 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL for Mitigating Cascading Failures: Targeted Exploration via Sensitivity Factors
Nov 27, 2024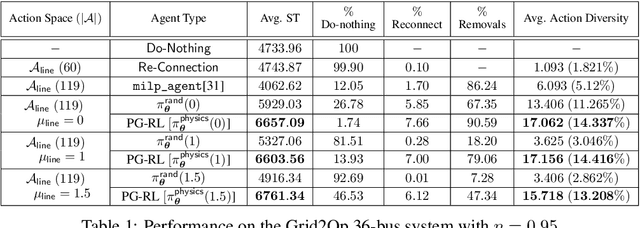
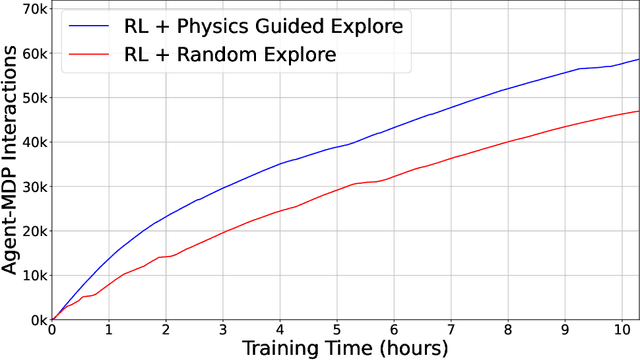
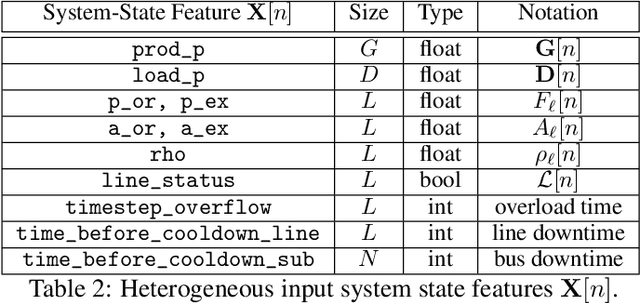

Electricity grid's resiliency and climate change strongly impact one another due to an array of technical and policy-related decisions that impact both. This paper introduces a physics-informed machine learning-based framework to enhance grid's resiliency. Specifically, when encountering disruptive events, this paper designs remedial control actions to prevent blackouts. The proposed Physics-Guided Reinforcement Learning (PG-RL) framework determines effective real-time remedial line-switching actions, considering their impact on power balance, system security, and grid reliability. To identify an effective blackout mitigation policy, PG-RL leverages power-flow sensitivity factors to guide the RL exploration during agent training. Comprehensive evaluations using the Grid2Op platform demonstrate that incorporating physical signals into RL significantly improves resource utilization within electric grids and achieves better blackout mitigation policies - both of which are critical in addressing climate change.
Masked Multi-Step Probabilistic Forecasting for Short-to-Mid-Term Electricity Demand
Feb 14, 2023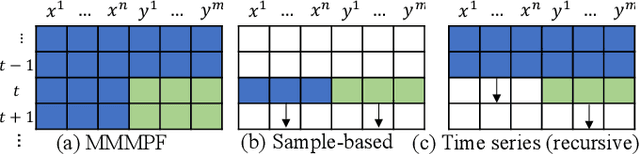
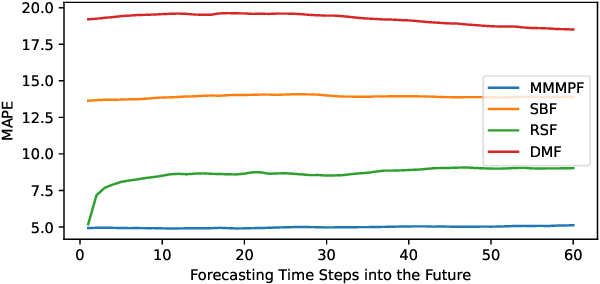
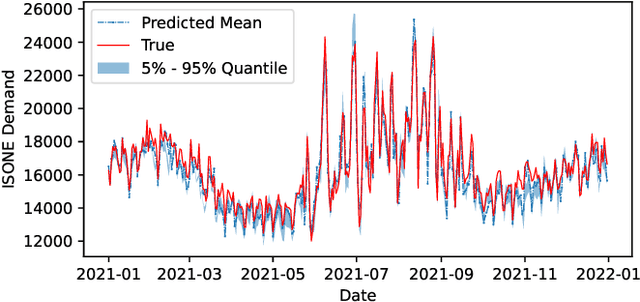
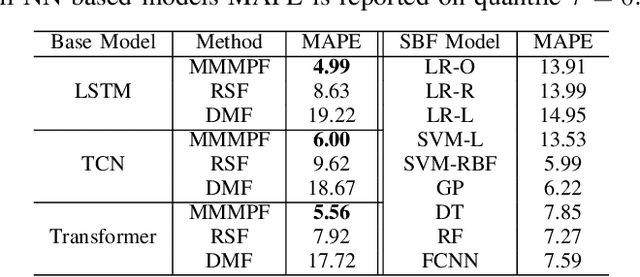
Predicting the demand for electricity with uncertainty helps in planning and operation of the grid to provide reliable supply of power to the consumers. Machine learning (ML)-based demand forecasting approaches can be categorized into (1) sample-based approaches, where each forecast is made independently, and (2) time series regression approaches, where some historical load and other feature information is used. When making a short-to-mid-term electricity demand forecast, some future information is available, such as the weather forecast and calendar variables. However, in existing forecasting models this future information is not fully incorporated. To overcome this limitation of existing approaches, we propose Masked Multi-Step Multivariate Probabilistic Forecasting (MMMPF), a novel and general framework to train any neural network