 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks with Time-Scale Representations
Jul 26, 2021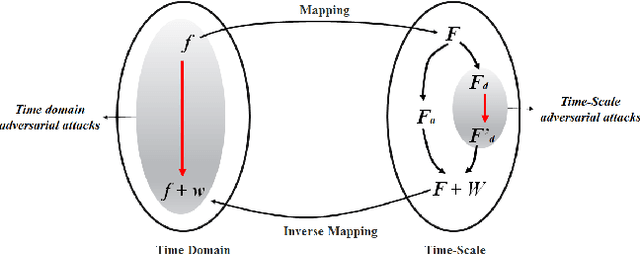
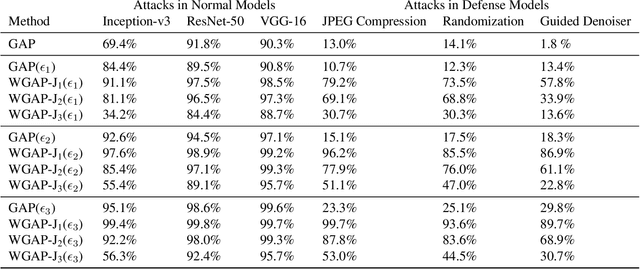
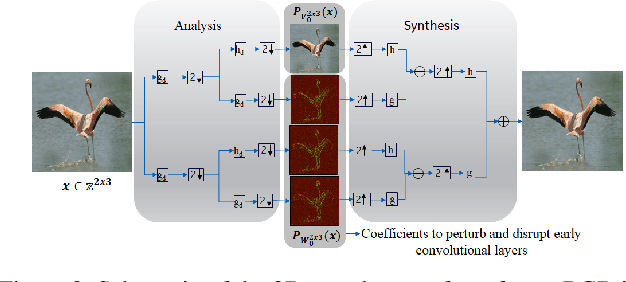

We propose a novel framework for real-time black-box universal attacks which disrupts activations of early convolutional layers in deep learning models. Our hypothesis is that perturbations produced in the wavelet space disrupt early convolutional layers more effectively than perturbations performed in the time domain. The main challenge in adversarial attacks is to preserve low frequency image content while minimally changing the most meaningful high frequency content. To address this, we formulate an optimization problem using time-scale (wavelet) representations as a dual space in three steps. First, we project original images into orthonormal sub-spaces for low and high scales via wavelet coefficients. Second, we perturb wavelet coefficients for high scale projection using a generator network. Third, we generate new adversarial images by projecting back the original coefficients from the low scale and the perturbed coefficients from the high scale sub-space. We provide a theoretical framework that guarantees a dual mapping from time and time-scale domain representations. We compare our results with state-of-the-art black-box attacks from generative-based and gradient-based models. We also verify efficacy against multiple defense methods such as JPEG compression, Guided Denoiser and Comdefend. Our results show that wavelet-based perturbations consistently outperform time-based attacks thus providing new insights into vulnerabilities of deep learning models and could potentially lead to robust architectures or new defense and attack mechanisms by leveraging time-scale representations.
