 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Enhancement of Radiographic X-ray Images by Interpretable Mapping
Jan 21, 2025X-ray imaging is the most widely used medical imaging modality. However, in the common practice, inconsistency in the initial presentation of X-ray images is a common complaint by radiologists. Different patient positions, patient habitus and scanning protocols can lead to differences in image presentations, e.g., differences in brightness and contrast globally or regionally. To compensate for this, additional work will be executed by clinical experts to adjust the images to the desired presentation, which can be time-consuming. Existing deep-learning-based end-to-end solutions can automatically correct images with promising performances. Nevertheless, these methods are hard to be interpreted and difficult to be understood by clinical experts. In this manuscript, a novel interpretable mapping method by deep learning is proposed, which automatically enhances the image brightness and contrast globally and locally. Meanwhile, because the model is inspired by the workflow of the brightness and contrast manipulation, it can provide interpretable pixel maps for explaining the motivation of image enhancement. The experiment on the clinical datasets show the proposed method can provide consistent brightness and contrast correction on X-ray images with accuracy of 24.75 dB PSNR and 0.8431 SSIM.
Uncertainty Quantification for Clinical Outcome Predictions with (Large) Language Models
Nov 05, 2024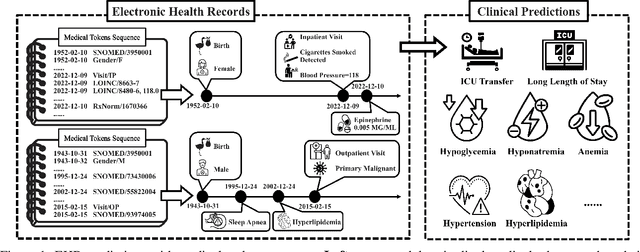



To facilitate healthcare delivery, language models (LMs) have significant potential for clinical prediction tasks using electronic health records (EHRs). However, in these high-stakes applications, unreliable decisions can result in high costs due to compromised patient safety and ethical concerns, thus increasing the need for good uncertainty modeling of automated clinical predictions. To address this, we consider the uncertainty quantification of LMs for EHR tasks in white- and black-box settings. We first quantify uncertainty in white-box models, where we can access model parameters and output logits. We show that an effective reduction of model uncertainty can be achieved by using the proposed multi-tasking and ensemble methods in EHRs. Continuing with this idea, we extend our approach to black-box settings, including popular proprietary LMs such as GPT-4. We validate our framework using longitudinal clinical data from more than 6,000 patients in ten clinical prediction tasks. Results show that ensembling methods and multi-task prediction prompts reduce uncertainty across different scenarios. These findings increase the transparency of the model in white-box and black-box settings, thus advancing reliable AI healthcare.
3DAxiesPrompts: Unleashing the 3D Spatial Task Capabilities of GPT-4V
Dec 15, 2023In this work, we present a new visual prompting method called 3DAxiesPrompts (3DAP) to unleash the capabilities of GPT-4V in performing 3D spatial tasks. Our investigation reveals that while GPT-4V exhibits proficiency in discerning the position and interrelations of 2D entities through current visual prompting techniques, its abilities in handling 3D spatial tasks have yet to be explored. In our approach, we create a 3D coordinate system tailored to 3D imagery, complete with annotated scale information. By presenting images infused with the 3DAP visual prompt as inputs, we empower GPT-4V to ascertain the spatial positioning information of the given 3D target image with a high degree of precision. Through experiments, We identified three tasks that could be stably completed using the 3DAP method, namely, 2D to 3D Point Reconstruction, 2D to 3D point matching, and 3D Object Detection. We perform experiments on our proposed dataset 3DAP-Data, the results from these experiments validate the efficacy of 3DAP-enhanced GPT-4V inputs, marking a significant stride in 3D spatial task execution.
