 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving EHR Data Transformation via Geometric Operators: A Human-AI Co-Design Technical Report
Mar 24, 2026Electronic health records (EHRs) and other real-world clinical data are essential for clinical research, medical artificial intelligence, and life science, but their sharing is severely limited by privacy, governance, and interoperability constraints. These barriers create persistent data silos that hinder multi-center studies, large-scale model development, and broader biomedical discovery. Existing privacy-preserving approaches, including multi-party computation and related cryptographic techniques, provide strong protection but often introduce substantial computational overhead, reducing the efficiency of large-scale machine learning and foundation-model training. In addition, many such methods make data usable for restricted computation while leaving them effectively invisible to clinicians and researchers, limiting their value in workflows that still require direct inspection, exploratory analysis, and human interpretation. We propose a real-world-data transformation framework for privacy-preserving sharing of structured clinical records. Instead of converting data into opaque representations, our approach constructs transformed numeric views that preserve medical semantics and major statistical properties while, under a clearly specified threat model, provably breaking direct linkage between those views and protected patient-level attributes. Through collaboration between computer scientists and the AI agent \textbf{SciencePal}, acting as a constrained tool inventor under human guidance, we design three transformation operators that are non-reversible within this threat model, together with an additional mixing strategy for high-risk scenarios, supported by theoretical analysis and empirical evaluation under reconstruction, record linkage, membership inference, and attribute inference attacks.
MOSAIC: Composable Safety Alignment with Modular Control Tokens
Mar 17, 2026Safety alignment in large language models (LLMs) is commonly implemented as a single static policy embedded in model parameters. However, real-world deployments often require context-dependent safety rules that vary across users, regions, and applications. Existing approaches struggle to provide such conditional control: parameter-level alignment entangles safety behaviors with general capabilities, while prompt-based methods rely on natural language instructions that provide weak enforcement. We propose MOSAIC, a modular framework that enables compositional safety alignment through learnable control tokens optimized over a frozen backbone model. Each token represents a safety constraint and can be flexibly activated and composed at inference time. To train compositional tokens efficiently, we introduce order-based task sampling and a distribution-level alignment objective that mitigates over-refusal. Experiments show that MOSAIC achieves strong defense performance with substantially lower over-refusal while preserving model utility.
To Search or Not to Search: Aligning the Decision Boundary of Deep Search Agents via Causal Intervention
Feb 03, 2026Deep search agents, which autonomously iterate through multi-turn web-based reasoning, represent a promising paradigm for complex information-seeking tasks. However, current agents suffer from critical inefficiency: they conduct excessive searches as they cannot accurately judge when to stop searching and start answering. This stems from outcome-centric training that prioritize final results over the search process itself. We identify the root cause as misaligned decision boundaries, the threshold determining when accumulated information suffices to answer. This causes over-search (redundant searching despite sufficient knowledge) and under-search (premature termination yielding incorrect answers). To address these errors, we propose a comprehensive framework comprising two key components. First, we introduce causal intervention-based diagnosis that identifies boundary errors by comparing factual and counterfactual trajectories at each decision point. Second, we develop Decision Boundary Alignment for Deep Search agents (DAS), which constructs preference datasets from causal feedback and aligns policies via preference optimization. Experiments on public datasets demonstrate that decision boundary errors are pervasive across state-of-the-art agents. Our DAS method effectively calibrates these boundaries, mitigating both over-search and under-search to achieve substantial gains in accuracy and efficiency. Our code and data are publicly available at: https://github.com/Applied-Machine-Learning-Lab/WWW2026_DAS.
Exploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Renormalization Group Guided Tensor Network Structure Search
Dec 31, 2025Tensor network structure search (TN-SS) aims to automatically discover optimal network topologies and rank configurations for efficient tensor decomposition in high-dimensional data representation. Despite recent advances, existing TN-SS methods face significant limitations in computational tractability, structure adaptivity, and optimization robustness across diverse tensor characteristics. They struggle with three key challenges: single-scale optimization missing multi-scale structures, discrete search spaces hindering smooth structure evolution, and separated structure-parameter optimization causing computational inefficiency. We propose RGTN (Renormalization Group guided Tensor Network search), a physics-inspired framework transforming TN-SS via multi-scale renormalization group flows. Unlike fixed-scale discrete search methods, RGTN uses dynamic scale-transformation for continuous structure evolution across resolutions. Its core innovation includes learnable edge gates for optimization-stage topology modification and intelligent proposals based on physical quantities like node tension measuring local stress and edge information flow quantifying connectivity importance. Starting from low-complexity coarse scales and refining to finer ones, RGTN finds compact structures while escaping local minima via scale-induced perturbations. Extensive experiments on light field data, high-order synthetic tensors, and video completion tasks show RGTN achieves state-of-the-art compression ratios and runs 4-600$\times$ faster than existing methods, validating the effectiveness of our physics-inspired approach.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025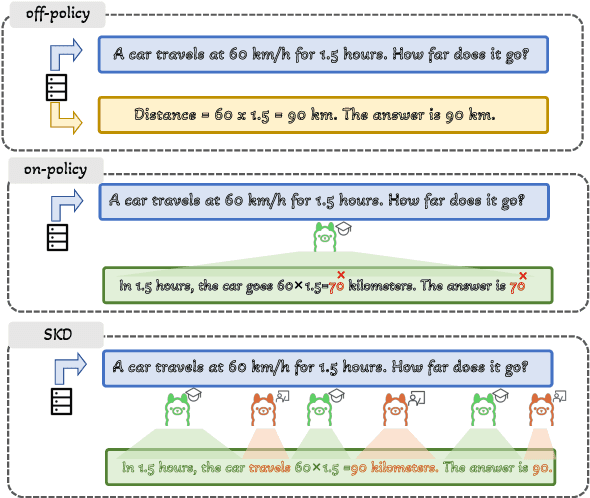
