 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJanus-LoRA: A Balanced Low-Rank Adaptation for Continual Learning
May 27, 2026Low-Rank Adaptation (LoRA) has emerged as a promising paradigm for Continual Learning. It independently updates its low-rank factors ($A$ and $B$), creating a composite update to the full weight matrix through their interaction. To prevent catastrophic forgetting, this update should remain orthogonal to the task-specific subspace that contains previously learned knowledge. However, we identify that this composite update systematically violates this orthogonality, reintroducing interference and undermining stability. Furthermore, naively enforcing this orthogonality compromises plasticity, disrupting the delicate stability-plasticity trade-off. To resolve these issues, we propose \textbf{Janus-LoRA}, a framework that restores this balance through two novel components. Specifically, we first introduce Gradient Rectification, a closed-form solution that mathematically decouples LoRA's factor updates, enforcing orthogonality against the historical knowledge subspace identified by an efficient Online Estimation. Next, to enhance plasticity, we introduce a Decoupled Margin Loss that promotes feature-level separation by pushing new feature representations away from old ones, thus creating distinct, low-interference regions for new learning. Comprehensive experiments on challenging benchmarks demonstrate that by harmonizing parameter-level orthogonality with feature-level separation, Janus-LoRA achieves a superior balance and establishes new state-of-the-art performance.
Structure-aware Prompt Adaptation from Seen to Unseen for Open-Vocabulary Compositional Zero-Shot Learning
Mar 04, 2026The goal of Open-Vocabulary Compositional Zero-Shot Learning (OV-CZSL) is to recognize attribute-object compositions in the open-vocabulary setting, where compositions of both seen and unseen attributes and objects are evaluated. Recently, prompt tuning methods have demonstrated strong generalization capabilities in the closed setting, where only compositions of seen attributes and objects are evaluated, i.e., Compositional Zero-Shot Learning (CZSL). However, directly applying these methods to OV-CZSL may not be sufficient to generalize to unseen attributes, objects and their compositions, as it is limited to seen attributes and objects. Normally, when faced with unseen concepts, humans adopt analogies with seen concepts that have the similar semantics thereby inferring their meaning (e.g., "wet" and "damp", "shirt" and "jacket"). In this paper, we experimentally show that the distribution of semantically related attributes or objects tends to form consistent local structures in the embedding space. Based on the above structures, we propose Structure-aware Prompt Adaptation (SPA) method, which enables models to generalize from seen to unseen attributes and objects. Specifically, in the training stage, we design a Structure-aware Consistency Loss (SCL) that encourages the local structure's consistency of seen attributes and objects in each iteration. In the inference stage, we devise a Structure-guided Adaptation Strategy (SAS) that adaptively aligns the structures of unseen attributes and objects with those of trained seen attributes and objects with similar semantics. Notably, SPA is a plug-and-play method that can be seamlessly integrated into existing CZSL prompt tuning methods. Extensive experiments on OV-CZSL benchmarks demonstrate that SPA achieves competitive closed-set performance while significantly improving open-vocabulary results.
TIMI: Training-Free Image-to-3D Multi-Instance Generation with Spatial Fidelity
Mar 02, 2026Precise spatial fidelity in Image-to-3D multi-instance generation is critical for downstream real-world applications. Recent work attempts to address this by fine-tuning pre-trained Image-to-3D (I23D) models on multi-instance datasets, which incurs substantial training overhead and struggles to guarantee spatial fidelity. In fact, we observe that pre-trained I23D models already possess meaningful spatial priors, which remain underutilized as evidenced by instance entanglement issues. Motivated by this, we propose TIMI, a novel Training-free framework for Image-to-3D Multi-Instance generation that achieves high spatial fidelity. Specifically, we first introduce an Instance-aware Separation Guidance (ISG) module, which facilitates instance disentanglement during the early denoising stage. Next, to stabilize the guidance introduced by ISG, we devise a Spatial-stabilized Geometry-adaptive Update (SGU) module that promotes the preservation of the geometric characteristics of instances while maintaining their relative relationships. Extensive experiments demonstrate that our method yields better performance in terms of both global layout and distinct local instances compared to existing multi-instance methods, without requiring additional training and with faster inference speed.