Adversarial Focal Loss: Asking Your Discriminator for Hard Examples
Jul 15, 2022
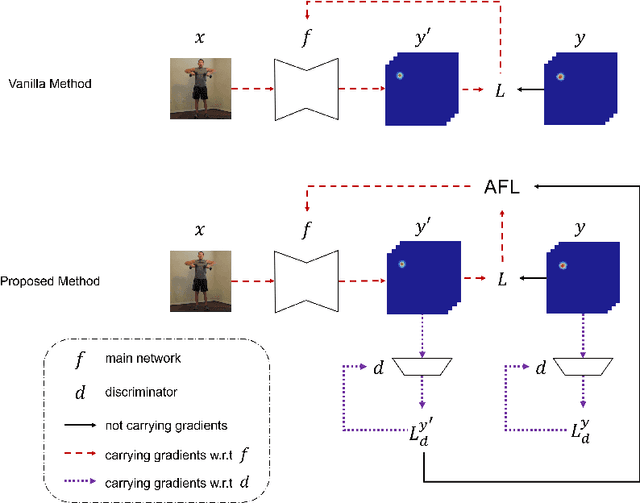
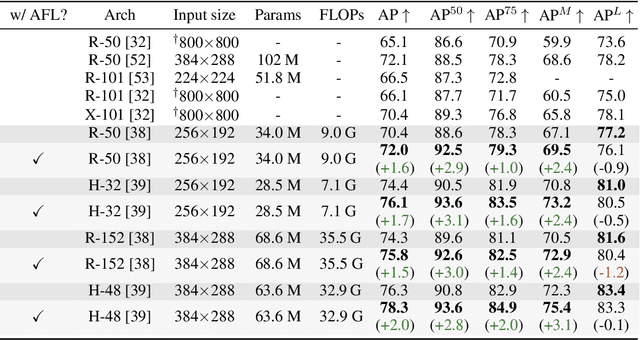
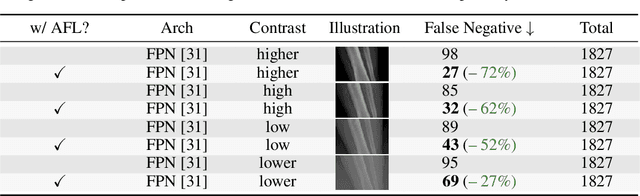
Focal Loss has reached incredible popularity as it uses a simple technique to identify and utilize hard examples to achieve better performance on classification. However, this method does not easily generalize outside of classification tasks, such as in keypoint detection. In this paper, we propose a novel adaptation of Focal Loss for keypoint detection tasks, called Adversarial Focal Loss (AFL). AFL not only is semantically analogous to Focal loss, but also works as a plug-and-chug upgrade for arbitrary loss functions. While Focal Loss requires output from a classifier, AFL leverages a separate adversarial network to produce a difficulty score for each input. This difficulty score can then be used to dynamically prioritize learning on hard examples, even in absence of a classifier. In this work, we show AFL's effectiveness in enhancing existing methods in keypoint detection and verify its capability to re-weigh examples based on difficulty.
To Raise or Not To Raise: The Autonomous Learning Rate Question
Jun 16, 2021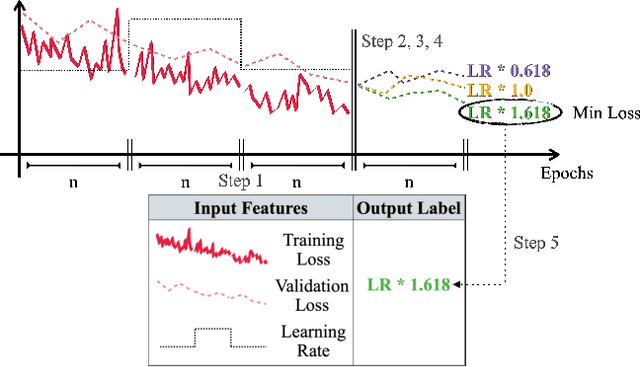

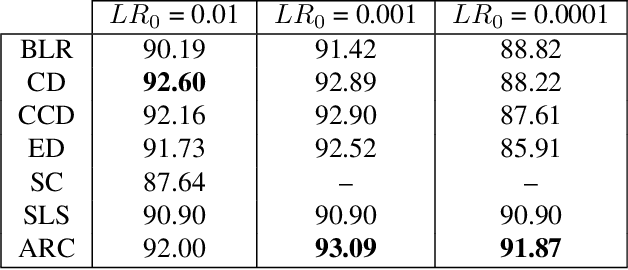
There is a parameter ubiquitous throughout the deep learning world: learning rate. There is likewise a ubiquitous question: what should that learning rate be? The true answer to this question is often tedious and time consuming to obtain, and a great deal of arcane