 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAoE: Always-on Egocentric Human Video Collection for Embodied AI
Mar 02, 2026Embodied foundation models require large-scale, high-quality real-world interaction data for pre-training and scaling. However, existing data collection methods suffer from high infrastructure costs, complex hardware dependencies, and limited interaction scope, making scalable expansion challenging. In fact, humans themselves are ideal physically embodied agents. Therefore, obtaining egocentric real-world interaction data from globally distributed "human agents" offers advantages of low cost and sustainability. To this end, we propose the Always-on Egocentric (AoE) data collection system, which aims to simplify hardware dependencies by leveraging humans themselves and their smartphones, enabling low-cost, highly efficient, and scene-agnostic real-world interaction data collection to address the challenge of data scarcity. Specifically, we first employ an ergonomic neck-mounted smartphone holder to enable low-barrier, large-scale egocentric data collection through a cloud-edge collaborative architecture. Second, we develop a cross-platform mobile APP that leverages on-device compute for real-time processing, while the cloud hosts automated labeling and filtering pipelines that transform raw videos into high-quality training data. Finally, the AoE system supports distributed Ego video data collection by anyone, anytime, and anywhere. We evaluate AoE on data preprocessing quality and downstream tasks, demonstrating that high-quality egocentric data significantly boosts real-world generalization.
AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
Causal-Guided Detoxify Backdoor Attack of Open-Weight LoRA Models
Dec 22, 2025Low-Rank Adaptation (LoRA) has emerged as an efficient method for fine-tuning large language models (LLMs) and is widely adopted within the open-source community. However, the decentralized dissemination of LoRA adapters through platforms such as Hugging Face introduces novel security vulnerabilities: malicious adapters can be easily distributed and evade conventional oversight mechanisms. Despite these risks, backdoor attacks targeting LoRA-based fine-tuning remain relatively underexplored. Existing backdoor attack strategies are ill-suited to this setting, as they often rely on inaccessible training data, fail to account for the structural properties unique to LoRA, or suffer from high false trigger rates (FTR), thereby compromising their stealth. To address these challenges, we propose Causal-Guided Detoxify Backdoor Attack (CBA), a novel backdoor attack framework specifically designed for open-weight LoRA models. CBA operates without access to original training data and achieves high stealth through two key innovations: (1) a coverage-guided data generation pipeline that synthesizes task-aligned inputs via behavioral exploration, and (2) a causal-guided detoxification strategy that merges poisoned and clean adapters by preserving task-critical neurons. Unlike prior approaches, CBA enables post-training control over attack intensity through causal influence-based weight allocation, eliminating the need for repeated retraining. Evaluated across six LoRA models, CBA achieves high attack success rates while reducing FTR by 50-70\% compared to baseline methods. Furthermore, it demonstrates enhanced resistance to state-of-the-art backdoor defenses, highlighting its stealth and robustness.
