with low complexity. LightHGNN directly distills the knowledge from teacher HGNNs to student MLPs via soft labels, and LightHGNN$^+$ further explicitly injects reliable high-order correlations into the student MLPs to achieve topology-aware distillation and resistance to over-smoothing. Experiments on eight hypergraph datasets demonstrate that even without hypergraph dependency, the proposed LightHGNNs can still achieve competitive or even better performance than HGNNs and outperform vanilla MLPs by $16.3$ on average. Extensive experiments on three graph datasets further show the average best performance of our LightHGNNs compared with all other methods. Experiments on synthetic hypergraphs with 5.5w vertices indicate LightHGNNs can run $100\times$ faster than HGNNs, showcasing their ability for latency-sensitive deployments.