 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
Feb 11, 2026Existing multimodal retrieval systems excel at semantic matching but implicitly assume that query-image relevance can be measured in isolation. This paradigm overlooks the rich dependencies inherent in realistic visual streams, where information is distributed across temporal sequences rather than confined to single snapshots. To bridge this gap, we introduce DeepImageSearch, a novel agentic paradigm that reformulates image retrieval as an autonomous exploration task. Models must plan and perform multi-step reasoning over raw visual histories to locate targets based on implicit contextual cues. We construct DISBench, a challenging benchmark built on interconnected visual data. To address the scalability challenge of creating context-dependent queries, we propose a human-model collaborative pipeline that employs vision-language models to mine latent spatiotemporal associations, effectively offloading intensive context discovery before human verification. Furthermore, we build a robust baseline using a modular agent framework equipped with fine-grained tools and a dual-memory system for long-horizon navigation. Extensive experiments demonstrate that DISBench poses significant challenges to state-of-the-art models, highlighting the necessity of incorporating agentic reasoning into next-generation retrieval systems.
Graph-Reward-SQL: Execution-Free Reinforcement Learning for Text-to-SQL via Graph Matching and Stepwise Reward
May 18, 2025Reinforcement learning (RL) has been widely adopted to enhance the performance of large language models (LLMs) on Text-to-SQL tasks. However, existing methods often rely on execution-based or LLM-based Bradley-Terry reward models. The former suffers from high execution latency caused by repeated database calls, whereas the latter imposes substantial GPU memory overhead, both of which significantly hinder the efficiency and scalability of RL pipelines. To this end, we propose a novel Text-to-SQL RL fine-tuning framework named Graph-Reward-SQL, which employs the GMNScore outcome reward model. We leverage SQL graph representations to provide accurate reward signals while significantly reducing inference time and GPU memory usage. Building on this foundation, we further introduce StepRTM, a stepwise reward model that provides intermediate supervision over Common Table Expression (CTE) subqueries. This encourages both functional correctness and structural clarity of SQL. Extensive comparative and ablation experiments on standard benchmarks, including Spider and BIRD, demonstrate that our method consistently outperforms existing reward models.
On Diversified Preferences of Large Language Model Alignment
Dec 25, 2023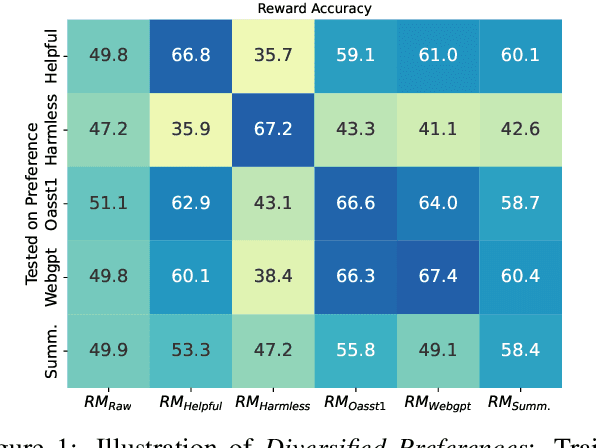
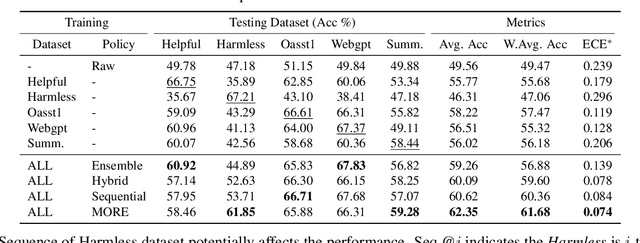
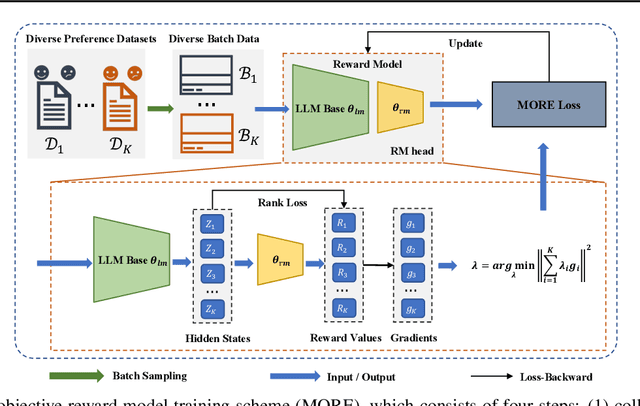
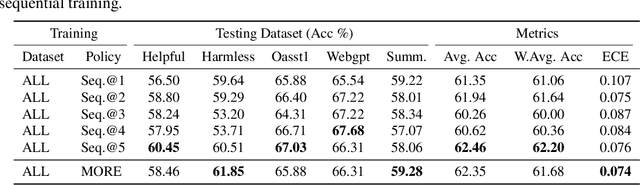
Aligning large language models (LLMs) with human preferences has been recognized as the key to improving LLMs' interaction quality. However, in this pluralistic world, human preferences can be diversified by people's different tastes, which hinders the effectiveness of LLM alignment methods. In this paper, we provide the first quantitative analysis to verify the existence of diversified preferences in commonly used human feedback datasets. To mitigate the alignment ineffectiveness caused by diversified preferences, we propose a novel \textbf{M}ulti-\textbf{O}bjective \textbf{Re}ward learning method (MORE), which can automatically adjust the learning gradients across different preference data sources. In experiments, we evaluate MORE with the Pythia-1.4B model on five mixed human preference datasets, on which our method achieves superior performance compared with other baselines in terms of preference accuracy and prediction calibration.
