 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Few-shot Transferability of Pre-trained Models with Improved Evaluation Protocols
Feb 28, 2026Few-shot transfer has been revolutionized by stronger pre-trained models and improved adaptation algorithms.However, there lacks a unified, rigorous evaluation protocol that is both challenging and realistic for real-world usage. In this work, we establish FEWTRANS, a comprehensive benchmark containing 10 diverse datasets, and propose the Hyperparameter Ensemble (HPE) protocol to overcome the "validation set illusion" in data-scarce regimes. Our empirical findings demonstrate that the choice of pre-trained model is the dominant factor for performance, while many sophisticated transfer methods offer negligible practical advantages over a simple full-parameter fine-tuning baseline. To explain this surprising effectiveness, we provide an in-depth mechanistic analysis showing that full fine-tuning succeeds via distributed micro-adjustments and more flexible reshaping of high-level semantic presentations without suffering from overfitting. Additionally, we quantify the performance collapse of multimodal models in specialized domains as a result of linguistic rarity using adjusted Zipf frequency scores. By releasing FEWTRANS, we aim to provide a rigorous "ruler" to streamline reproducible advances in few-shot transfer learning research. We make the FEWTRANS benchmark publicly available at https://github.com/Frankluox/FewTrans.
A 24-GHz CMOS Transformer-Based Three-Tline Series Doherty Power Amplifier Achieving 39% PAE
Nov 15, 2025



This paper presents a transformer-based three- transmission-line (Tline) series Doherty power amplifier (PA) implemented in 65-nm CMOS, targeting broadband K/Ka-band applications. By integrating an impedance-scaling network into the output matching structure, the design enables effective load modulation and reduced impedance transformation ratio (ITR) at power back-off when employing stacked cascode transistors. The PA demonstrates a -3-dB small-signal gain bandwidth from 22 to 32.5 GHz, a saturated output power (Psat) of 21.6 dBm, and a peak power-added efficiency (PAE) of 39%. At 6dB back-off, the PAE remains above 24%, validating its suitability for high- efficiency mm-wave phased-array transmitters in next-generation wireless systems.
Shortcut Learning in Generalist Robot Policies: The Role of Dataset Diversity and Fragmentation
Aug 08, 2025Generalist robot policies trained on large-scale datasets such as Open X-Embodiment (OXE) demonstrate strong performance across a wide range of tasks. However, they often struggle to generalize beyond the distribution of their training data. In this paper, we investigate the underlying cause of this limited generalization capability. We identify shortcut learning -- the reliance on task-irrelevant features -- as a key impediment to generalization. Through comprehensive theoretical and empirical analysis, we uncover two primary contributors to shortcut learning: (1) limited diversity within individual sub-datasets, and (2) significant distributional disparities across sub-datasets, leading to dataset fragmentation. These issues arise from the inherent structure of large-scale datasets like OXE, which are typically composed of multiple sub-datasets collected independently across varied environments and embodiments. Our findings provide critical insights into dataset collection strategies that can reduce shortcut learning and enhance the generalization ability of generalist robot policies. Moreover, in scenarios where acquiring new large-scale data is impractical, we demonstrate that carefully selected robotic data augmentation strategies can effectively reduce shortcut learning in existing offline datasets, thereby improving generalization capabilities of generalist robot policies, e.g., $\pi_0$, in both simulation and real-world environments. More information at https://lucky-light-sun.github.io/proj/shortcut-learning-in-grps/.
Unlocking Smarter Device Control: Foresighted Planning with a World Model-Driven Code Execution Approach
May 22, 2025The automatic control of mobile devices is essential for efficiently performing complex tasks that involve multiple sequential steps. However, these tasks pose significant challenges due to the limited environmental information available at each step, primarily through visual observations. As a result, current approaches, which typically rely on reactive policies, focus solely on immediate observations and often lead to suboptimal decision-making. To address this problem, we propose \textbf{Foresighted Planning with World Model-Driven Code Execution (FPWC)},a framework that prioritizes natural language understanding and structured reasoning to enhance the agent's global understanding of the environment by developing a task-oriented, refinable \emph{world model} at the outset of the task. Foresighted actions are subsequently generated through iterative planning within this world model, executed in the form of executable code. Extensive experiments conducted in simulated environments and on real mobile devices demonstrate that our method outperforms previous approaches, particularly achieving a 44.4\% relative improvement in task success rate compared to the state-of-the-art in the simulated environment. Code and demo are provided in the supplementary material.
InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning
May 20, 2025Leveraging pretrained Vision-Language Models (VLMs) to map language instruction and visual observations to raw low-level actions, Vision-Language-Action models (VLAs) hold great promise for achieving general-purpose robotic systems. Despite their advancements, existing VLAs tend to spuriously correlate task-irrelevant visual features with actions, limiting their generalization capacity beyond the training data. To tackle this challenge, we propose Intrinsic Spatial Reasoning (InSpire), a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs. Specifically, InSpire redirects the VLA's attention to task-relevant factors by prepending the question "In which direction is the [object] relative to the robot?" to the language instruction and aligning the answer "right/left/up/down/front/back/grasped" and predicted actions with the ground-truth. Notably, InSpire can be used as a plugin to enhance existing autoregressive VLAs, requiring no extra training data or interaction with other large models. Extensive experimental results in both simulation and real-world environments demonstrate the effectiveness and flexibility of our approach. Our code, pretrained models and demos are publicly available at: https://Koorye.github.io/proj/Inspire.
Policy Contrastive Decoding for Robotic Foundation Models
May 19, 2025Robotic foundation models, or generalist robot policies, hold immense potential to enable flexible, general-purpose and dexterous robotic systems. Despite their advancements, our empirical experiments reveal that existing robot policies are prone to learning spurious correlations from pre-training trajectories, adversely affecting their generalization capabilities beyond the training data. To tackle this, we propose a novel Policy Contrastive Decoding (PCD) approach, which redirects the robot policy's focus toward object-relevant visual clues by contrasting action probability distributions derived from original and object-masked visual inputs. As a training-free method, our PCD can be used as a plugin to improve different types of robot policies without needing to finetune or access model weights. We conduct extensive experiments on top of three open-source robot policies, including the autoregressive policy OpenVLA and the diffusion-based policies Octo and $\pi_0$. The obtained results in both simulation and real-world environments prove PCD's flexibility and effectiveness, e.g., PCD enhances the state-of-the-art policy $\pi_0$ by 8% in the simulation environment and by 108% in the real-world environment. Code and demos are publicly available at: https://Koorye.github.io/proj/PCD.
Semantic Data Augmentation Enhanced Invariant Risk Minimization for Medical Image Domain Generalization
Feb 08, 2025Deep learning has achieved remarkable success in medical image classification. However, its clinical application is often hindered by data heterogeneity caused by variations in scanner vendors, imaging protocols, and operators. Approaches such as invariant risk minimization (IRM) aim to address this challenge of out-of-distribution generalization. For instance, VIRM improves upon IRM by tackling the issue of insufficient feature support overlap, demonstrating promising potential. Nonetheless, these methods face limitations in medical imaging due to the scarcity of annotated data and the inefficiency of augmentation strategies. To address these issues, we propose a novel domain-oriented direction selector to replace the random augmentation strategy used in VIRM. Our method leverages inter-domain covariance as a guider for augmentation direction, guiding data augmentation towards the target domain. This approach effectively reduces domain discrepancies and enhances generalization performance. Experiments on a multi-center diabetic retinopathy dataset demonstrate that our method outperforms state-of-the-art approaches, particularly under limited data conditions and significant domain heterogeneity.