model capable of generating a sequence of outputs, that combines both the temporal information from the past and the known information about the future to make probabilistic predictions. Experiments are performed on a real-world dataset for short-to-mid-term electricity demand forecasting for multiple regions and compared with various ML methods. They show that the proposed MMMPF framework outperforms not only sample-based methods but also existing time-series forecasting models with the exact same base models. Models trainded with MMMPF can also generate desired quantiles to capture uncertainty and enable probabilistic planning for grid of the future.
Masked Multi-Step Multivariate Time Series Forecasting with Future Information
Sep 28, 2022

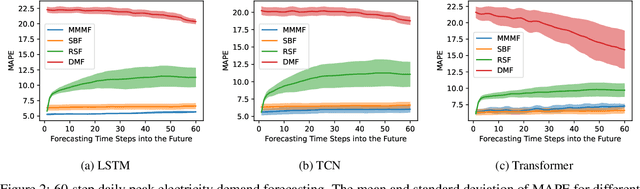

In this paper, we introduce Masked Multi-Step Multivariate Forecasting (MMMF), a novel and general self-supervised learning framework for time series forecasting with known future information. In many real-world forecasting scenarios, some future information is known, e.g., the weather information when making a short-to-mid-term electricity demand forecast, or the oil price forecasts when making an airplane departure forecast. Existing machine learning forecasting frameworks can be categorized into (1) sample-based approaches where each forecast is made independently, and (2) time series regression approaches where the future information is not fully incorporated. To overcome the limitations of existing approaches, we propose MMMF, a framework to train any neural network model capable of generating a sequence of outputs, that combines both the temporal information from the past and the known information about the future to make better predictions. Experiments are performed on two real-world datasets for (1) mid-term electricity demand forecasting, and (2) two-month ahead flight departures forecasting. They show that the proposed MMMF framework outperforms not only sample-based methods but also existing time series forecasting models with the exact same base models. Furthermore, once a neural network model is trained with MMMF, its inference speed is similar to that of the same model trained with traditional regression formulations, thus making MMMF a better alternative to existing regression-trained time series forecasting models if there is some available future information.
