 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Interpretable Multi-Agent LLM Routing via Ant Colony Optimization
Mar 13, 2026Large Language Model (LLM)-driven Multi-Agent Systems (MAS) have demonstrated strong capability in complex reasoning and tool use, and heterogeneous agent pools further broaden the quality--cost trade-off space. Despite these advances, real-world deployment is often constrained by high inference cost, latency, and limited transparency, which hinders scalable and efficient routing. Existing routing strategies typically rely on expensive LLM-based selectors or static policies, and offer limited controllability for semantic-aware routing under dynamic loads and mixed intents, often resulting in unstable performance and inefficient resource utilization. To address these limitations, we propose AMRO-S, an efficient and interpretable routing framework for Multi-Agent Systems (MAS). AMRO-S models MAS routing as a semantic-conditioned path selection problem, enhancing routing performance through three key mechanisms: First, it leverages a supervised fine-tuned (SFT) small language model for intent inference, providing a low-overhead semantic interface for each query; second, it decomposes routing memory into task-specific pheromone specialists, reducing cross-task interference and optimizing path selection under mixed workloads; finally, it employs a quality-gated asynchronous update mechanism to decouple inference from learning, optimizing routing without increasing latency. Extensive experiments on five public benchmarks and high-concurrency stress tests demonstrate that AMRO-S consistently improves the quality--cost trade-off over strong routing baselines, while providing traceable routing evidence through structured pheromone patterns.
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Oct 02, 2025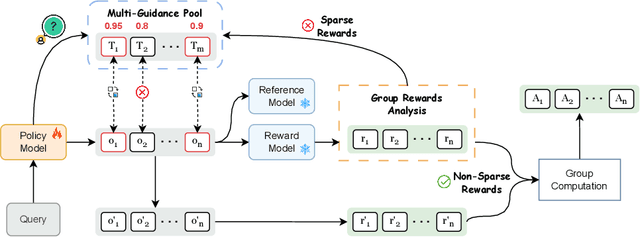
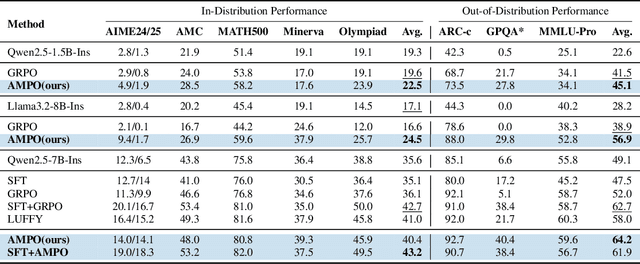

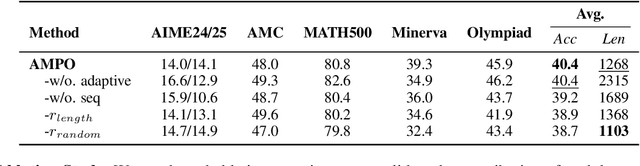
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This "guidance-on-demand" approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
Shortcut Learning in Generalist Robot Policies: The Role of Dataset Diversity and Fragmentation
Aug 08, 2025Generalist robot policies trained on large-scale datasets such as Open X-Embodiment (OXE) demonstrate strong performance across a wide range of tasks. However, they often struggle to generalize beyond the distribution of their training data. In this paper, we investigate the underlying cause of this limited generalization capability. We identify shortcut learning -- the reliance on task-irrelevant features -- as a key impediment to generalization. Through comprehensive theoretical and empirical analysis, we uncover two primary contributors to shortcut learning: (1) limited diversity within individual sub-datasets, and (2) significant distributional disparities across sub-datasets, leading to dataset fragmentation. These issues arise from the inherent structure of large-scale datasets like OXE, which are typically composed of multiple sub-datasets collected independently across varied environments and embodiments. Our findings provide critical insights into dataset collection strategies that can reduce shortcut learning and enhance the generalization ability of generalist robot policies. Moreover, in scenarios where acquiring new large-scale data is impractical, we demonstrate that carefully selected robotic data augmentation strategies can effectively reduce shortcut learning in existing offline datasets, thereby improving generalization capabilities of generalist robot policies, e.g., $\pi_0$, in both simulation and real-world environments. More information at https://lucky-light-sun.github.io/proj/shortcut-learning-in-grps/.
