 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Classification by Description: Extending CLIP's Limits of Part Attributes Recognition
Dec 18, 2024



In this study, we define and tackle zero shot "real" classification by description, a novel task that evaluates the ability of Vision-Language Models (VLMs) like CLIP to classify objects based solely on descriptive attributes, excluding object class names. This approach highlights the current limitations of VLMs in understanding intricate object descriptions, pushing these models beyond mere object recognition. To facilitate this exploration, we introduce a new challenge and release description data for six popular fine-grained benchmarks, which omit object names to encourage genuine zero-shot learning within the research community. Additionally, we propose a method to enhance CLIP's attribute detection capabilities through targeted training using ImageNet21k's diverse object categories, paired with rich attribute descriptions generated by large language models. Furthermore, we introduce a modified CLIP architecture that leverages multiple resolutions to improve the detection of fine-grained part attributes. Through these efforts, we broaden the understanding of part-attribute recognition in CLIP, improving its performance in fine-grained classification tasks across six popular benchmarks, as well as in the PACO dataset, a widely used benchmark for object-attribute recognition. Code is available at: https://github.com/ethanbar11/grounding_ge_public.
IMPUS: Image Morphing with Perceptually-Uniform Sampling Using Diffusion Models
Nov 12, 2023
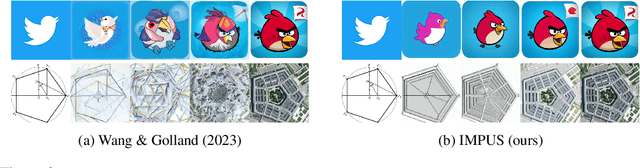
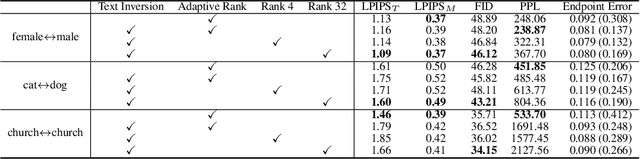

We present a diffusion-based image morphing approach with perceptually-uniform sampling (IMPUS) that produces smooth, direct, and realistic interpolations given an image pair. A latent diffusion model has distinct conditional distributions and data embeddings for each of the two images, especially when they are from different classes. To bridge this gap, we interpolate in the locally linear and continuous text embedding space and Gaussian latent space. We first optimize the endpoint text embeddings and then map the images to the latent space using a probability flow ODE. Unlike existing work that takes an indirect morphing path, we show that the model adaptation yields a direct path and suppresses ghosting artifacts in the interpolated images. To achieve this, we propose an adaptive bottleneck constraint based on a novel relative perceptual path diversity score that automatically controls the bottleneck size and balances the diversity along the path with its directness. We also propose a perceptually-uniform sampling technique that enables visually smooth changes between the interpolated images. Extensive experiments validate that our IMPUS can achieve smooth, direct, and realistic image morphing and be applied to other image generation tasks.
Probabilistic and Semantic Descriptions of Image Manifolds and Their Applications
Jul 10, 2023This paper begins with a description of methods for estimating probability density functions for images that reflects the observation that such data is usually constrained to lie in restricted regions of the high-dimensional image space - not every pattern of pixels is an image. It is common to say that images lie on a lower-dimensional manifold in the high-dimensional space. However, although images may lie on such lower-dimensional manifolds, it is not the case that all points on the manifold have an equal probability of being images. Images are unevenly distributed on the manifold, and our task is to devise ways to model this distribution as a probability distribution. In pursuing this goal, we consider generative models that are popular in AI and computer vision community. For our purposes, generative/probabilistic models should have the properties of 1) sample generation: it should be possible to sample from this distribution according to the modelled density function, and 2) probability computation: given a previously unseen sample from the dataset of interest, one should be able to compute the probability of the sample, at least up to a normalising constant. To this end, we investigate the use of methods such as normalising flow and diffusion models. We then show that such probabilistic descriptions can be used to construct defences against adversarial attacks. In addition to describing the manifold in terms of density, we also consider how semantic interpretations can be used to describe points on the manifold. To this end, we consider an emergent language framework which makes use of variational encoders to produce a disentangled representation of points that reside on a given manifold. Trajectories between points on a manifold can then be described in terms of evolving semantic descriptions.