Uncertainty-aware Perception Models for Off-road Autonomous Unmanned Ground Vehicles
Sep 22, 2022
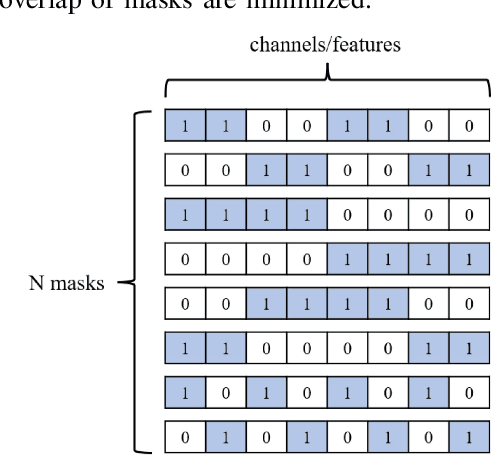
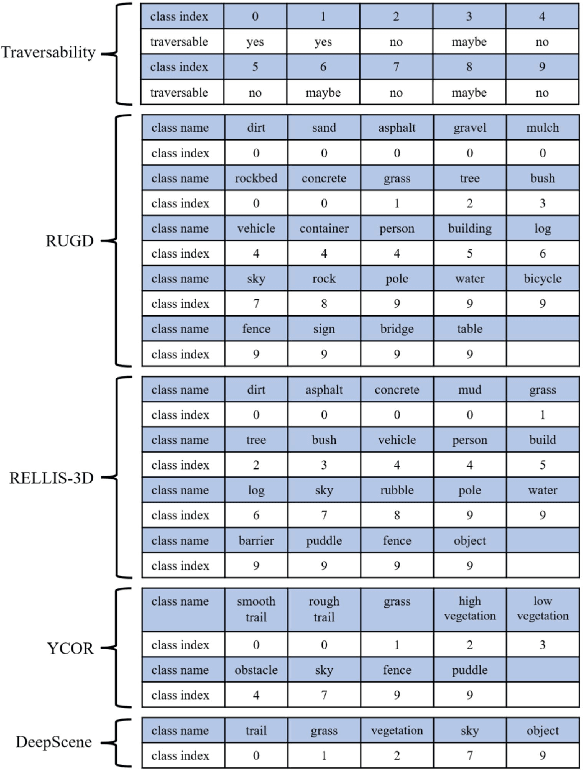
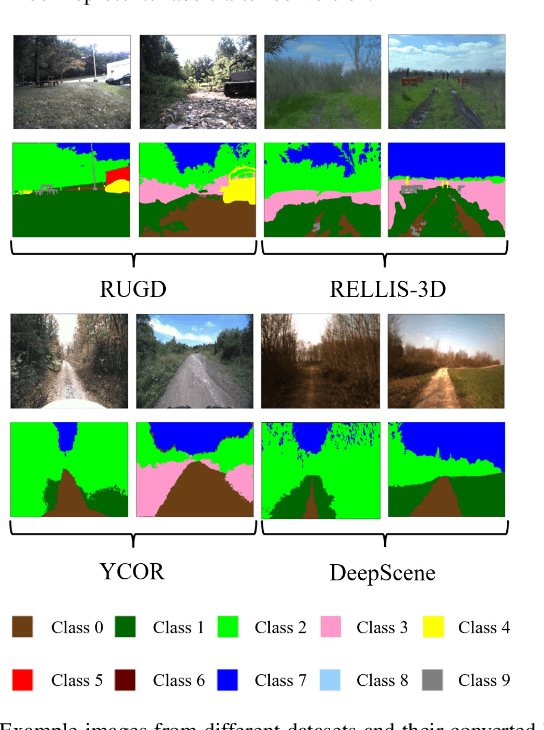
Off-road autonomous unmanned ground vehicles (UGVs) are being developed for military and commercial use to deliver crucial supplies in remote locations, help with mapping and surveillance, and to assist war-fighters in contested environments. Due to complexity of the off-road environments and variability in terrain, lighting conditions, diurnal and seasonal changes, the models used to perceive the environment must handle a lot of input variability. Current datasets used to train perception models for off-road autonomous navigation lack of diversity in seasons, locations, semantic classes, as well as time of day. We test the hypothesis that model trained on a single dataset may not generalize to other off-road navigation datasets and new locations due to the input distribution drift. Additionally, we investigate how to combine multiple datasets to train a semantic segmentation-based environment perception model and we show that training the model to capture uncertainty could improve the model performance by a significant margin. We extend the Masksembles approach for uncertainty quantification to the semantic segmentation task and compare it with Monte Carlo Dropout and standard baselines. Finally, we test the approach against data collected from a UGV platform in a new testing environment. We show that the developed perception model with uncertainty quantification can be feasibly deployed on an UGV to support online perception and navigation tasks.