knowledge has accumulated in recent years over how to pick and modify learning rates to achieve optimal training performance. Moreover, the long hours spent carefully crafting the perfect learning rate can come to nothing the moment your network architecture, optimizer, dataset, or initial conditions change ever so slightly. But it need not be this way. We propose a new answer to the great learning rate question: the Autonomous Learning Rate Controller. Find it at https://github.com/fastestimator/ARC
Automating Augmentation Through Random Unidimensional Search
Jun 16, 2021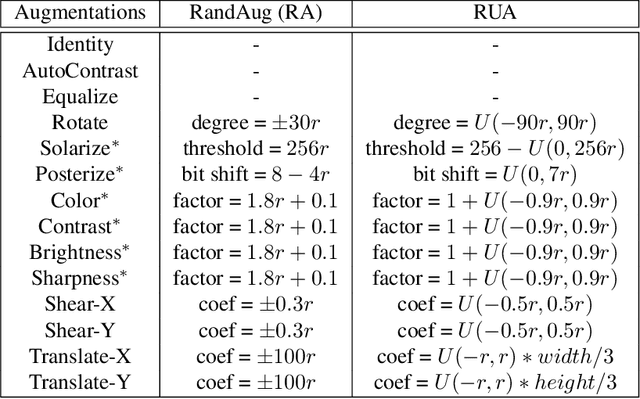
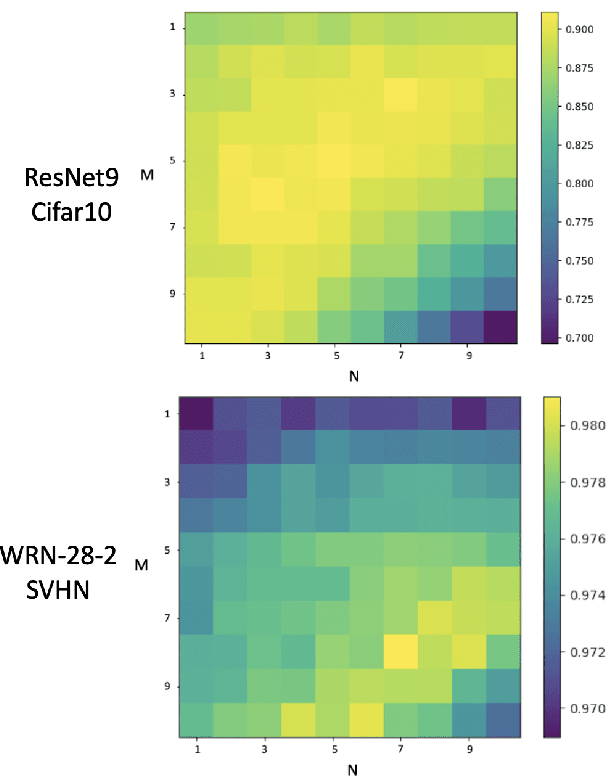
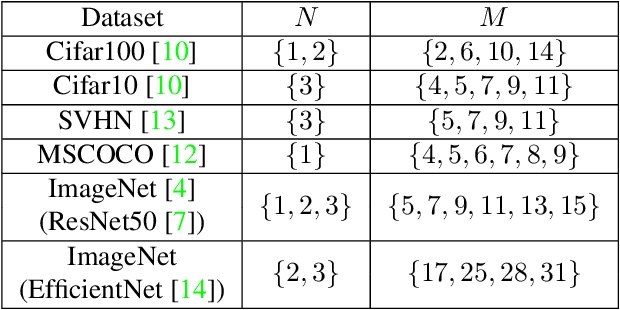
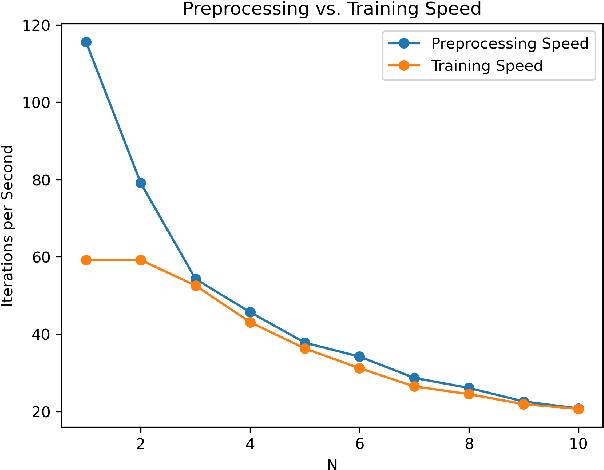
It is no secret amongst deep learning researchers that finding the right data augmentation strategy during training can mean the difference between a state-of-the-art result and a run-of-the-mill ranking. To that end, the community has seen many efforts to automate the process of finding the perfect augmentation procedure for any task at hand. Unfortunately, even recent cutting-edge methods bring massive computational overhead, requiring as many as 100 full model trainings to settle on an ideal configuration. We show how to achieve even better performance in just 7: with Random Unidimensional Augmentation. Source code is available at https://github.com/fastestimator/RUA
FastEstimator: A Deep Learning Library for Fast Prototyping and Productization
Nov 18, 2019
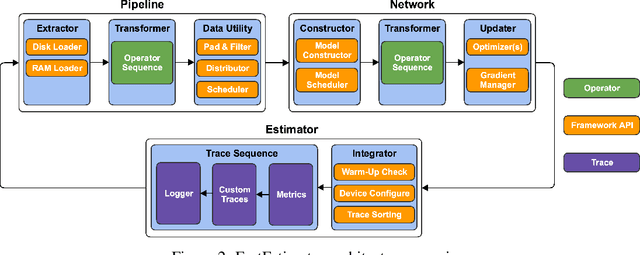

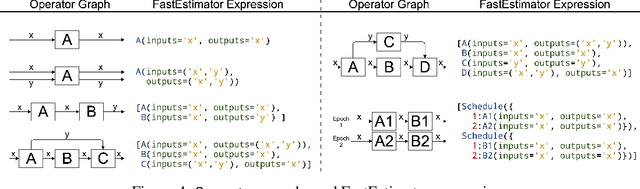