Topology Learning for Heterogeneous Decentralized Federated Learning over Unreliable D2D Networks
Dec 21, 2023
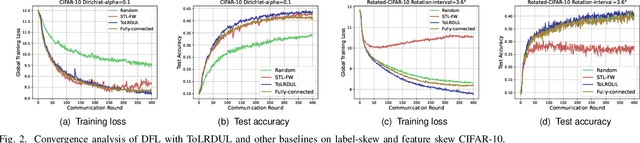
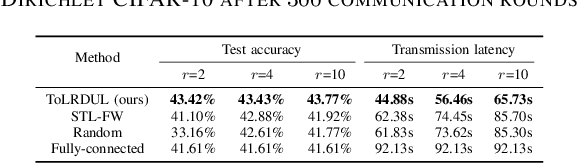
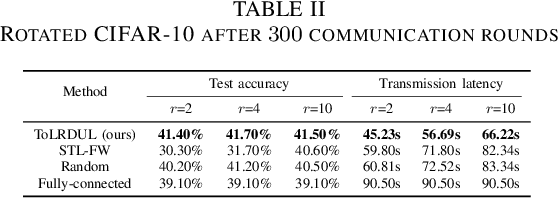
With the proliferation of intelligent mobile devices in wireless device-to-device (D2D) networks, decentralized federated learning (DFL) has attracted significant interest. Compared to centralized federated learning (CFL), DFL mitigates the risk of central server failures due to communication bottlenecks. However, DFL faces several challenges, such as the severe heterogeneity of data distributions in diverse environments, and the transmission outages and package errors caused by the adoption of the User Datagram Protocol (UDP) in D2D networks. These challenges often degrade the convergence of training DFL models. To address these challenges, we conduct a thorough theoretical convergence analysis for DFL and derive a convergence bound. By defining a novel quantity named unreliable links-aware neighborhood discrepancy in this convergence bound, we formulate a tractable optimization objective, and develop a novel Topology Learning method considering the Representation Discrepancy and Unreliable Links in DFL, named ToLRDUL. Intensive experiments under both feature skew and label skew settings have validated the effectiveness of our proposed method, demonstrating improved convergence speed and test accuracy, consistent with our theoretical findings.
Federated Knowledge Graph Completion via Latent Embedding Sharing and Tensor Factorization
Nov 17, 2023Knowledge graphs (KGs), which consist of triples, are inherently incomplete and always require completion procedure to predict missing triples. In real-world scenarios, KGs are distributed across clients, complicating completion tasks due to privacy restrictions. Many frameworks have been proposed to address the issue of federated knowledge graph completion. However, the existing frameworks, including FedE, FedR, and FEKG, have certain limitations. = FedE poses a risk of information leakage, FedR's optimization efficacy diminishes when there is minimal overlap among relations, and FKGE suffers from computational costs and mode collapse issues. To address these issues, we propose a novel method, i.e., Federated Latent Embedding Sharing Tensor factorization (FLEST), which is a novel approach using federated tensor factorization for KG completion. FLEST decompose the embedding matrix and enables sharing of latent dictionary embeddings to lower privacy risks. Empirical results demonstrate FLEST's effectiveness and efficiency, offering a balanced solution between performance and privacy. FLEST expands the application of federated tensor factorization in KG completion tasks.