Sim-and-Human Co-training for Data-Efficient and Generalizable Robotic Manipulation
Jan 27, 2026Synthetic simulation data and real-world human data provide scalable alternatives to circumvent the prohibitive costs of robot data collection. However, these sources suffer from the sim-to-real visual gap and the human-to-robot embodiment gap, respectively, which limits the policy's generalization to real-world scenarios. In this work, we identify a natural yet underexplored complementarity between these sources: simulation offers the robot action that human data lacks, while human data provides the real-world observation that simulation struggles to render. Motivated by this insight, we present SimHum, a co-training framework to simultaneously extract kinematic prior from simulated robot actions and visual prior from real-world human observations. Based on the two complementary priors, we achieve data-efficient and generalizable robotic manipulation in real-world tasks. Empirically, SimHum outperforms the baseline by up to $\mathbf{40\%}$ under the same data collection budget, and achieves a $\mathbf{62.5\%}$ OOD success with only 80 real data, outperforming the real only baseline by $7.1\times$. Videos and additional information can be found at \href{https://kaipengfang.github.io/sim-and-human}{project website}.
From One-to-One to Many-to-Many: Dynamic Cross-Layer Injection for Deep Vision-Language Fusion
Jan 15, 2026Vision-Language Models (VLMs) create a severe visual feature bottleneck by using a crude, asymmetric connection that links only the output of the vision encoder to the input of the large language model (LLM). This static architecture fundamentally limits the ability of LLMs to achieve comprehensive alignment with hierarchical visual knowledge, compromising their capacity to accurately integrate local details with global semantics into coherent reasoning. To resolve this, we introduce Cross-Layer Injection (CLI), a novel and lightweight framework that forges a dynamic many-to-many bridge between the two modalities. CLI consists of two synergistic, parameter-efficient components: an Adaptive Multi-Projection (AMP) module that harmonizes features from diverse vision layers, and an Adaptive Gating Fusion (AGF) mechanism that empowers the LLM to selectively inject the most relevant visual information based on its real-time decoding context. We validate the effectiveness and versatility of CLI by integrating it into LLaVA-OneVision and LLaVA-1.5. Extensive experiments on 18 diverse benchmarks demonstrate significant performance improvements, establishing CLI as a scalable paradigm that unlocks deeper multimodal understanding by granting LLMs on-demand access to the full visual hierarchy.
RISER: Orchestrating Latent Reasoning Skills for Adaptive Activation Steering
Jan 14, 2026Recent work on domain-specific reasoning with large language models (LLMs) often relies on training-intensive approaches that require parameter updates. While activation steering has emerged as a parameter efficient alternative, existing methods apply static, manual interventions that fail to adapt to the dynamic nature of complex reasoning. To address this limitation, we propose RISER (Router-based Intervention for Steerable Enhancement of Reasoning), a plug-and-play intervention framework that adaptively steers LLM reasoning in activation space. RISER constructs a library of reusable reasoning vectors and employs a lightweight Router to dynamically compose them for each input. The Router is optimized via reinforcement learning under task-level rewards, activating latent cognitive primitives in an emergent and compositional manner. Across seven diverse benchmarks, RISER yields 3.4-6.5% average zero-shot accuracy improvements over the base model while surpassing CoT-style reasoning with 2-3x higher token efficiency and robust accuracy gains. Further analysis shows that RISER autonomously combines multiple vectors into interpretable, precise control strategies, pointing toward more controllable and efficient LLM reasoning.
OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
May 26, 2025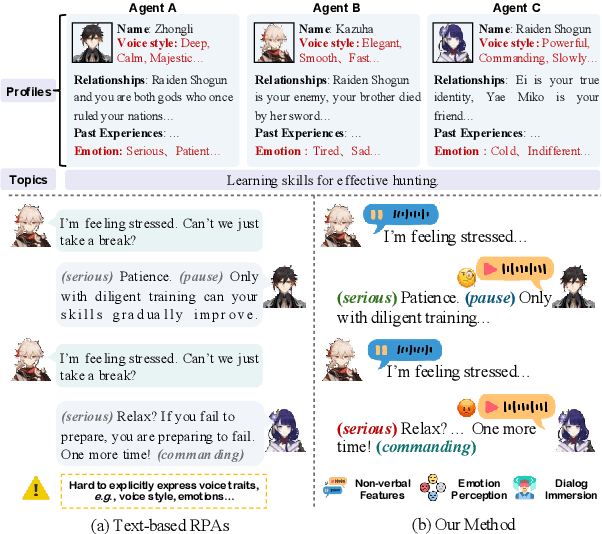



Role-Playing Agents (RPAs), benefiting from large language models, is an emerging interactive AI system that simulates roles or characters with diverse personalities. However, existing methods primarily focus on mimicking dialogues among roles in textual form, neglecting the role's voice traits (e.g., voice style and emotions) as playing a crucial effect in interaction, which tends to be more immersive experiences in realistic scenarios. Towards this goal, we propose OmniCharacter, a first seamless speech-language personality interaction model to achieve immersive RPAs with low latency. Specifically, OmniCharacter enables agents to consistently exhibit role-specific personality traits and vocal traits throughout the interaction, enabling a mixture of speech and language responses. To align the model with speech-language scenarios, we construct a dataset named OmniCharacter-10K, which involves more distinctive characters (20), richly contextualized multi-round dialogue (10K), and dynamic speech response (135K). Experimental results showcase that our method yields better responses in terms of both content and style compared to existing RPAs and mainstream speech-language models, with a response latency as low as 289ms. Code and dataset are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/OmniCharacter.