Multi-Type Context-Aware Conversational Recommender Systems via Mixture-of-Experts
Apr 18, 2025Conversational recommender systems enable natural language conversations and thus lead to a more engaging and effective recommendation scenario. As the conversations for recommender systems usually contain limited contextual information, many existing conversational recommender systems incorporate external sources to enrich the contextual information. However, how to combine different types of contextual information is still a challenge. In this paper, we propose a multi-type context-aware conversational recommender system, called MCCRS, effectively fusing multi-type contextual information via mixture-of-experts to improve conversational recommender systems. MCCRS incorporates both structured information and unstructured information, including the structured knowledge graph, unstructured conversation history, and unstructured item reviews. It consists of several experts, with each expert specialized in a particular domain (i.e., one specific contextual information). Multiple experts are then coordinated by a ChairBot to generate the final results. Our proposed MCCRS model takes advantage of different contextual information and the specialization of different experts followed by a ChairBot breaks the model bottleneck on a single contextual information. Experimental results demonstrate that our proposed MCCRS method achieves significantly higher performance compared to existing baselines.
Efficient Adaptation of Pre-trained Vision Transformer via Householder Transformation
Oct 30, 2024
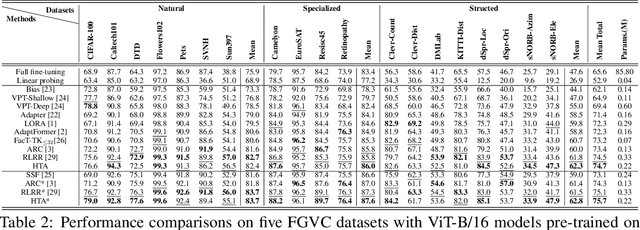

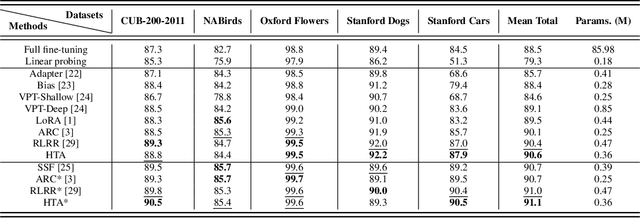
A common strategy for Parameter-Efficient Fine-Tuning (PEFT) of pre-trained Vision Transformers (ViTs) involves adapting the model to downstream tasks by learning a low-rank adaptation matrix. This matrix is decomposed into a product of down-projection and up-projection matrices, with the bottleneck dimensionality being crucial for reducing the number of learnable parameters, as exemplified by prevalent methods like LoRA and Adapter. However, these low-rank strategies typically employ a fixed bottleneck dimensionality, which limits their flexibility in handling layer-wise variations. To address this limitation, we propose a novel PEFT approach inspired by Singular Value Decomposition (SVD) for representing the adaptation matrix. SVD decomposes a matrix into the product of a left unitary matrix, a diagonal matrix of scaling values, and a right unitary matrix. We utilize Householder transformations to construct orthogonal matrices that efficiently mimic the unitary matrices, requiring only a vector. The diagonal values are learned in a layer-wise manner, allowing them to flexibly capture the unique properties of each layer. This approach enables the generation of adaptation matrices with varying ranks across different layers, providing greater flexibility in adapting pre-trained models. Experiments on standard downstream vision tasks demonstrate that our method achieves promising fine-tuning performance.
Goal-Reaching Policy Learning from Non-Expert Observations via Effective Subgoal Guidance
Sep 06, 2024


In this work, we address the challenging problem of long-horizon goal-reaching policy learning from non-expert, action-free observation data. Unlike fully labeled expert data, our data is more accessible and avoids the costly process of action labeling. Additionally, compared to online learning, which often involves aimless exploration, our data provides useful guidance for more efficient exploration. To achieve our goal, we propose a novel subgoal guidance learning strategy. The motivation behind this strategy is that long-horizon goals offer limited guidance for efficient exploration and accurate state transition. We develop a diffusion strategy-based high-level policy to generate reasonable subgoals as waypoints, preferring states that more easily lead to the final goal. Additionally, we learn state-goal value functions to encourage efficient subgoal reaching. These two components naturally integrate into the off-policy actor-critic framework, enabling efficient goal attainment through informative exploration. We evaluate our method on complex robotic navigation and manipulation tasks, demonstrating a significant performance advantage over existing methods. Our ablation study further shows that our method is robust to observation data with various corruptions.