As the complexity of state-of-the-art deep learning models increases by the month, implementation, interpretation, and traceability become ever-more-burdensome challenges for AI practitioners around the world. Several AI frameworks have risen in an effort to stem this tide, but the steady advance of the field has begun to test the bounds of their flexibility, expressiveness, and ease of use. To address these concerns, we introduce a radically flexible high-level open source deep learning framework for both research and industry. We introduce FastEstimator.
Impact of Inference Accelerators on hardware selection
Oct 07, 2019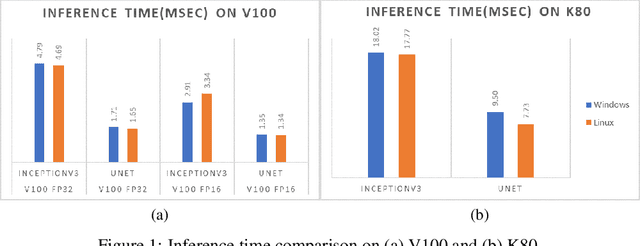
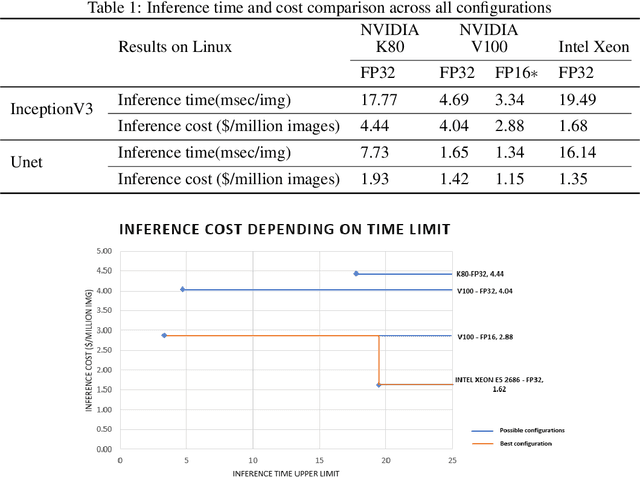
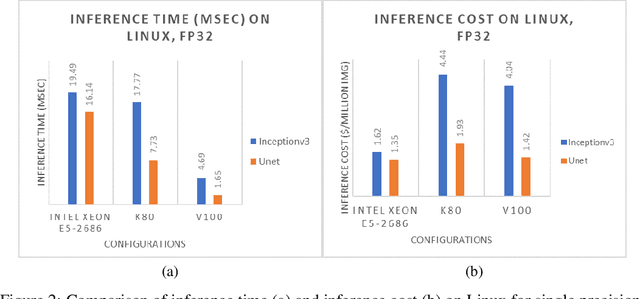

As opportunities for AI-assisted healthcare grow steadily, model deployment faces challenges due to the specific characteristics of the industry. The configuration choice for a production device can impact model performance while influencing operational costs. Moreover, in healthcare some situations might require fast, but not real time, inference. We study different configurations and conduct a cost-performance analysis to determine the optimized hardware for the deployment of a model subject to healthcare domain constraints. We observe that a naive performance comparison may not lead to an optimal configuration selection. In fact, given realistic domain constraints, CPU execution might be preferable to GPU accelerators. Hence, defining beforehand precise expectations for model deployment is crucial.