Symbolic Semantic Segmentation and Interpretation of COVID-19 Lung Infections in Chest CT volumes based on Emergent Languages
Aug 22, 2020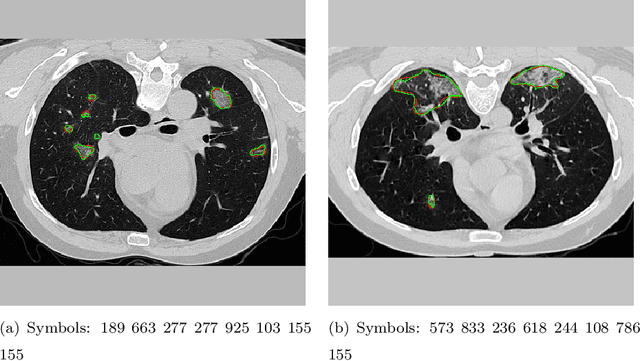
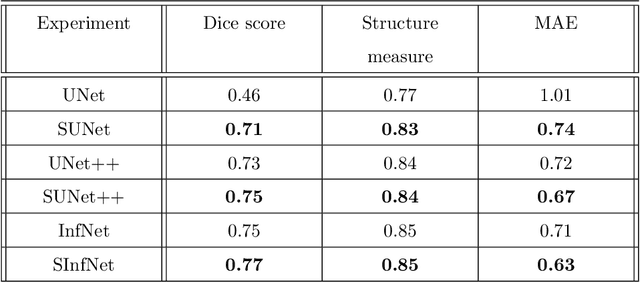
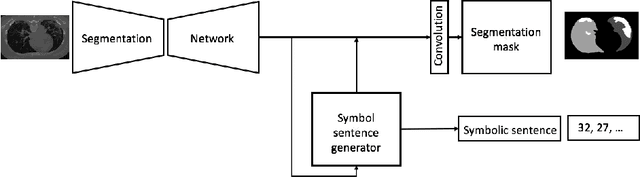
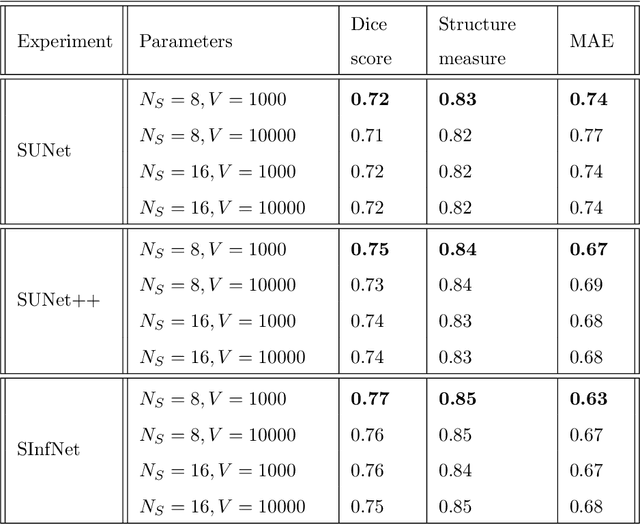
The coronavirus disease (COVID-19) has resulted in a pandemic crippling the a breadth of services critical to daily life. Segmentation of lung infections in computerized tomography (CT) slices could be be used to improve diagnosis and understanding of COVID-19 in patients. Deep learning systems lack interpretability because of their black box nature. Inspired by human communication of complex ideas through language, we propose a symbolic framework based on emergent languages for the segmentation of COVID-19 infections in CT scans of lungs. We model the cooperation between two artificial agents - a Sender and a Receiver. These agents synergistically cooperate using emergent symbolic language to solve the task of semantic segmentation. Our game theoretic approach is to model the cooperation between agents unlike Generative Adversarial Networks (GANs). The Sender retrieves information from one of the higher layers of the deep network and generates a symbolic sentence sampled from a categorical distribution of vocabularies. The Receiver ingests the stream of symbols and cogenerates the segmentation mask. A private emergent language is developed that forms the communication channel used to describe the task of segmentation of COVID infections. We augment existing state of the art semantic segmentation architectures with our symbolic generator to form symbolic segmentation models. Our symbolic segmentation framework achieves state of the art performance for segmentation of lung infections caused by COVID-19. Our results show direct interpretation of symbolic sentences to discriminate between normal and infected regions, infection morphology and image characteristics. We show state of the art results for segmentation of COVID-19 lung infections in CT.