LFD: Layer Fused Decoding to Exploit External Knowledge in Retrieval-Augmented Generation
Aug 27, 2025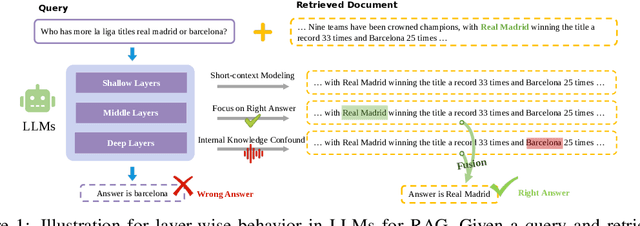
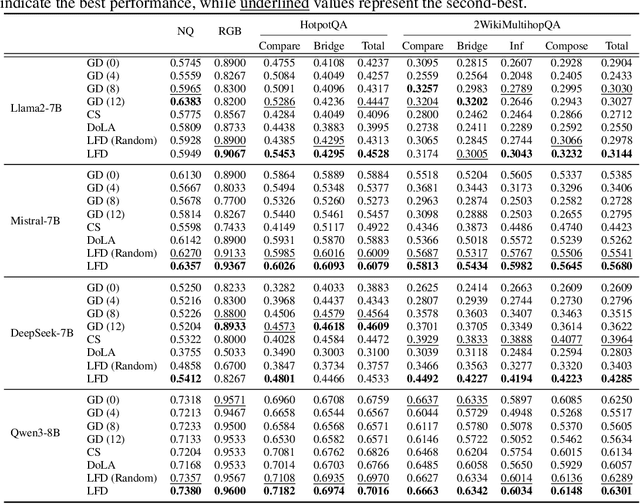
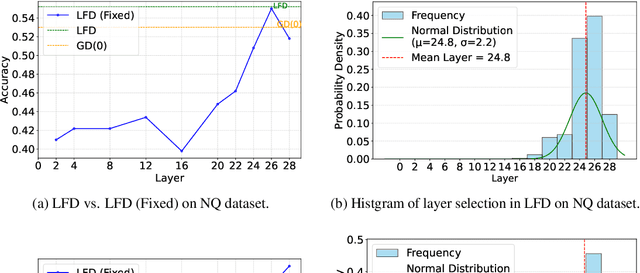

Retrieval-augmented generation (RAG) incorporates external knowledge into large language models (LLMs), improving their adaptability to downstream tasks and enabling information updates. Surprisingly, recent empirical evidence demonstrates that injecting noise into retrieved relevant documents paradoxically facilitates exploitation of external knowledge and improves generation quality. Although counterintuitive and challenging to apply in practice, this phenomenon enables granular control and rigorous analysis of how LLMs integrate external knowledge. Therefore, in this paper, we intervene on noise injection and establish a layer-specific functional demarcation within the LLM: shallow layers specialize in local context modeling, intermediate layers focus on integrating long-range external factual knowledge, and deeper layers primarily rely on parametric internal knowledge. Building on this insight, we propose Layer Fused Decoding (LFD), a simple decoding strategy that directly combines representations from an intermediate layer with final-layer decoding outputs to fully exploit the external factual knowledge. To identify the optimal intermediate layer, we introduce an internal knowledge score (IKS) criterion that selects the layer with the lowest IKS value in the latter half of layers. Experimental results across multiple benchmarks demonstrate that LFD helps RAG systems more effectively surface retrieved context knowledge with minimal cost.
CodeContests+: High-Quality Test Case Generation for Competitive Programming
Jun 06, 2025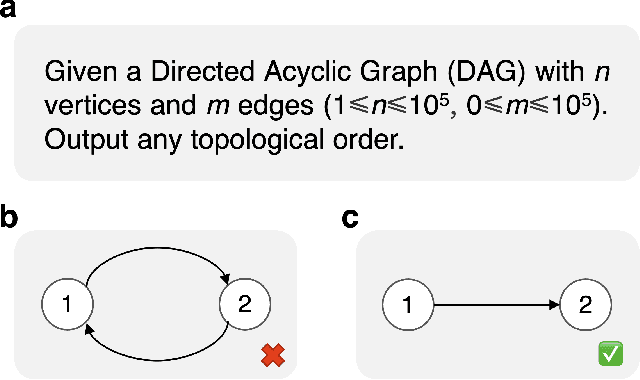
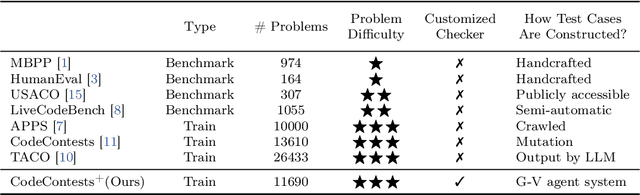
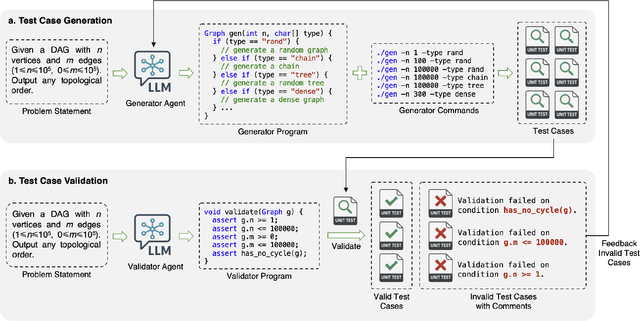
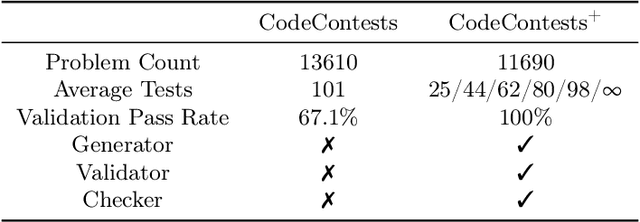
Competitive programming, due to its high reasoning difficulty and precise correctness feedback, has become a key task for both training and evaluating the reasoning capabilities of large language models (LLMs). However, while a large amount of public problem data, such as problem statements and solutions, is available, the test cases of these problems are often difficult to obtain. Therefore, test case generation is a necessary task for building large-scale datasets, and the quality of the test cases directly determines the accuracy of the evaluation. In this paper, we introduce an LLM-based agent system that creates high-quality test cases for competitive programming problems. We apply this system to the CodeContests dataset and propose a new version with improved test cases, named CodeContests+. We evaluated the quality of test cases in CodeContestsPlus. First, we used 1.72 million submissions with pass/fail labels to examine the accuracy of these test cases in evaluation. The results indicated that CodeContests+ achieves significantly higher accuracy than CodeContests, particularly with a notably higher True Positive Rate (TPR). Subsequently, our experiments in LLM Reinforcement Learning (RL) further confirmed that improvements in test case quality yield considerable advantages for RL.