Understanding the Unforeseen via the Intentional Stance
Nov 01, 2022



We present an architecture and system for understanding novel behaviors of an observed agent. The two main features of our approach are the adoption of Dennett's intentional stance and analogical reasoning as one of the main computational mechanisms for understanding unforeseen experiences. Our approach uses analogy with past experiences to construct hypothetical rationales that explain the behavior of an observed agent. Moreover, we view analogies as partial; thus multiple past experiences can be blended to analogically explain an unforeseen event, leading to greater inferential flexibility. We argue that this approach results in more meaningful explanations of observed behavior than approaches based on surface-level comparisons. A key advantage of behavior explanation over classification is the ability to i) take appropriate responses based on reasoning and ii) make non-trivial predictions that allow for the verification of the hypothesized explanation. We provide a simple use case to demonstrate novel experience understanding through analogy in a gas station environment.
Adaptive Test-Time Defense with the Manifold Hypothesis
Oct 27, 2022In this work, we formulate a novel framework of adversarial robustness using the manifold hypothesis. Our framework provides sufficient conditions for defending against adversarial examples. We develop a test-time defense method with our formulation and variational inference. The developed approach combines manifold learning with the Bayesian framework to provide adversarial robustness without the need for adversarial training. We show that our proposed approach can provide adversarial robustness even if attackers are aware of existence of test-time defense. In additions, our approach can also serve as a test-time defense mechanism for variational autoencoders.
Adversarial Attacks with Time-Scale Representations
Jul 26, 2021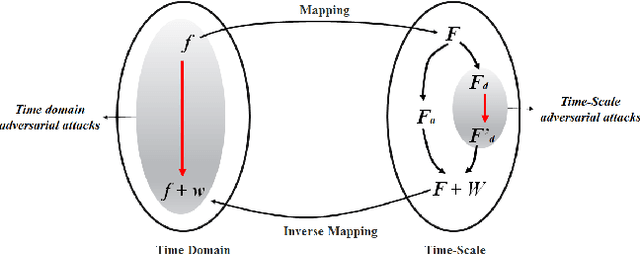
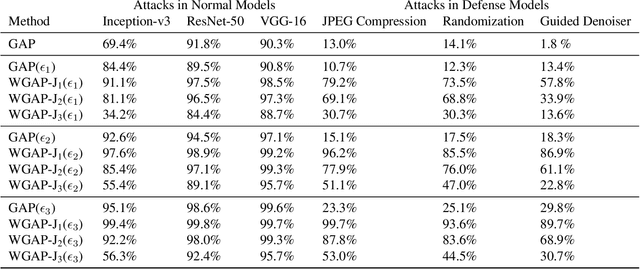
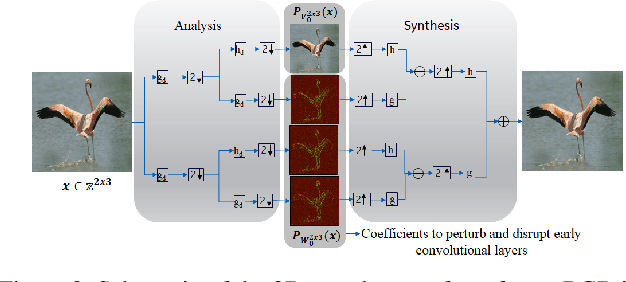

We propose a novel framework for real-time black-box universal attacks which disrupts activations of early convolutional layers in deep learning models. Our hypothesis is that perturbations produced in the wavelet space disrupt early convolutional layers more effectively than perturbations performed in the time domain. The main challenge in adversarial attacks is to preserve low frequency image content while minimally changing the most meaningful high frequency content. To address this, we formulate an optimization problem using time-scale (wavelet) representations as a dual space in three steps. First, we project original images into orthonormal sub-spaces for low and high scales via wavelet coefficients. Second, we perturb wavelet coefficients for high scale projection using a generator network. Third, we generate new adversarial images by projecting back the original coefficients from the low scale and the perturbed coefficients from the high scale sub-space. We provide a theoretical framework that guarantees a dual mapping from time and time-scale domain representations. We compare our results with state-of-the-art black-box attacks from generative-based and gradient-based models. We also verify efficacy against multiple defense methods such as JPEG compression, Guided Denoiser and Comdefend. Our results show that wavelet-based perturbations consistently outperform time-based attacks thus providing new insights into vulnerabilities of deep learning models and could potentially lead to robust architectures or new defense and attack mechanisms by leveraging time-scale representations.