Adversarial Attacks with Time-Scale Representations
Jul 26, 2021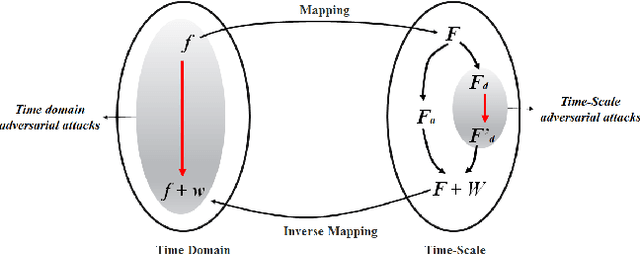
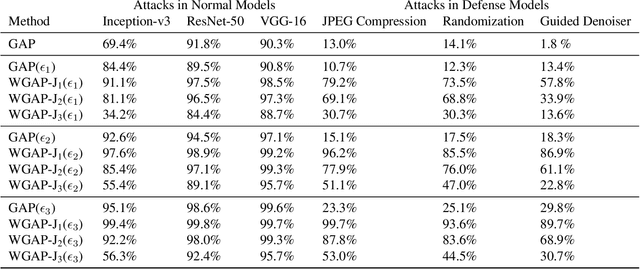
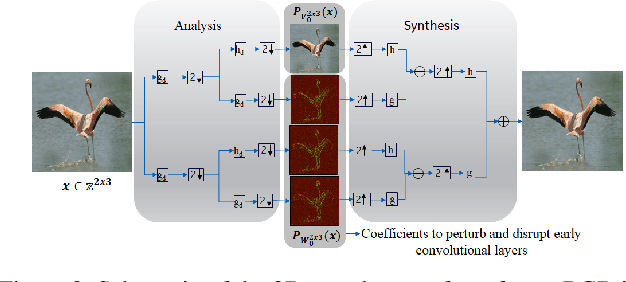

We propose a novel framework for real-time black-box universal attacks which disrupts activations of early convolutional layers in deep learning models. Our hypothesis is that perturbations produced in the wavelet space disrupt early convolutional layers more effectively than perturbations performed in the time domain. The main challenge in adversarial attacks is to preserve low frequency image content while minimally changing the most meaningful high frequency content. To address this, we formulate an optimization problem using time-scale (wavelet) representations as a dual space in three steps. First, we project original images into orthonormal sub-spaces for low and high scales via wavelet coefficients. Second, we perturb wavelet coefficients for high scale projection using a generator network. Third, we generate new adversarial images by projecting back the original coefficients from the low scale and the perturbed coefficients from the high scale sub-space. We provide a theoretical framework that guarantees a dual mapping from time and time-scale domain representations. We compare our results with state-of-the-art black-box attacks from generative-based and gradient-based models. We also verify efficacy against multiple defense methods such as JPEG compression, Guided Denoiser and Comdefend. Our results show that wavelet-based perturbations consistently outperform time-based attacks thus providing new insights into vulnerabilities of deep learning models and could potentially lead to robust architectures or new defense and attack mechanisms by leveraging time-scale representations.
Variational Encoder-based Reliable Classification
Feb 19, 2020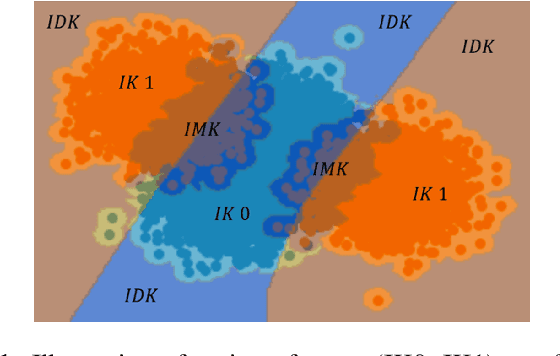
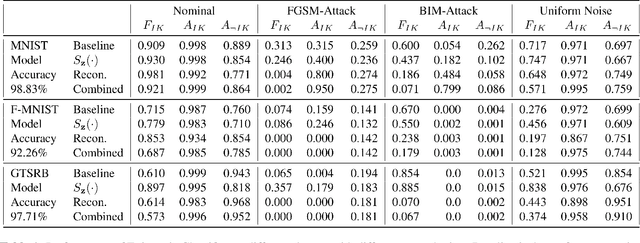
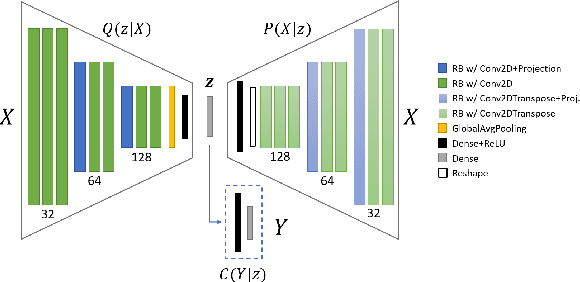
Machine learning models provide statistically impressive results which might be individually unreliable. To provide reliability, we propose an Epistemic Classifier (EC) that can provide justification of its belief using support from the training dataset as well as quality of reconstruction. Our approach is based on modified variational auto-encoders that can identify a semantically meaningful low-dimensional space where perceptually similar instances are close in $\ell_2$-distance too. Our results demonstrate improved reliability of predictions and robust identification of samples with adversarial attacks as compared to baseline of softmax-based thresholding.