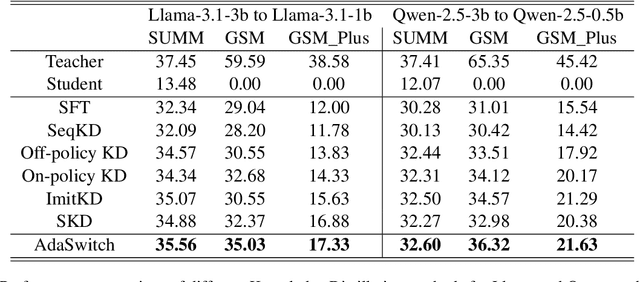
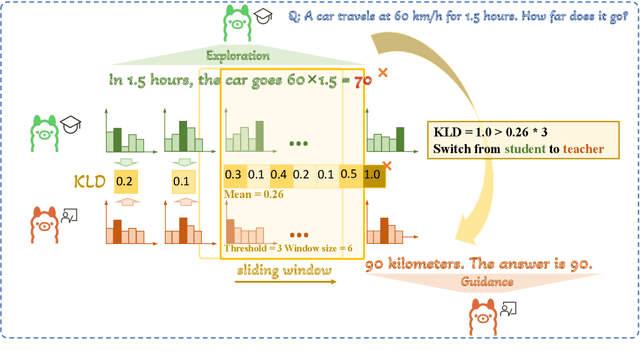
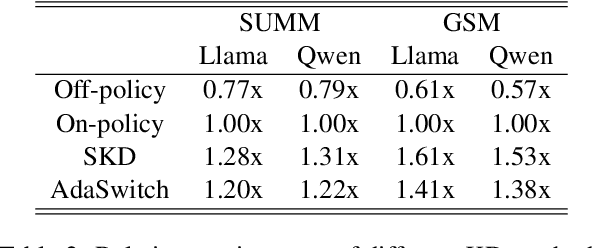
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
Empowering Denoising Sequential Recommendation with Large Language Model Embeddings
Oct 05, 2025Sequential recommendation aims to capture user preferences by modeling sequential patterns in user-item interactions. However, these models are often influenced by noise such as accidental interactions, leading to suboptimal performance. Therefore, to reduce the effect of noise, some works propose explicitly identifying and removing noisy items. However, we find that simply relying on collaborative information may result in an over-denoising problem, especially for cold items. To overcome these limitations, we propose a novel framework: Interest Alignment for Denoising Sequential Recommendation (IADSR) which integrates both collaborative and semantic information. Specifically, IADSR is comprised of two stages: in the first stage, we obtain the collaborative and semantic embeddings of each item from a traditional sequential recommendation model and an LLM, respectively. In the second stage, we align the collaborative and semantic embeddings and then identify noise in the interaction sequence based on long-term and short-term interests captured in the collaborative and semantic modalities. Our extensive experiments on four public datasets validate the effectiveness of the proposed framework and its compatibility with different sequential recommendation systems.
Exploring Superior Function Calls via Reinforcement Learning
Aug 07, 2025Function calling capabilities are crucial for deploying Large Language Models in real-world applications, yet current training approaches fail to develop robust reasoning strategies. Supervised fine-tuning produces models that rely on superficial pattern matching, while standard reinforcement learning methods struggle with the complex action space of structured function calls. We present a novel reinforcement learning framework designed to enhance group relative policy optimization through strategic entropy based exploration specifically tailored for function calling tasks. Our approach addresses three critical challenges in function calling: insufficient exploration during policy learning, lack of structured reasoning in chain-of-thought generation, and inadequate verification of parameter extraction. Our two-stage data preparation pipeline ensures high-quality training samples through iterative LLM evaluation and abstract syntax tree validation. Extensive experiments on the Berkeley Function Calling Leaderboard demonstrate that this framework achieves state-of-the-art performance among open-source models with 86.02\% overall accuracy, outperforming standard GRPO by up to 6\% on complex multi-function scenarios. Notably, our method shows particularly strong improvements on code-pretrained models, suggesting that structured language generation capabilities provide an advantageous starting point for reinforcement learning in function calling tasks. We will release all the code, models and dataset to benefit the community.
Measure Domain's Gap: A Similar Domain Selection Principle for Multi-Domain Recommendation
May 26, 2025Multi-Domain Recommendation (MDR) achieves the desirable recommendation performance by effectively utilizing the transfer information across different domains. Despite the great success, most existing MDR methods adopt a single structure to transfer complex domain-shared knowledge. However, the beneficial transferring information should vary across different domains. When there is knowledge conflict between domains or a domain is of poor quality, unselectively leveraging information from all domains will lead to a serious Negative Transfer Problem (NTP). Therefore, how to effectively model the complex transfer relationships between domains to avoid NTP is still a direction worth exploring. To address these issues, we propose a simple and dynamic Similar Domain Selection Principle (SDSP) for multi-domain recommendation in this paper. SDSP presents the initial exploration of selecting suitable domain knowledge for each domain to alleviate NTP. Specifically, we propose a novel prototype-based domain distance measure to effectively model the complexity relationship between domains. Thereafter, the proposed SDSP can dynamically find similar domains for each domain based on the supervised signals of the domain metrics and the unsupervised distance measure from the learned domain prototype. We emphasize that SDSP is a lightweight method that can be incorporated with existing MDR methods for better performance while not introducing excessive time overheads. To the best of our knowledge, it is the first solution that can explicitly measure domain-level gaps and dynamically select appropriate domains in the MDR field. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.