Emergent symbolic language based deep medical image classification
Aug 22, 2020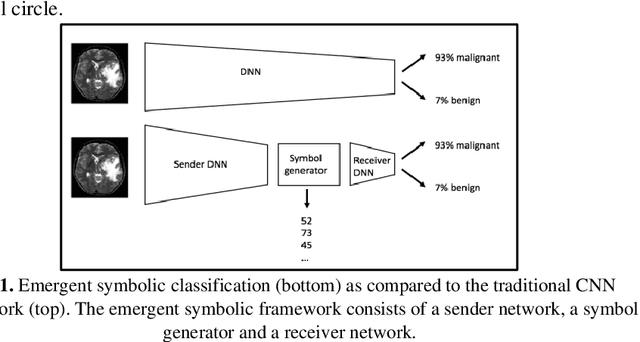
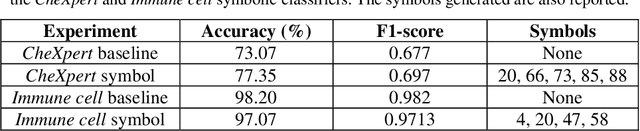
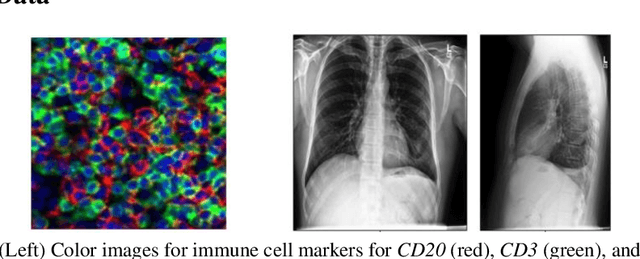
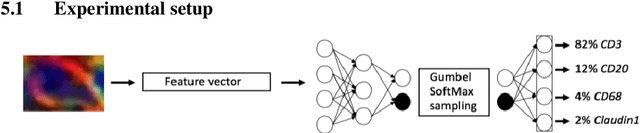
Modern deep learning systems for medical image classification have demonstrated exceptional capabilities for distinguishing between image based medical categories. However, they are severely hindered by their ina-bility to explain the reasoning behind their decision making. This is partly due to the uninterpretable continuous latent representations of neural net-works. Emergent languages (EL) have recently been shown to enhance the capabilities of neural networks by equipping them with symbolic represen-tations in the framework of referential games. Symbolic representations are one of the cornerstones of highly explainable good old fashioned AI (GOFAI) systems. In this work, we demonstrate for the first time, the emer-gence of deep symbolic representations of emergent language in the frame-work of image classification. We show that EL based classification models can perform as well as, if not better than state of the art deep learning mod-els. In addition, they provide a symbolic representation that opens up an entire field of possibilities of interpretable GOFAI methods involving symbol manipulation. We demonstrate the EL classification framework on immune cell marker based cell classification and chest X-ray classification using the CheXpert dataset. Code is available online at https://github.com/AriChow/EL.
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Aug 04, 2020

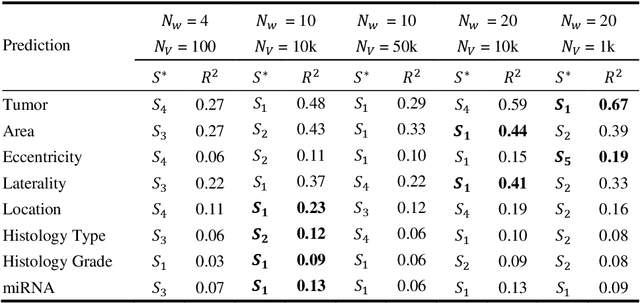

Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.
Image-driven discriminative and generative machine learning algorithms for establishing microstructure-processing relationships
Jul 27, 2020



We investigate methods of microstructure representation for the purpose of predicting processing condition from microstructure image data. A binary alloy (uranium-molybdenum) that is currently under development as a nuclear fuel was studied for the purpose of developing an improved machine learning approach to image recognition, characterization, and building predictive capabilities linking microstructure to processing conditions. Here, we test different microstructure representations and evaluate model performance based on the F1 score. A F1 score of 95.1% was achieved for distinguishing between micrographs corresponding to ten different thermo-mechanical material processing conditions. We find that our newly developed microstructure representation describes image data well, and the traditional approach of utilizing area fractions of different phases is insufficient for distinguishing between multiple classes using a relatively small, imbalanced original data set of 272 images. To explore the applicability of generative methods for supplementing such limited data sets, generative adversarial networks were trained to generate artificial microstructure images. Two different generative networks were trained and tested to assess performance. Challenges and best practices associated with applying machine learning to limited microstructure image data sets is also discussed. Our work has implications for quantitative microstructure analysis, and development of microstructure-processing relationships in limited data sets typical of metallurgical process design studies.
