 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-Text: Fine-grained Font-Controllable Text Editing for Poster Design
Nov 17, 2025Artistic design such as poster design often demands rapid yet precise modification of textual content while preserving visual harmony and typographic intent, especially across diverse font styles. Although modern image editing models have grown increasingly powerful, they still fall short in fine-grained, font-aware text manipulation, limiting their utility in professional design workflows such as poster editing. To address this issue, we present SkyReels-Text, a novel font-controllable framework for precise poster text editing. Our method enables simultaneous editing of multiple text regions, each rendered in distinct typographic styles, while preserving the visual appearance of non-edited regions. Notably, our model requires neither font labels nor fine-tuning during inference: users can simply provide cropped glyph patches corresponding to their desired typography, even if the font is not included in any standard library. Extensive experiments on multiple datasets, including handwrittent text benchmarks, SkyReels-Text achieves state-of-the-art performance in both text fidelity and visual realism, offering unprecedented control over font families, and stylistic nuances. This work bridges the gap between general-purpose image editing and professional-grade typographic design.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
SeMv-3D: Towards Semantic and Mutil-view Consistency simultaneously for General Text-to-3D Generation with Triplane Priors
Oct 10, 2024Recent advancements in generic 3D content generation from text prompts have been remarkable by fine-tuning text-to-image diffusion (T2I) models or employing these T2I models as priors to learn a general text-to-3D model. While fine-tuning-based methods ensure great alignment between text and generated views, i.e., semantic consistency, their ability to achieve multi-view consistency is hampered by the absence of 3D constraints, even in limited view. In contrast, prior-based methods focus on regressing 3D shapes with any view that maintains uniformity and coherence across views, i.e., multi-view consistency, but such approaches inevitably compromise visual-textual alignment, leading to a loss of semantic details in the generated objects. To achieve semantic and multi-view consistency simultaneously, we propose SeMv-3D, a novel framework for general text-to-3d generation. Specifically, we propose a Triplane Prior Learner (TPL) that learns triplane priors with 3D spatial features to maintain consistency among different views at the 3D level, e.g., geometry and texture. Moreover, we design a Semantic-aligned View Synthesizer (SVS) that preserves the alignment between 3D spatial features and textual semantics in latent space. In SVS, we devise a simple yet effective batch sampling and rendering strategy that can generate arbitrary views in a single feed-forward inference. Extensive experiments present our SeMv-3D's superiority over state-of-the-art performances with semantic and multi-view consistency in any view. Our code and more visual results are available at https://anonymous.4open.science/r/SeMv-3D-6425.
EchoReel: Enhancing Action Generation of Existing Video Diffusion Models
Mar 18, 2024Recent large-scale video datasets have facilitated the generation of diverse open-domain videos of Video Diffusion Models (VDMs). Nonetheless, the efficacy of VDMs in assimilating complex knowledge from these datasets remains constrained by their inherent scale, leading to suboptimal comprehension and synthesis of numerous actions. In this paper, we introduce EchoReel, a novel approach to augment the capability of VDMs in generating intricate actions by emulating motions from pre-existing videos, which are readily accessible from databases or online repositories. EchoReel seamlessly integrates with existing VDMs, enhancing their ability to produce realistic motions without compromising their fundamental capabilities. Specifically, the Action Prism (AP), is introduced to distill motion information from reference videos, which requires training on only a small dataset. Leveraging the knowledge from pre-trained VDMs, EchoReel incorporates new action features into VDMs through the additional layers, eliminating the need for any further fine-tuning of untrained actions. Extensive experiments demonstrate that EchoReel is not merely replicating the whole content from references, and it significantly improves the generation of realistic actions, even in situations where existing VDMs might directly fail.
CoIN: A Benchmark of Continual Instruction tuNing for Multimodel Large Language Model
Mar 13, 2024



Instruction tuning represents a prevalent strategy employed by Multimodal Large Language Models (MLLMs) to align with human instructions and adapt to new tasks. Nevertheless, MLLMs encounter the challenge of adapting to users' evolving knowledge and demands. Therefore, how to retain existing skills while acquiring new knowledge needs to be investigated. In this paper, we present a comprehensive benchmark, namely Continual Instruction tuNing (CoIN), to assess existing MLLMs in the sequential instruction tuning paradigm. CoIN comprises 10 commonly used datasets spanning 8 task categories, ensuring a diverse range of instructions and tasks. Besides, the trained model is evaluated from two aspects: Instruction Following and General Knowledge, which assess the alignment with human intention and knowledge preserved for reasoning, respectively. Experiments on CoIN demonstrate that current powerful MLLMs still suffer catastrophic forgetting, and the failure in intention alignment assumes the main responsibility, instead of the knowledge forgetting. To this end, we introduce MoELoRA to MLLMs which is effective to retain the previous instruction alignment. Experimental results consistently illustrate the forgetting decreased from this method on CoIN.
Training-Free Semantic Video Composition via Pre-trained Diffusion Model
Jan 17, 2024