Symbolic Semantic Segmentation and Interpretation of COVID-19 Lung Infections in Chest CT volumes based on Emergent Languages
Aug 22, 2020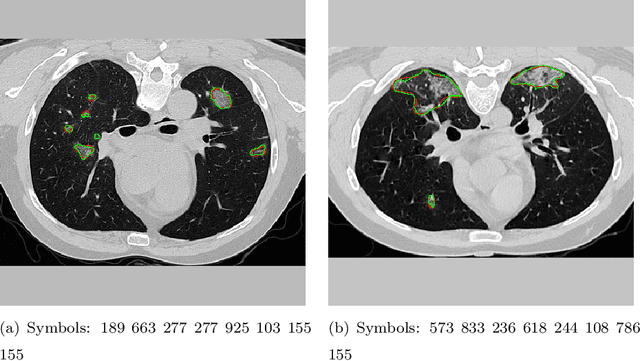
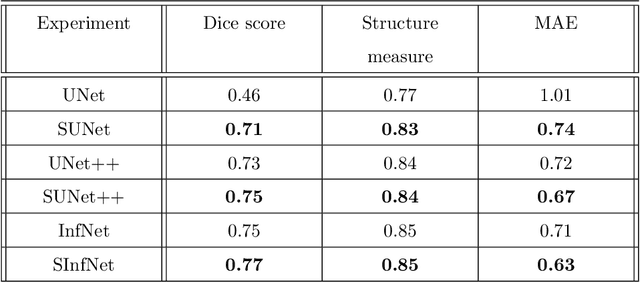
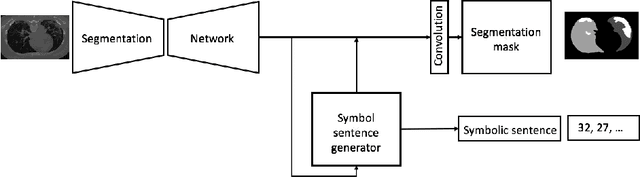
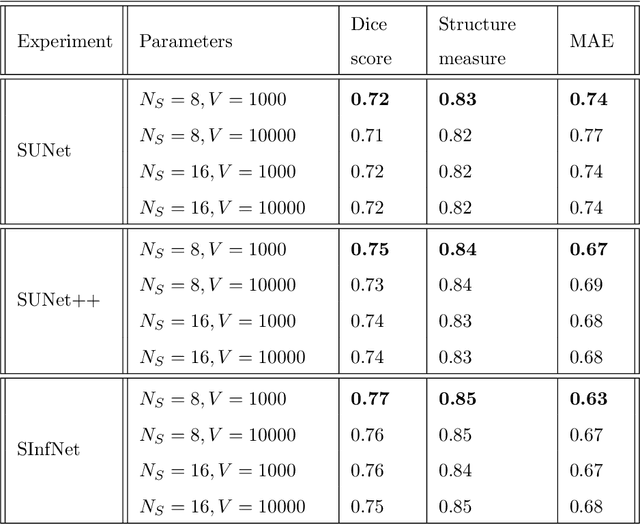
The coronavirus disease (COVID-19) has resulted in a pandemic crippling the a breadth of services critical to daily life. Segmentation of lung infections in computerized tomography (CT) slices could be be used to improve diagnosis and understanding of COVID-19 in patients. Deep learning systems lack interpretability because of their black box nature. Inspired by human communication of complex ideas through language, we propose a symbolic framework based on emergent languages for the segmentation of COVID-19 infections in CT scans of lungs. We model the cooperation between two artificial agents - a Sender and a Receiver. These agents synergistically cooperate using emergent symbolic language to solve the task of semantic segmentation. Our game theoretic approach is to model the cooperation between agents unlike Generative Adversarial Networks (GANs). The Sender retrieves information from one of the higher layers of the deep network and generates a symbolic sentence sampled from a categorical distribution of vocabularies. The Receiver ingests the stream of symbols and cogenerates the segmentation mask. A private emergent language is developed that forms the communication channel used to describe the task of segmentation of COVID infections. We augment existing state of the art semantic segmentation architectures with our symbolic generator to form symbolic segmentation models. Our symbolic segmentation framework achieves state of the art performance for segmentation of lung infections