Federated Generalization via Information-Theoretic Distribution Diversification
Oct 13, 2023Federated Learning (FL) has surged in prominence due to its capability of collaborative model training without direct data sharing. However, the vast disparity in local data distributions among clients, often termed the non-Independent Identically Distributed (non-IID) challenge, poses a significant hurdle to FL's generalization efficacy. The scenario becomes even more complex when not all clients participate in the training process, a common occurrence due to unstable network connections or limited computational capacities. This can greatly complicate the assessment of the trained models' generalization abilities. While a plethora of recent studies has centered on the generalization gap pertaining to unseen data from participating clients with diverse distributions, the divergence between the training distributions of participating clients and the testing distributions of non-participating ones has been largely overlooked. In response, our paper unveils an information-theoretic generalization framework for FL. Specifically, it quantifies generalization errors by evaluating the information entropy of local distributions and discerning discrepancies across these distributions. Inspired by our deduced generalization bounds, we introduce a weighted aggregation approach and a duo of client selection strategies. These innovations aim to bolster FL's generalization prowess by encompassing a more varied set of client data distributions. Our extensive empirical evaluations reaffirm the potency of our proposed methods, aligning seamlessly with our theoretical construct.
Exploring Federated Optimization by Reducing Variance of Adaptive Unbiased Client Sampling
Oct 04, 2023Federated Learning (FL) systems usually sample a fraction of clients to conduct a training process. Notably, the variance of global estimates for updating the global model built on information from sampled clients is highly related to federated optimization quality. This paper explores a line of "free" adaptive client sampling techniques in federated optimization, where the server builds promising sampling probability and reliable global estimates without requiring additional local communication and computation. We capture a minor variant in the sampling procedure and improve the global estimation accordingly. Based on that, we propose a novel sampler called K-Vib, which solves an online convex optimization respecting client sampling in federated optimization. It achieves improved a linear speed up on regret bound $\tilde{\mathcal{O}}\big(N^{\frac{1}{3}}T^{\frac{2}{3}}/K^{\frac{4}{3}}\big)$ with communication budget $K$. As a result, it significantly improves the performance of federated optimization. Theoretical improvements and intensive experiments on classic federated tasks demonstrate our findings.
Tackling Hybrid Heterogeneity on Federated Optimization via Gradient Diversity Maximization
Oct 04, 2023Federated learning refers to a distributed machine learning paradigm in which data samples are decentralized and distributed among multiple clients. These samples may exhibit statistical heterogeneity, which refers to data distributions are not independent and identical across clients. Additionally, system heterogeneity, or variations in the computational power of the clients, introduces biases into federated learning. The combined effects of statistical and system heterogeneity can significantly reduce the efficiency of federated optimization. However, the impact of hybrid heterogeneity is not rigorously discussed. This paper explores how hybrid heterogeneity affects federated optimization by investigating server-side optimization. The theoretical results indicate that adaptively maximizing gradient diversity in server update direction can help mitigate the potential negative consequences of hybrid heterogeneity. To this end, we introduce a novel server-side gradient-based optimizer \textsc{FedAWARE} with theoretical guarantees provided. Intensive experiments in heterogeneous federated settings demonstrate that our proposed optimizer can significantly enhance the performance of federated learning across varying degrees of hybrid heterogeneity.
Personalized Federated Learning via Amortized Bayesian Meta-Learning
Jul 05, 2023Federated learning is a decentralized and privacy-preserving technique that enables multiple clients to collaborate with a server to learn a global model without exposing their private data. However, the presence of statistical heterogeneity among clients poses a challenge, as the global model may struggle to perform well on each client's specific task. To address this issue, we introduce a new perspective on personalized federated learning through Amortized Bayesian Meta-Learning. Specifically, we propose a novel algorithm called \emph{FedABML}, which employs hierarchical variational inference across clients. The global prior aims to capture representations of common intrinsic structures from heterogeneous clients, which can then be transferred to their respective tasks and aid in the generation of accurate client-specific approximate posteriors through a few local updates. Our theoretical analysis provides an upper bound on the average generalization error and guarantees the generalization performance on unseen data. Finally, several empirical results are implemented to demonstrate that \emph{FedABML} outperforms several competitive baselines.
FedNoisy: Federated Noisy Label Learning Benchmark
Jun 20, 2023Federated learning has gained popularity for distributed learning without aggregating sensitive data from clients. But meanwhile, the distributed and isolated nature of data isolation may be complicated by data quality, making it more vulnerable to noisy labels. Many efforts exist to defend against the negative impacts of noisy labels in centralized or federated settings. However, there is a lack of a benchmark that comprehensively considers the impact of noisy labels in a wide variety of typical FL settings. In this work, we serve the first standardized benchmark that can help researchers fully explore potential federated noisy settings. Also, we conduct comprehensive experiments to explore the characteristics of these data settings and unravel challenging scenarios on the federated noisy label learning, which may guide method development in the future. We highlight the 20 basic settings for more than 5 datasets proposed in our benchmark and standardized simulation pipeline for federated noisy label learning. We hope this benchmark can facilitate idea verification in federated learning with noisy labels. \texttt{FedNoisy} is available at \codeword{https://github.com/SMILELab-FL/FedNoisy}.