The video composition task aims to integrate specified foregrounds and backgrounds from different videos into a harmonious composite. Current approaches, predominantly trained on videos with adjusted foreground color and lighting, struggle to address deep semantic disparities beyond superficial adjustments, such as domain gaps. Therefore, we propose a training-free pipeline employing a pre-trained diffusion model imbued with semantic prior knowledge, which can process composite videos with broader semantic disparities. Specifically, we process the video frames in a cascading manner and handle each frame in two processes with the diffusion model. In the inversion process, we propose Balanced Partial Inversion to obtain generation initial points that balance reversibility and modifiability. Then, in the generation process, we further propose Inter-Frame Augmented attention to augment foreground continuity across frames. Experimental results reveal that our pipeline successfully ensures the visual harmony and inter-frame coherence of the outputs, demonstrating efficacy in managing broader semantic disparities.
CUCL: Codebook for Unsupervised Continual Learning
Nov 25, 2023The focus of this study is on Unsupervised Continual Learning (UCL), as it presents an alternative to Supervised Continual Learning which needs high-quality manual labeled data. The experiments under the UCL paradigm indicate a phenomenon where the results on the first few tasks are suboptimal. This phenomenon can render the model inappropriate for practical applications. To address this issue, after analyzing the phenomenon and identifying the lack of diversity as a vital factor, we propose a method named Codebook for Unsupervised Continual Learning (CUCL) which promotes the model to learn discriminative features to complete the class boundary. Specifically, we first introduce a Product Quantization to inject diversity into the representation and apply a cross quantized contrastive loss between the original representation and the quantized one to capture discriminative information. Then, based on the quantizer, we propose an effective Codebook Rehearsal to address catastrophic forgetting. This study involves conducting extensive experiments on CIFAR100, TinyImageNet, and MiniImageNet benchmark datasets. Our method significantly boosts the performances of supervised and unsupervised methods. For instance, on TinyImageNet, our method led to a relative improvement of 12.76% and 7% when compared with Simsiam and BYOL, respectively.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023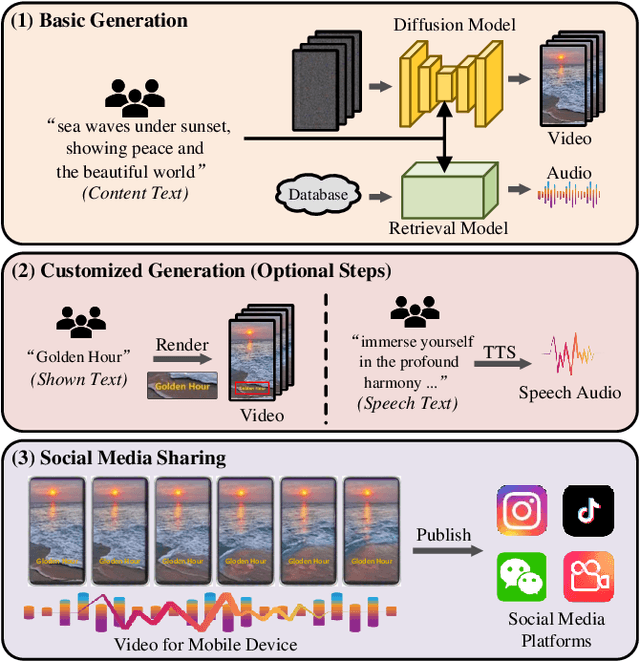

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
Jun 12, 2023In this paper, we present MovieFactory, a powerful framework to generate cinematic-picture (3072$\times$1280), film-style (multi-scene), and multi-modality (sounding) movies on the demand of natural languages. As the first fully automated movie generation model to the best of our knowledge, our approach empowers users to create captivating movies with smooth transitions using simple text inputs, surpassing existing methods that produce soundless videos limited to a single scene of modest quality. To facilitate this distinctive functionality, we leverage ChatGPT to expand user-provided text into detailed sequential scripts for movie generation. Then we bring scripts to life visually and acoustically through vision generation and audio retrieval. To generate videos, we extend the capabilities of a pretrained text-to-image diffusion model through a two-stage process. Firstly, we employ spatial finetuning to bridge the gap between the pretrained image model and the new video dataset. Subsequently, we introduce temporal learning to capture object motion. In terms of audio, we leverage sophisticated retrieval models to select and align audio elements that correspond to the plot and visual content of the movie. Extensive experiments demonstrate that our MovieFactory produces movies with realistic visuals, diverse scenes, and seamlessly fitting audio, offering users a novel and immersive experience. Generated samples can be found in YouTube or Bilibili (1080P).
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation
May 18, 2023



We present VideoFactory, an innovative framework for generating high-quality open-domain videos. VideoFactory excels in producing high-definition (1376x768), widescreen (16:9) videos without watermarks, creating an engaging user experience. Generating videos guided by text instructions poses significant challenges, such as modeling the complex relationship between space and time, and the lack of large-scale text-video paired data. Previous approaches extend pretrained text-to-image generation models by adding temporal 1D convolution/attention modules for video generation. However, these approaches overlook the importance of jointly modeling space and time, inevitably leading to temporal distortions and misalignment between texts and videos. In this paper, we propose a novel approach that strengthens the interaction between spatial and temporal perceptions. In particular, we utilize a swapped cross-attention mechanism in 3D windows that alternates the "query" role between spatial and temporal blocks, enabling mutual reinforcement for each other. To fully unlock model capabilities for high-quality video generation, we curate a large-scale video dataset called HD-VG-130M. This dataset comprises 130 million text-video pairs from the open-domain, ensuring high-definition, widescreen and watermark-free characters. Objective metrics and user studies demonstrate the superiority of our approach in terms of per-frame quality, temporal correlation, and text-video alignment, with clear margins.