caused by COVID-19. Our results show direct interpretation of symbolic sentences to discriminate between normal and infected regions, infection morphology and image characteristics. We show state of the art results for segmentation of COVID-19 lung infections in CT.
Emergent symbolic language based deep medical image classification
Aug 22, 2020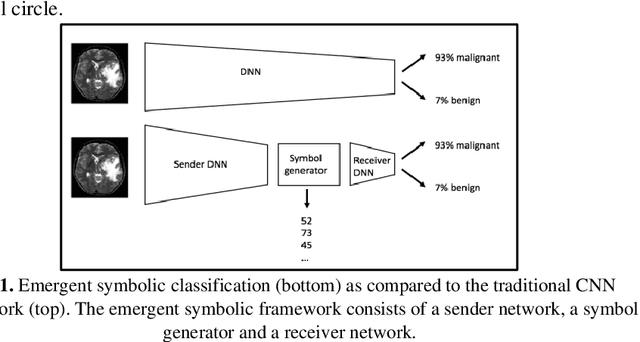
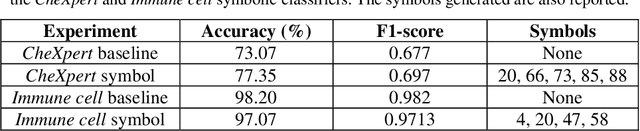
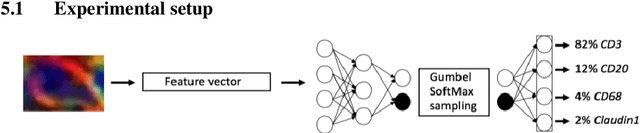
Modern deep learning systems for medical image classification have demonstrated exceptional capabilities for distinguishing between image based medical categories. However, they are severely hindered by their ina-bility to explain the reasoning behind their decision making. This is partly due to the uninterpretable continuous latent representations of neural net-works. Emergent languages (EL) have recently been shown to enhance the capabilities of neural networks by equipping them with symbolic represen-tations in the framework of referential games. Symbolic representations are one of the cornerstones of highly explainable good old fashioned AI (GOFAI) systems. In this work, we demonstrate for the first time, the emer-gence of deep symbolic representations of emergent language in the frame-work of image classification. We show that EL based classification models can perform as well as, if not better than state of the art deep learning mod-els. In addition, they provide a symbolic representation that opens up an entire field of possibilities of interpretable GOFAI methods involving symbol manipulation. We demonstrate the EL classification framework on immune cell marker based cell classification and chest X-ray classification using the CheXpert dataset. Code is available online at https://github.com/AriChow/EL.