Justification-Based Reliability in Machine Learning
Nov 18, 2019
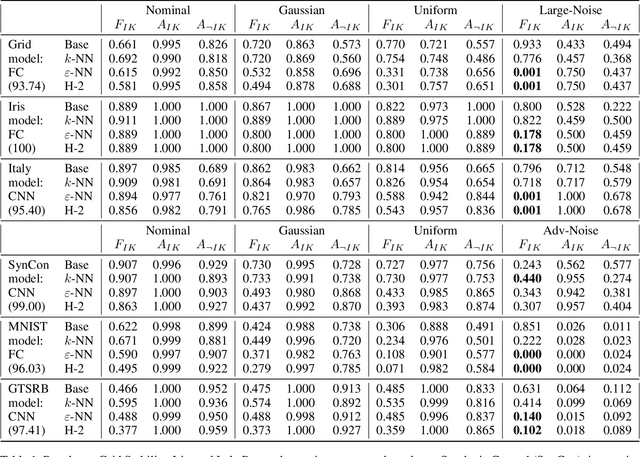

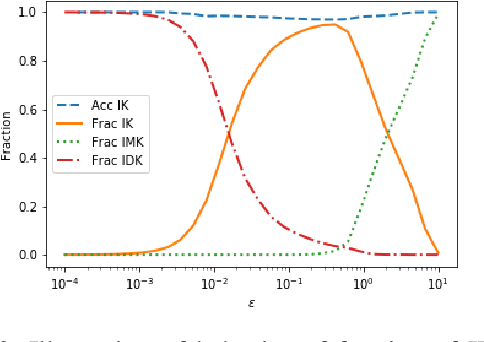
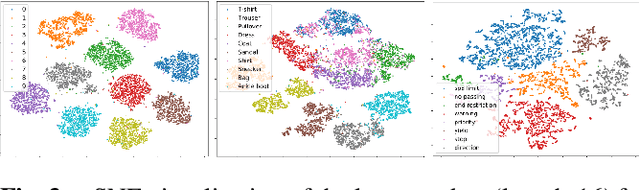
With the advent of Deep Learning, the field of machine learning (ML) has surpassed human-level performance on diverse classification tasks. At the same time, there is a stark need to characterize and quantify reliability of a model's prediction on individual samples. This is especially true in application of such models in safety-critical domains of industrial control and healthcare. To address this need, we link the question of reliability of a model's individual prediction to the epistemic uncertainty of the model's prediction. More specifically, we extend the theory of Justified True Belief (JTB) in epistemology, created to study the validity and limits of human-acquired knowledge, towards characterizing the validity and limits of knowledge in supervised classifiers. We present an analysis of neural network classifiers linking the reliability of its prediction on an input to characteristics of the support gathered from the input and latent spaces of the network. We hypothesize that the JTB analysis exposes the epistemic uncertainty (or ignorance) of a model with respect to its inference, thereby allowing for the inference to be only as strong as the justification permits. We explore various forms of support (for e.g., k-nearest neighbors (k-NN) and l_p-norm based) generated for an input, using the training data to construct a justification for the prediction with that input. Through experiments conducted on simulated and real datasets, we demonstrate that our approach can provide reliability for individual predictions and characterize regions where such reliability cannot be ascertained.