Diffusion Models as Optimizers for Efficient Planning in Offline RL
Jul 23, 2024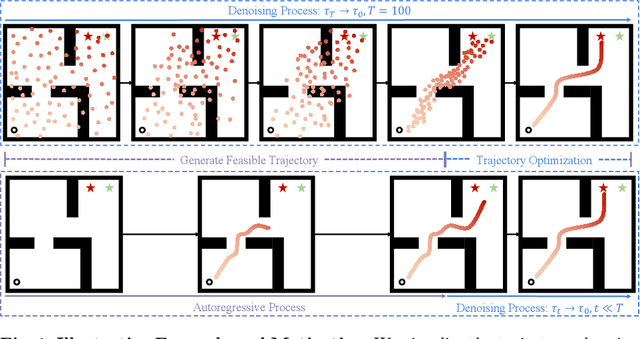
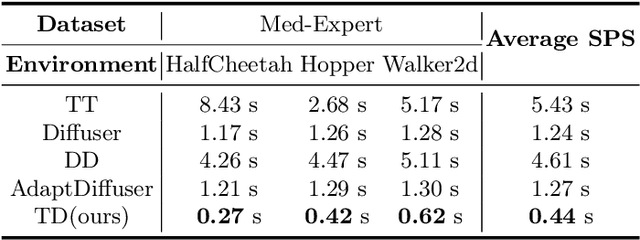
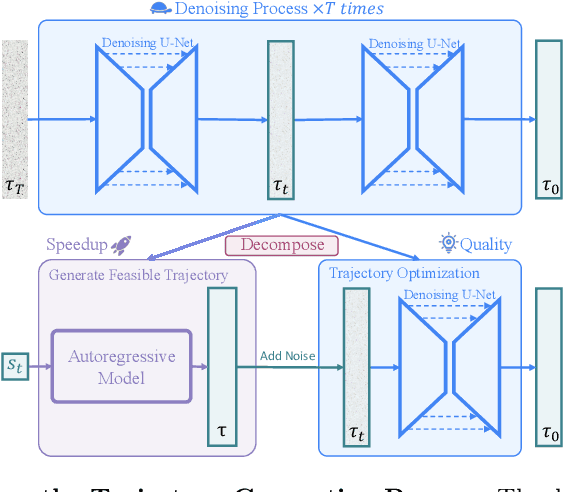
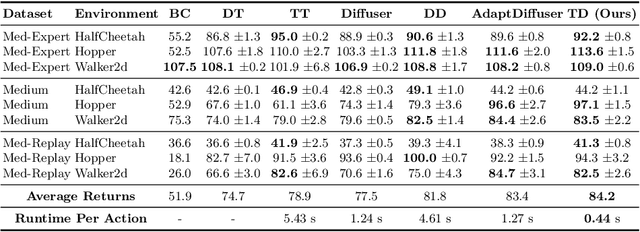
Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $\it 3$-$\it 10 \times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Jun 29, 2024



Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.