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Aug 04, 2020

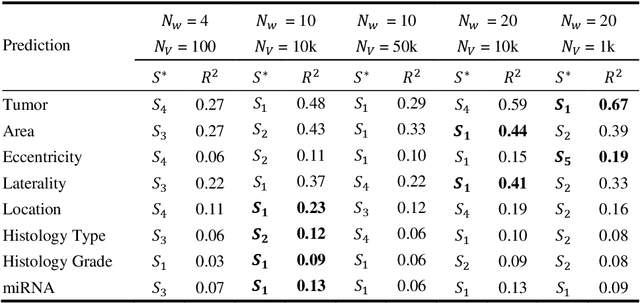

Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.
ESCELL: Emergent Symbolic Cellular Language
Jul 18, 2020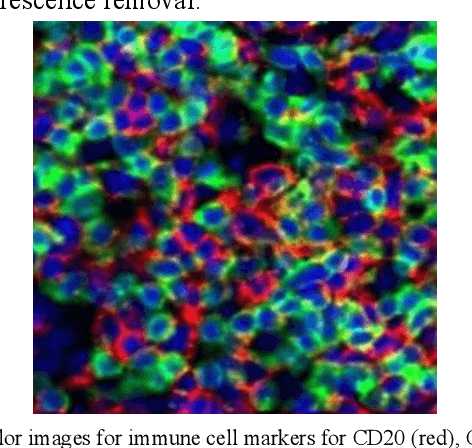
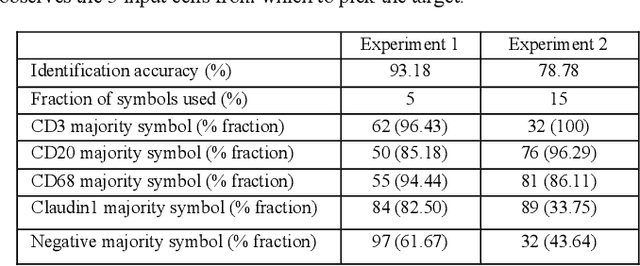
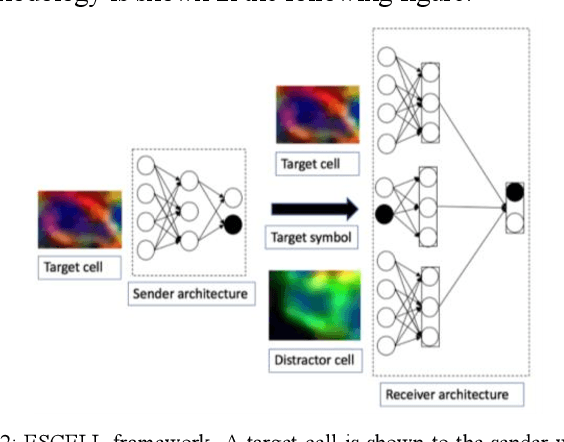
We present ESCELL, a method for developing an emergent symbolic language of communication between multiple agents reasoning about cells. We show how agents are able to cooperate and communicate successfully in the form of symbols similar to human language to accomplish a task in the form of a referential game (Lewis' signaling game). In one form of the game, a sender and a receiver observe a set of cells from 5 different cell phenotypes. The sender is told one cell is a target and is allowed to send one symbol to the receiver from a fixed arbitrary vocabulary size. The receiver relies on the information in the symbol to identify the target cell. We train the sender and receiver networks to develop an innate emergent language between themselves to accomplish this task. We observe that the networks are able to successfully identify cells from 5 different phenotypes with an accuracy of 93.2%. We also introduce a new form of the signaling game where the sender is shown one image instead of all the images that the receiver sees. The networks successfully develop an emergent language to get an identification accuracy of 77.8%.
* IEEE International Symposium on Biomedical Imaging (IEEE ISBI 2020)