Automated Phenotyping via Cell Auto Training (CAT) on the Cell DIVE Platform
Jul 18, 2020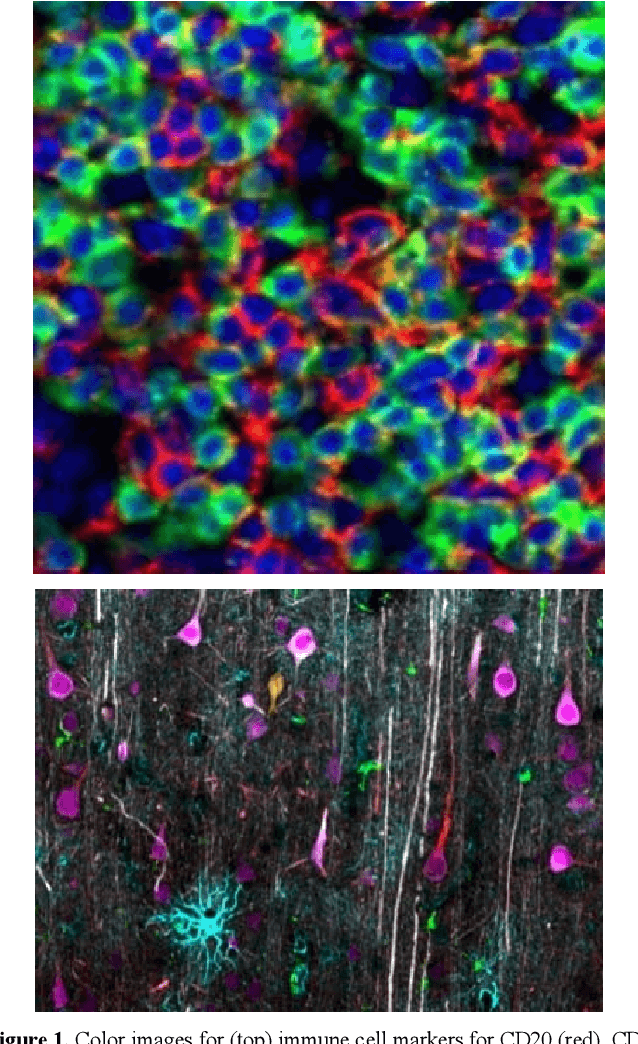
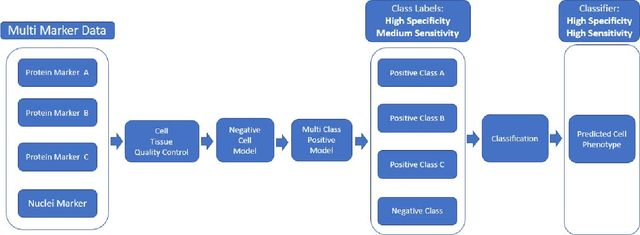
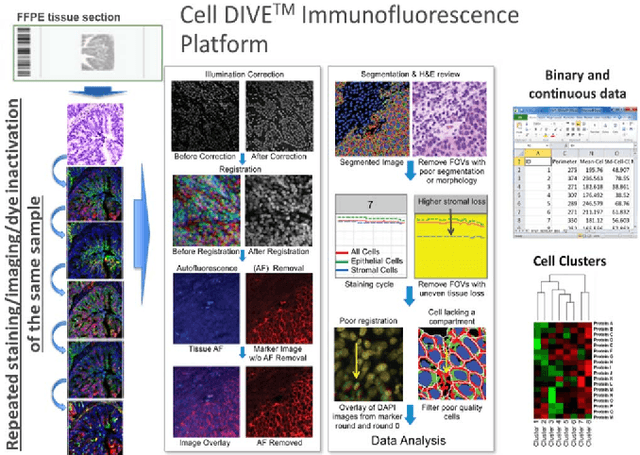
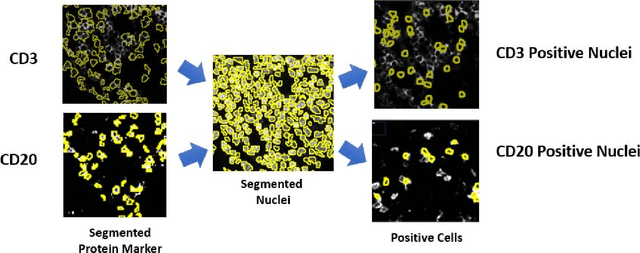
We present a method for automatic cell classification in tissue samples using an automated training set from multiplexed immunofluorescence images. The method utilizes multiple markers stained in situ on a single tissue section on a robust hyperplex immunofluorescence platform (Cell DIVE, GE Healthcare) that provides multi-channel images allowing analysis at single cell/sub-cellular levels. The cell classification method consists of two steps: first, an automated training set from every image is generated using marker-to-cell staining information. This mimics how a pathologist would select samples from a very large cohort at the image level. In the second step, a probability model is inferred from the automated training set. The probabilistic model captures staining patterns in mutually exclusive cell types and builds a single probability model for the data cohort. We have evaluated the proposed approach to classify: i) immune cells in cancer and ii) brain cells in neurological degenerative diseased tissue with average accuracies above 95%.