Graph-Reward-SQL: Execution-Free Reinforcement Learning for Text-to-SQL via Graph Matching and Stepwise Reward
May 18, 2025Reinforcement learning (RL) has been widely adopted to enhance the performance of large language models (LLMs) on Text-to-SQL tasks. However, existing methods often rely on execution-based or LLM-based Bradley-Terry reward models. The former suffers from high execution latency caused by repeated database calls, whereas the latter imposes substantial GPU memory overhead, both of which significantly hinder the efficiency and scalability of RL pipelines. To this end, we propose a novel Text-to-SQL RL fine-tuning framework named Graph-Reward-SQL, which employs the GMNScore outcome reward model. We leverage SQL graph representations to provide accurate reward signals while significantly reducing inference time and GPU memory usage. Building on this foundation, we further introduce StepRTM, a stepwise reward model that provides intermediate supervision over Common Table Expression (CTE) subqueries. This encourages both functional correctness and structural clarity of SQL. Extensive comparative and ablation experiments on standard benchmarks, including Spider and BIRD, demonstrate that our method consistently outperforms existing reward models.
DPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving
Apr 23, 2025



Modern robots must coexist with humans in dense urban environments. A key challenge is the ghost probe problem, where pedestrians or objects unexpectedly rush into traffic paths. This issue affects both autonomous vehicles and human drivers. Existing works propose vehicle-to-everything (V2X) strategies and non-line-of-sight (NLOS) imaging for ghost probe zone detection. However, most require high computational power or specialized hardware, limiting real-world feasibility. Additionally, many methods do not explicitly address this issue. To tackle this, we propose DPGP, a hybrid 2D-3D fusion framework for ghost probe zone prediction using only a monocular camera during training and inference. With unsupervised depth prediction, we observe ghost probe zones align with depth discontinuities, but different depth representations offer varying robustness. To exploit this, we fuse multiple feature embeddings to improve prediction. To validate our approach, we created a 12K-image dataset annotated with ghost probe zones, carefully sourced and cross-checked for accuracy. Experimental results show our framework outperforms existing methods while remaining cost-effective. To our knowledge, this is the first work extending ghost probe zone prediction beyond vehicles, addressing diverse non-vehicle objects. We will open-source our code and dataset for community benefit.
Open set label noise learning with robust sample selection and margin-guided module
Jan 08, 2025
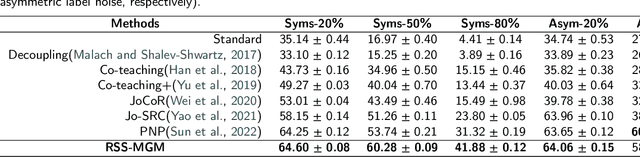
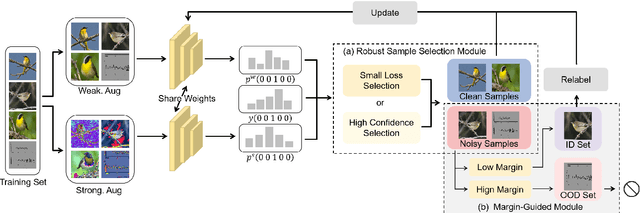
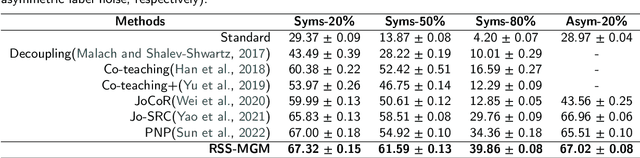
In recent years, the remarkable success of deep neural networks (DNNs) in computer vision is largely due to large-scale, high-quality labeled datasets. Training directly on real-world datasets with label noise may result in overfitting. The traditional method is limited to deal with closed set label noise, where noisy training data has true class labels within the known label space. However, there are some real-world datasets containing open set label noise, which means that some samples belong to an unknown class outside the known label space. To address the open set label noise problem, we introduce a method based on Robust Sample Selection and Margin-Guided Module (RSS-MGM). Firstly, unlike the prior clean sample selection approach, which only select a limited number of clean samples, a robust sample selection module combines small loss selection or high-confidence sample selection to obtain more clean samples. Secondly, to efficiently distinguish open set label noise and closed set ones, margin functions are designed to filter open-set data and closed set data. Thirdly, different processing methods are selected for different types of samples in order to fully utilize the data's prior information and optimize the whole model. Furthermore, extensive experimental results with noisy labeled data from benchmark datasets and real-world datasets, such as CIFAR-100N-C, CIFAR80N-O, WebFG-469, and Food101N, indicate that our approach outperforms many state-of-the-art label noise learning methods. Especially, it can more accurately divide open set label noise samples and closed set ones.