Design of intentional backdoors in sequential models
Feb 26, 2019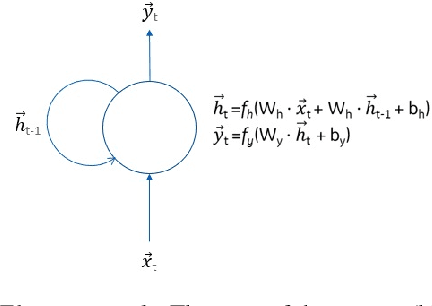
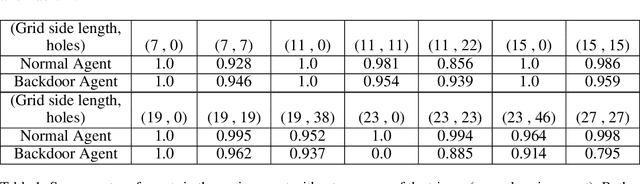
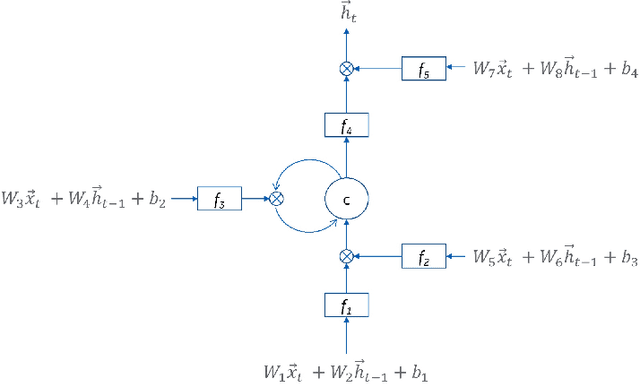
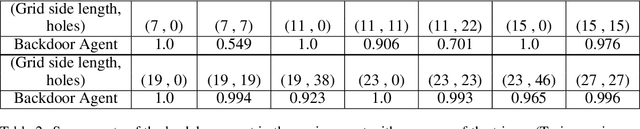
Recent work has demonstrated robust mechanisms by which attacks can be orchestrated on machine learning models. In contrast to adversarial examples, backdoor or trojan attacks embed surgically modified samples with targeted labels in the model training process to cause the targeted model to learn to misclassify chosen samples in the presence of specific triggers, while keeping the model performance stable across other nominal samples. However, current published research on trojan attacks mainly focuses on classification problems, which ignores sequential dependency between inputs. In this paper, we propose methods to discreetly introduce and exploit novel backdoor attacks within a sequential decision-making agent, such as a reinforcement learning agent, by training multiple benign and malicious policies within a single long short-term memory (LSTM) network. We demonstrate the effectiveness as well as the damaging impact of such attacks through initial outcomes generated from our approach, employed on grid-world environments. We also provide evidence as well as intuition on how the trojan trigger and malicious policy is activated. Challenges with network size and unintentional triggers are identified and analogies with adversarial examples are also discussed. In the end, we propose potential approaches to defend against or serve as early detection for such attacks. Results of our work can also be extended to many applications of LSTM and recurrent networks.
Nonlinear Unknown Input and State Estimation Algorithm in Mobile Robots
Apr 09, 2018

This technical report provides the description and the derivation of a novel nonlinear unknown input and state estimation algorithm (NUISE) for mobile robots. The algorithm is designed for real-world robots with nonlinear dynamic models and subject to stochastic noises on sensing and actuation. Leveraging sensor readings and planned control commands, the algorithm detects and quantifies anomalies on both sensors and actuators. Later, we elaborate the dynamic models of two distinctive mobile robots for the purpose of demonstrating the application of NUISE. This report serves as a supplementary document for [1].