* 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
ESCELL: Emergent Symbolic Cellular Language
Jul 18, 2020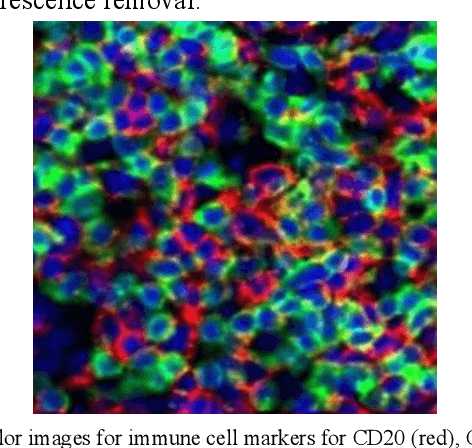
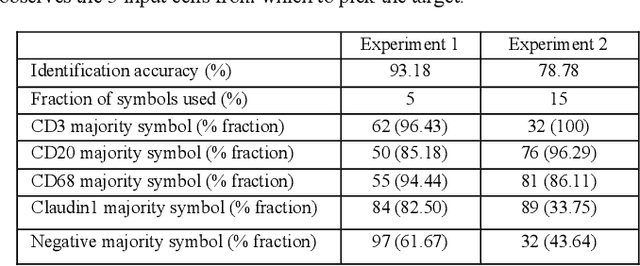
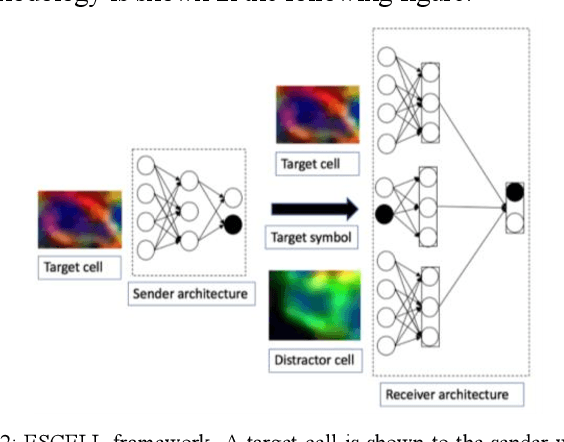
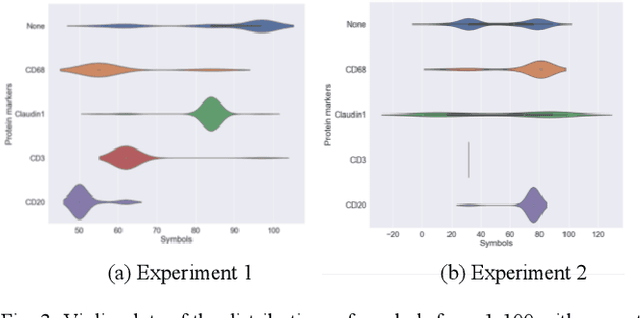
We present ESCELL, a method for developing an emergent symbolic language of communication between multiple agents reasoning about cells. We show how agents are able to cooperate and communicate successfully in the form of symbols similar to human language to accomplish a task in the form of a referential game (Lewis' signaling game). In one form of the game, a sender and a receiver observe a set of cells from 5 different cell phenotypes. The sender is told one cell is a target and is allowed to send one symbol to the receiver from a fixed arbitrary vocabulary size. The receiver relies on the information in the symbol to identify the target cell. We train the sender and receiver networks to develop an innate emergent language between themselves to accomplish this task. We observe that the networks are able to successfully identify cells from 5 different phenotypes with an accuracy of 93.2%. We also introduce a new form of the signaling game where the sender is shown one image instead of all the images that the receiver sees. The networks successfully develop an emergent language to get an identification accuracy of 77.8%.
