 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking
Jan 11, 2026Precise localization of GUI elements is crucial for the development of GUI agents. Traditional methods rely on bounding box or center-point regression, neglecting spatial interaction uncertainty and visual-semantic hierarchies. Recent methods incorporate attention mechanisms but still face two key issues: (1) ignoring processing background regions causes attention drift from the desired area, and (2) uniform modeling the target UI element fails to distinguish between its center and edges, leading to click imprecision. Inspired by how humans visually process and interact with GUI elements, we propose the Valley-to-Peak (V2P) method to address these issues. To mitigate background distractions, V2P introduces a suppression attention mechanism that minimizes the model's focus on irrelevant regions to highlight the intended region. For the issue of center-edge distinction, V2P applies a Fitts' Law-inspired approach by modeling GUI interactions as 2D Gaussian heatmaps where the weight gradually decreases from the center towards the edges. The weight distribution follows a Gaussian function, with the variance determined by the target's size. Consequently, V2P effectively isolates the target area and teaches the model to concentrate on the most essential point of the UI element. The model trained by V2P achieves the performance with 92.4\% and 52.5\% on two benchmarks ScreenSpot-v2 and ScreenSpot-Pro (see Fig.~\ref{fig:main_results_charts}). Ablations further confirm each component's contribution, underscoring V2P's generalizability in precise GUI grounding tasks and its potential for real-world deployment in future GUI agents.
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Exploring Superior Function Calls via Reinforcement Learning
Aug 07, 2025Function calling capabilities are crucial for deploying Large Language Models in real-world applications, yet current training approaches fail to develop robust reasoning strategies. Supervised fine-tuning produces models that rely on superficial pattern matching, while standard reinforcement learning methods struggle with the complex action space of structured function calls. We present a novel reinforcement learning framework designed to enhance group relative policy optimization through strategic entropy based exploration specifically tailored for function calling tasks. Our approach addresses three critical challenges in function calling: insufficient exploration during policy learning, lack of structured reasoning in chain-of-thought generation, and inadequate verification of parameter extraction. Our two-stage data preparation pipeline ensures high-quality training samples through iterative LLM evaluation and abstract syntax tree validation. Extensive experiments on the Berkeley Function Calling Leaderboard demonstrate that this framework achieves state-of-the-art performance among open-source models with 86.02\% overall accuracy, outperforming standard GRPO by up to 6\% on complex multi-function scenarios. Notably, our method shows particularly strong improvements on code-pretrained models, suggesting that structured language generation capabilities provide an advantageous starting point for reinforcement learning in function calling tasks. We will release all the code, models and dataset to benefit the community.
FunReason: Enhancing Large Language Models' Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement
May 26, 2025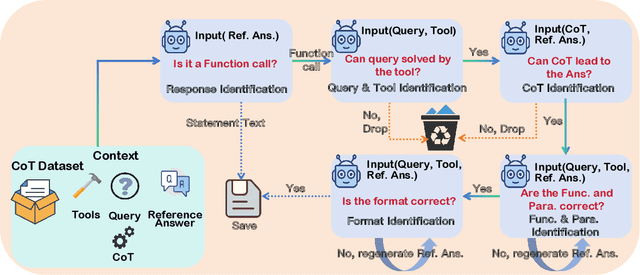
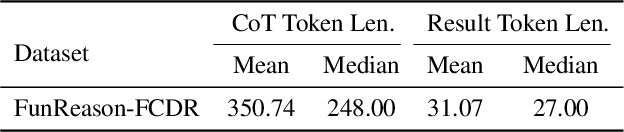
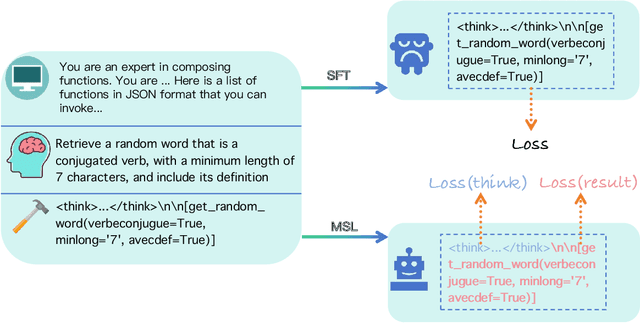

The integration of large language models (LLMs) with function calling has emerged as a crucial capability for enhancing their practical utility in real-world applications. However, effectively combining reasoning processes with accurate function execution remains a significant challenge. Traditional training approaches often struggle to balance the detailed reasoning steps with the precision of function calls, leading to suboptimal performance. To address these limitations, we introduce FunReason, a novel framework that enhances LLMs' function calling capabilities through an automated data refinement strategy and a Self-Refinement Multiscale Loss (SRML) approach. FunReason leverages LLMs' natural reasoning abilities to generate high-quality training examples, focusing on query parseability, reasoning coherence, and function call precision. The SRML approach dynamically balances the contribution of reasoning processes and function call accuracy during training, addressing the inherent trade-off between these two critical aspects. FunReason achieves performance comparable to GPT-4o while effectively mitigating catastrophic forgetting during fine-tuning. FunReason provides a comprehensive solution for enhancing LLMs' function calling capabilities by introducing a balanced training methodology and a data refinement pipeline. For code and dataset, please refer to our repository at GitHub https://github.com/BingguangHao/FunReason
E-Bench: Towards Evaluating the Ease-of-Use of Large Language Models
Jun 16, 2024Most large language models (LLMs) are sensitive to prompts, and another synonymous expression or a typo may lead to unexpected results for the model. Composing an optimal prompt for a specific demand lacks theoretical support and relies entirely on human experimentation, which poses a considerable obstacle to popularizing generative artificial intelligence. However, there is no systematic analysis of the stability of LLMs in resisting prompt perturbations in real-world scenarios. In this work, we propose to evaluate the ease-of-use of LLMs and construct E-Bench, simulating the actual situation of human use from synonymous perturbation (including paraphrasing, simplification, and colloquialism) and typographical perturbation (such as typing). On this basis, we also discuss the combination of these two types of perturbation and analyze the main reasons for performance degradation. Experimental results indicate that with the increase of model size, although the ease-of-use are significantly improved, there is still a long way to go to build a sufficiently user-friendly model.
From Global to Local: Multi-scale Out-of-distribution Detection
Aug 20, 2023



Out-of-distribution (OOD) detection aims to detect "unknown" data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (ALPA), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision (CSD) function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks -- on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at https://github.com/JimZAI/MODE-OOD.