Text-Video Retrieval with Global-Local Semantic Consistent Learning
May 21, 2024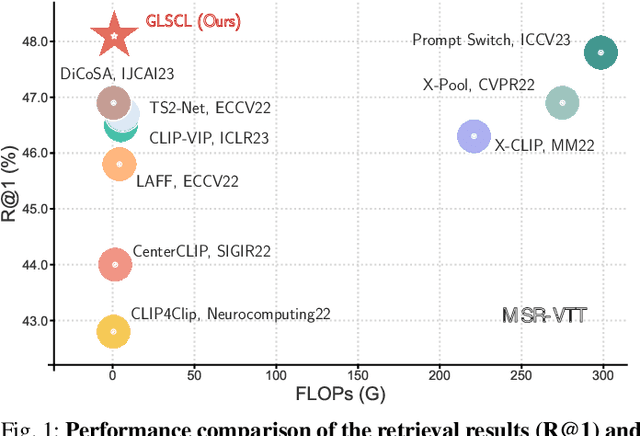
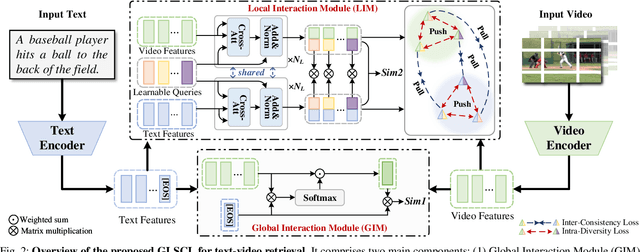
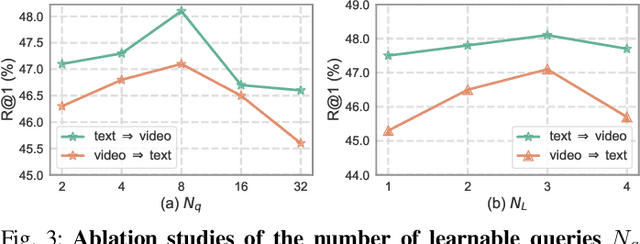
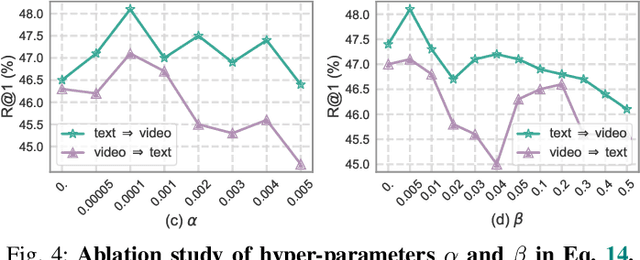
Adapting large-scale image-text pre-training models, e.g., CLIP, to the video domain represents the current state-of-the-art for text-video retrieval. The primary approaches involve transferring text-video pairs to a common embedding space and leveraging cross-modal interactions on specific entities for semantic alignment. Though effective, these paradigms entail prohibitive computational costs, leading to inefficient retrieval. To address this, we propose a simple yet effective method, Global-Local Semantic Consistent Learning (GLSCL), which capitalizes on latent shared semantics across modalities for text-video retrieval. Specifically, we introduce a parameter-free global interaction module to explore coarse-grained alignment. Then, we devise a shared local interaction module that employs several learnable queries to capture latent semantic concepts for learning fine-grained alignment. Furthermore, an Inter-Consistency Loss (ICL) is devised to accomplish the concept alignment between the visual query and corresponding textual query, and an Intra-Diversity Loss (IDL) is developed to repulse the distribution within visual (textual) queries to generate more discriminative concepts. Extensive experiments on five widely used benchmarks (i.e., MSR-VTT, MSVD, DiDeMo, LSMDC, and ActivityNet) substantiate the superior effectiveness and efficiency of the proposed method. Remarkably, our method achieves comparable performance with SOTA as well as being nearly 220 times faster in terms of computational cost. Code is available at: https://github.com/zchoi/GLSCL.
CoIN: A Benchmark of Continual Instruction tuNing for Multimodel Large Language Model
Mar 13, 2024



Instruction tuning represents a prevalent strategy employed by Multimodal Large Language Models (MLLMs) to align with human instructions and adapt to new tasks. Nevertheless, MLLMs encounter the challenge of adapting to users' evolving knowledge and demands. Therefore, how to retain existing skills while acquiring new knowledge needs to be investigated. In this paper, we present a comprehensive benchmark, namely Continual Instruction tuNing (CoIN), to assess existing MLLMs in the sequential instruction tuning paradigm. CoIN comprises 10 commonly used datasets spanning 8 task categories, ensuring a diverse range of instructions and tasks. Besides, the trained model is evaluated from two aspects: Instruction Following and General Knowledge, which assess the alignment with human intention and knowledge preserved for reasoning, respectively. Experiments on CoIN demonstrate that current powerful MLLMs still suffer catastrophic forgetting, and the failure in intention alignment assumes the main responsibility, instead of the knowledge forgetting. To this end, we introduce MoELoRA to MLLMs which is effective to retain the previous instruction alignment. Experimental results consistently illustrate the forgetting decreased from this method on CoIN.