Learning Implicit Features with Flow Infused Attention for Realistic Virtual Try-On
Dec 16, 2024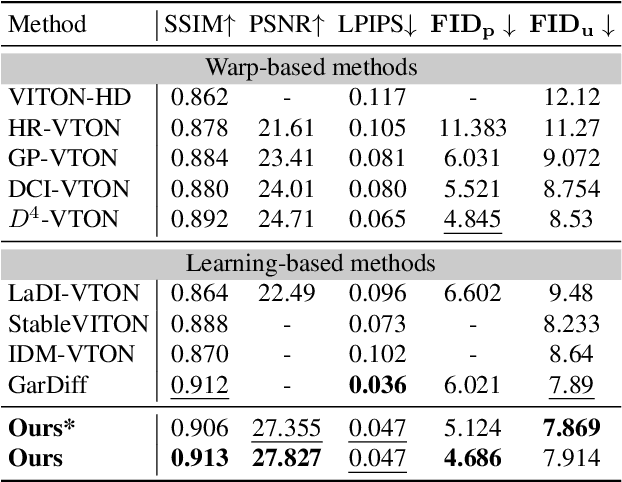
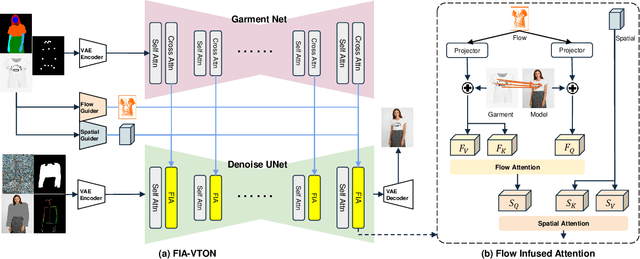
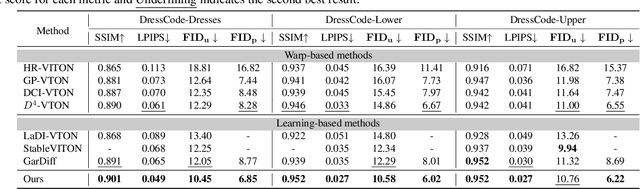

Image-based virtual try-on is challenging since the generated image should fit the garment to model images in various poses and keep the characteristics and details of the garment simultaneously. A popular research stream warps the garment image firstly to reduce the burden of the generation stage, which relies highly on the performance of the warping module. Other methods without explicit warping often lack sufficient guidance to fit the garment to the model images. In this paper, we propose FIA-VTON, which leverages the implicit warp feature by adopting a Flow Infused Attention module on virtual try-on. The dense warp flow map is projected as indirect guidance attention to enhance the feature map warping in the generation process implicitly, which is less sensitive to the warping estimation accuracy than an explicit warp of the garment image. To further enhance implicit warp guidance, we incorporate high-level spatial attention to complement the dense warp. Experimental results on the VTON-HD and DressCode dataset significantly outperform state-of-the-art methods, demonstrating that FIA-VTON is effective and robust for virtual try-on.
Complex-Cycle-Consistent Diffusion Model for Monaural Speech Enhancement
Dec 12, 2024



In this paper, we present a novel diffusion model-based monaural speech enhancement method. Our approach incorporates the separate estimation of speech spectra's magnitude and phase in two diffusion networks. Throughout the diffusion process, noise clips from real-world noise interferences are added gradually to the clean speech spectra and a noise-aware reverse process is proposed to learn how to generate both clean speech spectra and noise spectra. Furthermore, to fully leverage the intrinsic relationship between magnitude and phase, we introduce a complex-cycle-consistent (CCC) mechanism that uses the estimated magnitude to map the phase, and vice versa. We implement this algorithm within a phase-aware speech enhancement diffusion model (SEDM). We conduct extensive experiments on public datasets to demonstrate the effectiveness of our method, highlighting the significant benefits of exploiting the intrinsic relationship between phase and magnitude information to enhance speech. The comparison to conventional diffusion models demonstrates the superiority of SEDM.