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
May 09, 2024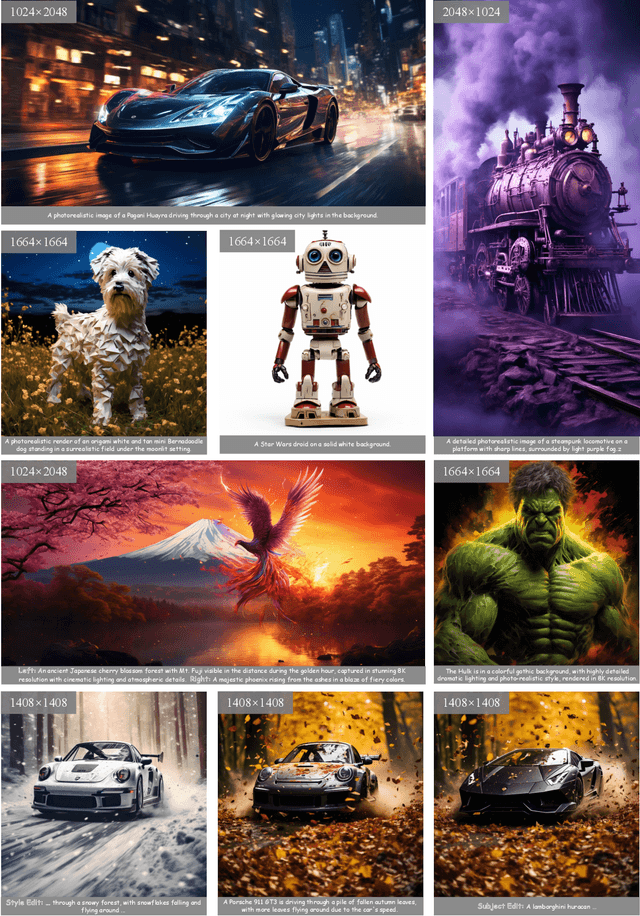
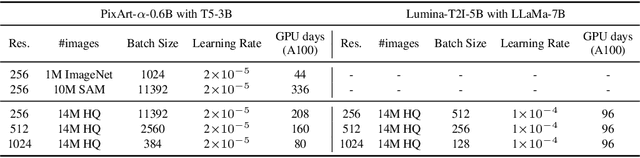
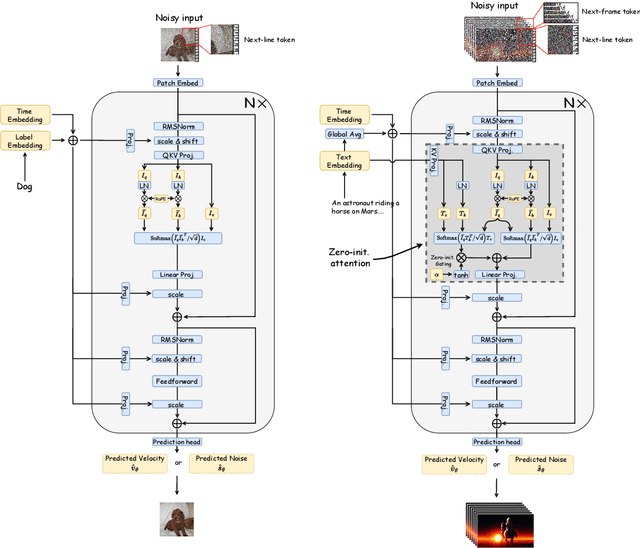
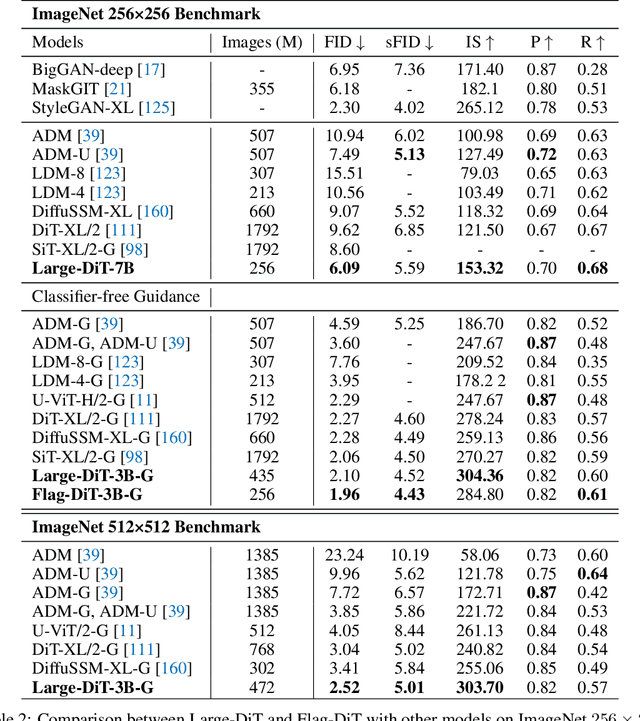
Sora unveils the potential of scaling Diffusion Transformer for generating photorealistic images and videos at arbitrary resolutions, aspect ratios, and durations, yet it still lacks sufficient implementation details. In this technical report, we introduce the Lumina-T2X family - a series of Flow-based Large Diffusion Transformers (Flag-DiT) equipped with zero-initialized attention, as a unified framework designed to transform noise into images, videos, multi-view 3D objects, and audio clips conditioned on text instructions. By tokenizing the latent spatial-temporal space and incorporating learnable placeholders such as [nextline] and [nextframe] tokens, Lumina-T2X seamlessly unifies the representations of different modalities across various spatial-temporal resolutions. This unified approach enables training within a single framework for different modalities and allows for flexible generation of multimodal data at any resolution, aspect ratio, and length during inference. Advanced techniques like RoPE, RMSNorm, and flow matching enhance the stability, flexibility, and scalability of Flag-DiT, enabling models of Lumina-T2X to scale up to 7 billion parameters and extend the context window to 128K tokens. This is particularly beneficial for creating ultra-high-definition images with our Lumina-T2I model and long 720p videos with our Lumina-T2V model. Remarkably, Lumina-T2I, powered by a 5-billion-parameter Flag-DiT, requires only 35% of the training computational costs of a 600-million-parameter naive DiT. Our further comprehensive analysis underscores Lumina-T2X's preliminary capability in resolution extrapolation, high-resolution editing, generating consistent 3D views, and synthesizing videos with seamless transitions. We expect that the open-sourcing of Lumina-T2X will further foster creativity, transparency, and diversity in the generative AI community.
CoIN: A Benchmark of Continual Instruction tuNing for Multimodel Large Language Model
Mar 13, 2024