Symbolic Analysis-based Reduced Order Markov Modeling of Time Series Data
Sep 26, 2017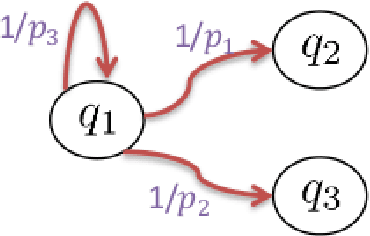
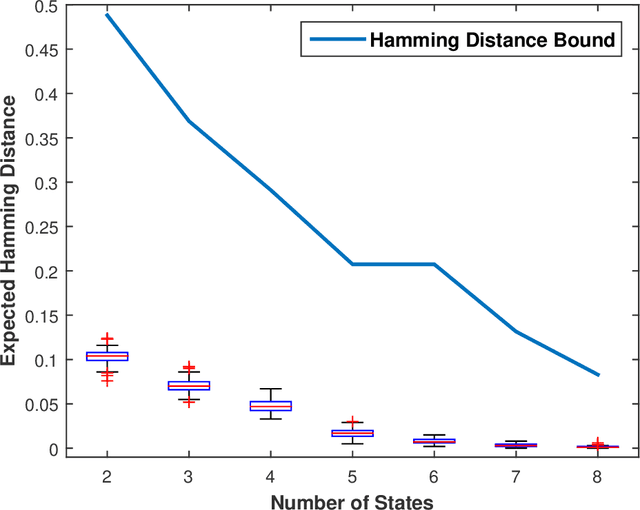
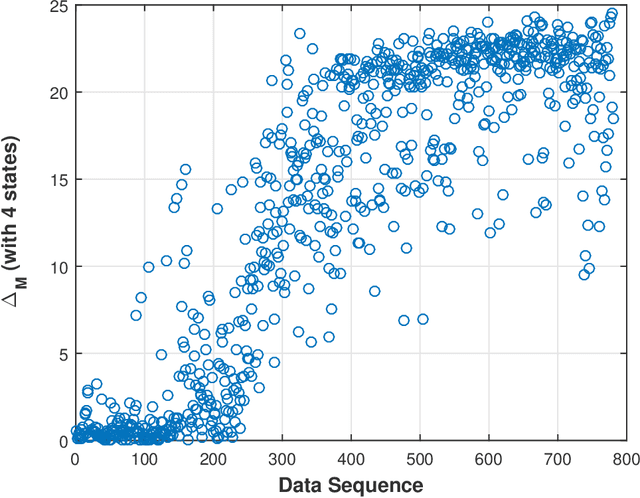
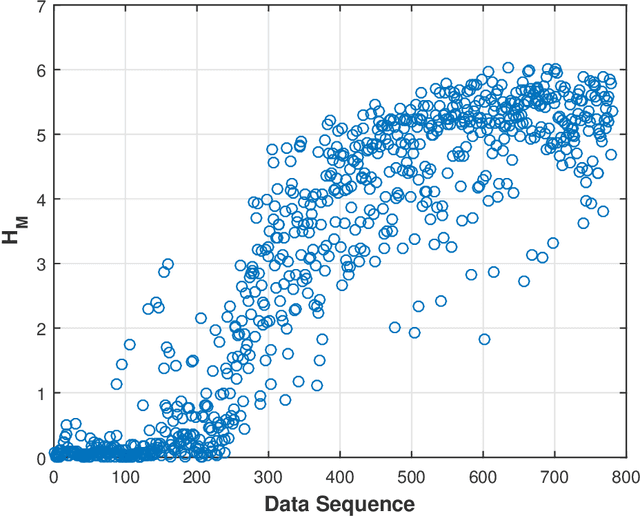
This paper presents a technique for reduced-order Markov modeling for compact representation of time-series data. In this work, symbolic dynamics-based tools have been used to infer an approximate generative Markov model. The time-series data are first symbolized by partitioning the continuous measurement space of the signal and then, the discrete sequential data are modeled using symbolic dynamics. In the proposed approach, the size of temporal memory of the symbol sequence is estimated from spectral properties of the resulting stochastic matrix corresponding to a first-order Markov model of the symbol sequence. Then, hierarchical clustering is used to represent the states of the corresponding full-state Markov model to construct a reduced-order or size Markov model with a non-deterministic algebraic structure. Subsequently, the parameters of the reduced-order Markov model are identified from the original model by making use of a Bayesian inference rule. The final model is selected using information-theoretic criteria. The proposed concept is elucidated and validated on two different data sets as examples. The first example analyzes a set of pressure data from a swirl-stabilized combustor, where controlled protocols are used to induce flame instabilities. Variations in the complexity of the derived Markov model represent how the system operating condition changes from a stable to an unstable combustion regime. In the second example, the data set is taken from NASA's data repository for prognostics of bearings on rotating shafts. We show that, even with a very small state-space, the reduced-order models are able to achieve comparable performance and that the proposed approach provides flexibility in the selection of a final model for representation and learning.