Towards Generalized and Training-Free Text-Guided Semantic Manipulation
Apr 24, 2025



Text-guided semantic manipulation refers to semantically editing an image generated from a source prompt to match a target prompt, enabling the desired semantic changes (e.g., addition, removal, and style transfer) while preserving irrelevant contents. With the powerful generative capabilities of the diffusion model, the task has shown the potential to generate high-fidelity visual content. Nevertheless, existing methods either typically require time-consuming fine-tuning (inefficient), fail to accomplish multiple semantic manipulations (poorly extensible), and/or lack support for different modality tasks (limited generalizability). Upon further investigation, we find that the geometric properties of noises in the diffusion model are strongly correlated with the semantic changes. Motivated by this, we propose a novel $\textit{GTF}$ for text-guided semantic manipulation, which has the following attractive capabilities: 1) $\textbf{Generalized}$: our $\textit{GTF}$ supports multiple semantic manipulations (e.g., addition, removal, and style transfer) and can be seamlessly integrated into all diffusion-based methods (i.e., Plug-and-play) across different modalities (i.e., modality-agnostic); and 2) $\textbf{Training-free}$: $\textit{GTF}$ produces high-fidelity results via simply controlling the geometric relationship between noises without tuning or optimization. Our extensive experiments demonstrate the efficacy of our approach, highlighting its potential to advance the state-of-the-art in semantics manipulation.
Skip Tuning: Pre-trained Vision-Language Models are Effective and Efficient Adapters Themselves
Dec 16, 2024



Prompt tuning (PT) has long been recognized as an effective and efficient paradigm for transferring large pre-trained vision-language models (VLMs) to downstream tasks by learning a tiny set of context vectors. Nevertheless, in this work, we reveal that freezing the parameters of VLMs during learning the context vectors neither facilitates the transferability of pre-trained knowledge nor improves the memory and time efficiency significantly. Upon further investigation, we find that reducing both the length and width of the feature-gradient propagation flows of the full fine-tuning (FT) baseline is key to achieving effective and efficient knowledge transfer. Motivated by this, we propose Skip Tuning, a novel paradigm for adapting VLMs to downstream tasks. Unlike existing PT or adapter-based methods, Skip Tuning applies Layer-wise Skipping (LSkip) and Class-wise Skipping (CSkip) upon the FT baseline without introducing extra context vectors or adapter modules. Extensive experiments across a wide spectrum of benchmarks demonstrate the superior effectiveness and efficiency of our Skip Tuning over both PT and adapter-based methods. Code: https://github.com/Koorye/SkipTuning.
GT23D-Bench: A Comprehensive General Text-to-3D Generation Benchmark
Dec 13, 2024Recent advances in General Text-to-3D (GT23D) have been significant. However, the lack of a benchmark has hindered systematic evaluation and progress due to issues in datasets and metrics: 1) The largest 3D dataset Objaverse suffers from omitted annotations, disorganization, and low-quality. 2) Existing metrics only evaluate textual-image alignment without considering the 3D-level quality. To this end, we are the first to present a comprehensive benchmark for GT23D called GT23D-Bench consisting of: 1) a 400k high-fidelity and well-organized 3D dataset that curated issues in Objaverse through a systematical annotation-organize-filter pipeline; and 2) comprehensive 3D-aware evaluation metrics which encompass 10 clearly defined metrics thoroughly accounting for multi-dimension of GT23D. Notably, GT23D-Bench features three properties: 1) Multimodal Annotations. Our dataset annotates each 3D object with 64-view depth maps, normal maps, rendered images, and coarse-to-fine captions. 2) Holistic Evaluation Dimensions. Our metrics are dissected into a) Textual-3D Alignment measures textual alignment with multi-granularity visual 3D representations; and b) 3D Visual Quality which considers texture fidelity, multi-view consistency, and geometry correctness. 3) Valuable Insights. We delve into the performance of current GT23D baselines across different evaluation dimensions and provide insightful analysis. Extensive experiments demonstrate that our annotations and metrics are aligned with human preferences.