* IEEE International Symposium on Biomedical Imaging (IEEE ISBI 2020)
FastEstimator: A Deep Learning Library for Fast Prototyping and Productization
Nov 18, 2019
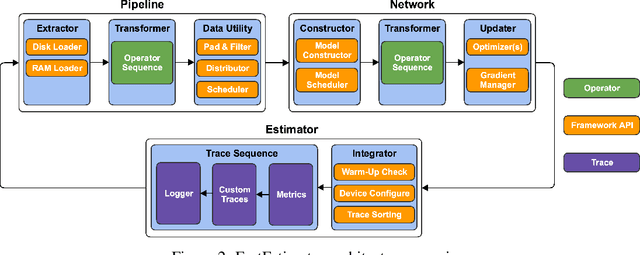

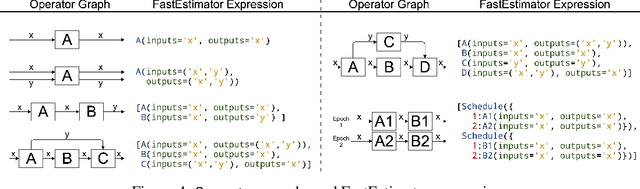
As the complexity of state-of-the-art deep learning models increases by the month, implementation, interpretation, and traceability become ever-more-burdensome challenges for AI practitioners around the world. Several AI frameworks have risen in an effort to stem this tide, but the steady advance of the field has begun to test the bounds of their flexibility, expressiveness, and ease of use. To address these concerns, we introduce a radically flexible high-level open source deep learning framework for both research and industry. We introduce FastEstimator.
Quantifying error contributions of computational steps, algorithms and hyperparameter choices in image classification pipelines
Feb 25, 2019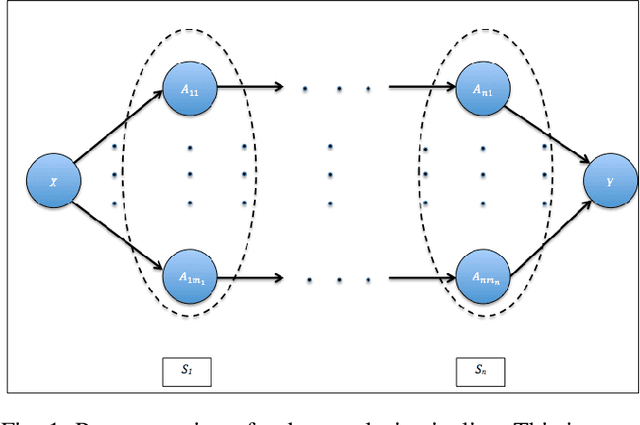
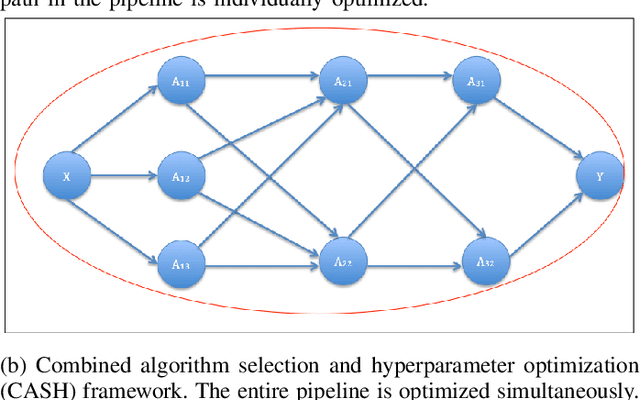
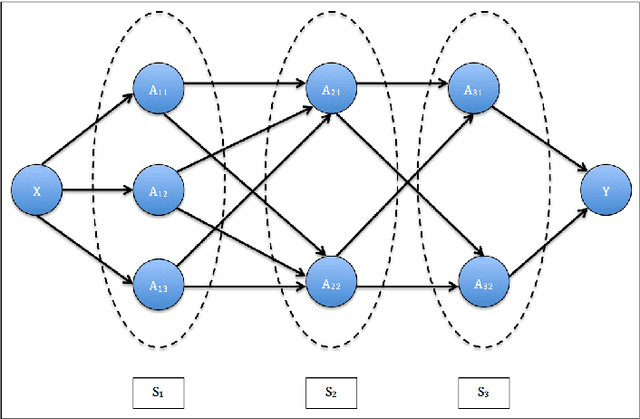
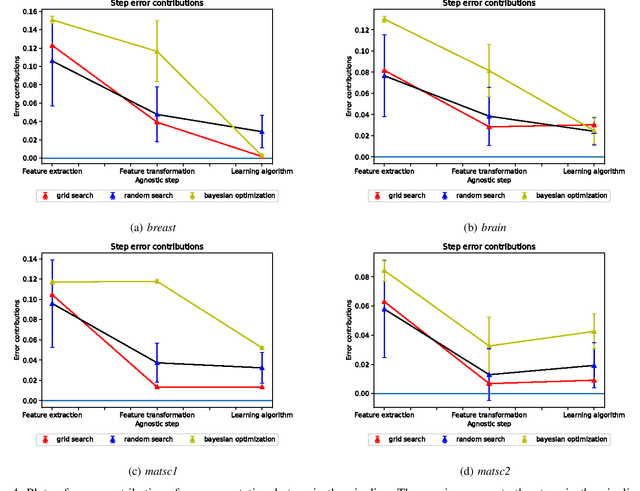
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines typically consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different layers in the pipeline, by computing an error contribution relative to an agnostic choice of algorithms in that layer. We demonstrate our methodology on image classification pipelines. The agnostic methodology quantifies the error contributions from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyper-parameter optimization methods can be used to quantify the error contribution and that random search is able to quantify the contribution more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.
