 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks with Time-Scale Representations
Jul 26, 2021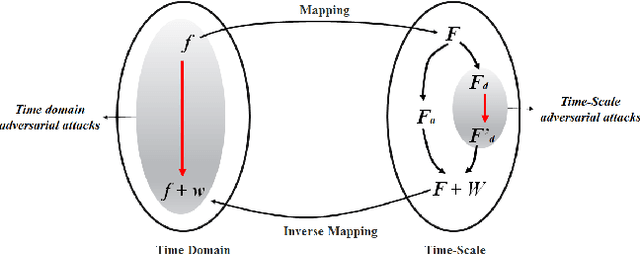
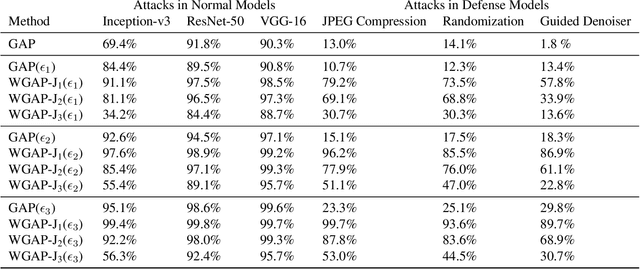
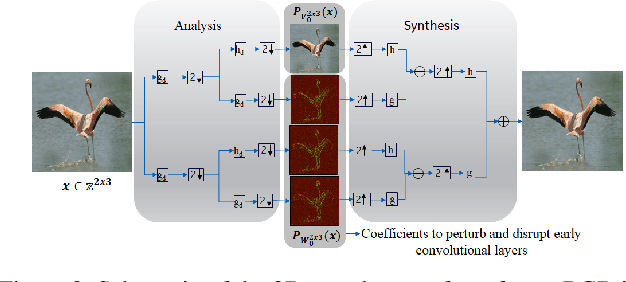

We propose a novel framework for real-time black-box universal attacks which disrupts activations of early convolutional layers in deep learning models. Our hypothesis is that perturbations produced in the wavelet space disrupt early convolutional layers more effectively than perturbations performed in the time domain. The main challenge in adversarial attacks is to preserve low frequency image content while minimally changing the most meaningful high frequency content. To address this, we formulate an optimization problem using time-scale (wavelet) representations as a dual space in three steps. First, we project original images into orthonormal sub-spaces for low and high scales via wavelet coefficients. Second, we perturb wavelet coefficients for high scale projection using a generator network. Third, we generate new adversarial images by projecting back the original coefficients from the low scale and the perturbed coefficients from the high scale sub-space. We provide a theoretical framework that guarantees a dual mapping from time and time-scale domain representations. We compare our results with state-of-the-art black-box attacks from generative-based and gradient-based models. We also verify efficacy against multiple defense methods such as JPEG compression, Guided Denoiser and Comdefend. Our results show that wavelet-based perturbations consistently outperform time-based attacks thus providing new insights into vulnerabilities of deep learning models and could potentially lead to robust architectures or new defense and attack mechanisms by leveraging time-scale representations.
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Aug 04, 2020


Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.