Instruction tuning represents a prevalent strategy employed by Multimodal Large Language Models (MLLMs) to align with human instructions and adapt to new tasks. Nevertheless, MLLMs encounter the challenge of adapting to users' evolving knowledge and demands. Therefore, how to retain existing skills while acquiring new knowledge needs to be investigated. In this paper, we present a comprehensive benchmark, namely Continual Instruction tuNing (CoIN), to assess existing MLLMs in the sequential instruction tuning paradigm. CoIN comprises 10 commonly used datasets spanning 8 task categories, ensuring a diverse range of instructions and tasks. Besides, the trained model is evaluated from two aspects: Instruction Following and General Knowledge, which assess the alignment with human intention and knowledge preserved for reasoning, respectively. Experiments on CoIN demonstrate that current powerful MLLMs still suffer catastrophic forgetting, and the failure in intention alignment assumes the main responsibility, instead of the knowledge forgetting. To this end, we introduce MoELoRA to MLLMs which is effective to retain the previous instruction alignment. Experimental results consistently illustrate the forgetting decreased from this method on CoIN.
Symmetrical Bidirectional Knowledge Alignment for Zero-Shot Sketch-Based Image Retrieval
Dec 16, 2023This paper studies the problem of zero-shot sketch-based image retrieval (ZS-SBIR), which aims to use sketches from unseen categories as queries to match the images of the same category. Due to the large cross-modality discrepancy, ZS-SBIR is still a challenging task and mimics realistic zero-shot scenarios. The key is to leverage transferable knowledge from the pre-trained model to improve generalizability. Existing researchers often utilize the simple fine-tuning training strategy or knowledge distillation from a teacher model with fixed parameters, lacking efficient bidirectional knowledge alignment between student and teacher models simultaneously for better generalization. In this paper, we propose a novel Symmetrical Bidirectional Knowledge Alignment for zero-shot sketch-based image retrieval (SBKA). The symmetrical bidirectional knowledge alignment learning framework is designed to effectively learn mutual rich discriminative information between teacher and student models to achieve the goal of knowledge alignment. Instead of the former one-to-one cross-modality matching in the testing stage, a one-to-many cluster cross-modality matching method is proposed to leverage the inherent relationship of intra-class images to reduce the adverse effects of the existing modality gap. Experiments on several representative ZS-SBIR datasets (Sketchy Ext dataset, TU-Berlin Ext dataset and QuickDraw Ext dataset) prove the proposed algorithm can achieve superior performance compared with state-of-the-art methods.