Quantifying contribution and propagation of error from computational steps, algorithms and hyperparameter choices in image classification pipelines
Feb 21, 2019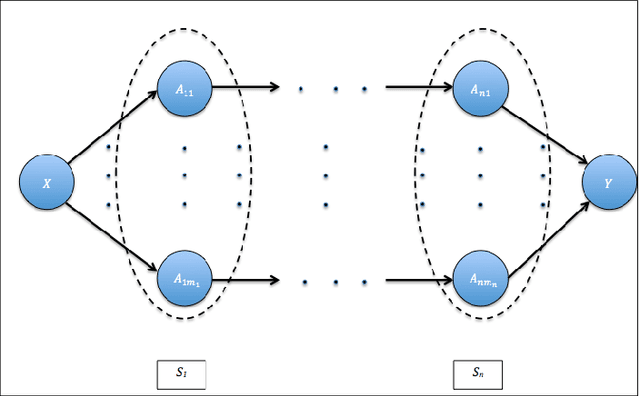

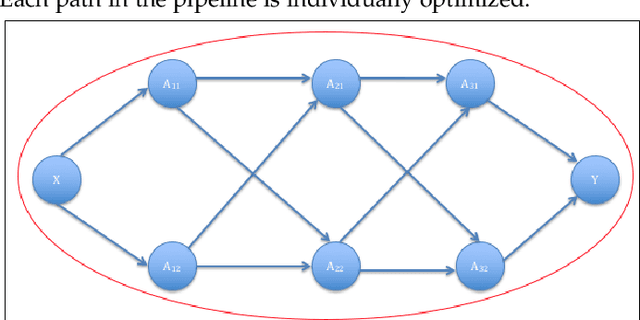
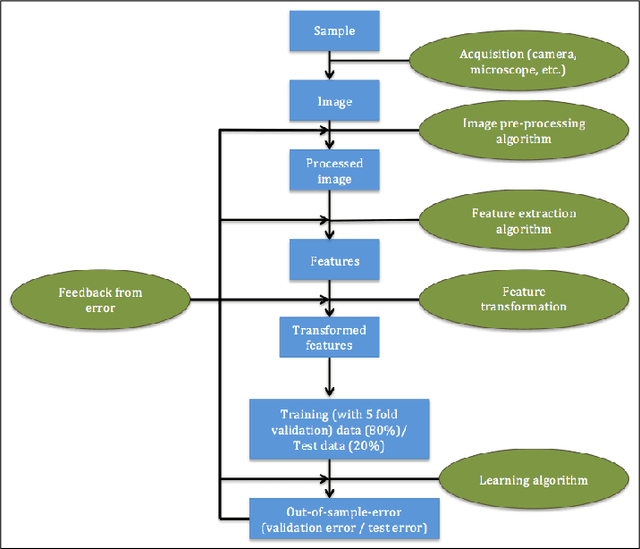
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different components in the pipeline, by computing an error contribution relative to an agnostic choice of computational steps, algorithms and hyperparameters. We also propose a methodology to quantify the propagation of error from individual components of the pipeline with the help of a naive set of benchmark algorithms not involved in the pipeline. We demonstrate our methodology on image classification pipelines. The agnostic and naive methodologies quantify the error contribution and propagation respectively from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyperparameter optimization methods like grid search, random search and Bayesian optimization can be used to quantify the error contribution and propagation, and that random search is able to quantify them more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.