 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Classification by Description: Extending CLIP's Limits of Part Attributes Recognition
Dec 18, 2024



In this study, we define and tackle zero shot "real" classification by description, a novel task that evaluates the ability of Vision-Language Models (VLMs) like CLIP to classify objects based solely on descriptive attributes, excluding object class names. This approach highlights the current limitations of VLMs in understanding intricate object descriptions, pushing these models beyond mere object recognition. To facilitate this exploration, we introduce a new challenge and release description data for six popular fine-grained benchmarks, which omit object names to encourage genuine zero-shot learning within the research community. Additionally, we propose a method to enhance CLIP's attribute detection capabilities through targeted training using ImageNet21k's diverse object categories, paired with rich attribute descriptions generated by large language models. Furthermore, we introduce a modified CLIP architecture that leverages multiple resolutions to improve the detection of fine-grained part attributes. Through these efforts, we broaden the understanding of part-attribute recognition in CLIP, improving its performance in fine-grained classification tasks across six popular benchmarks, as well as in the PACO dataset, a widely used benchmark for object-attribute recognition. Code is available at: https://github.com/ethanbar11/grounding_ge_public.
EchoNarrator: Generating natural text explanations for ejection fraction predictions
Oct 31, 2024Ejection fraction (EF) of the left ventricle (LV) is considered as one of the most important measurements for diagnosing acute heart failure and can be estimated during cardiac ultrasound acquisition. While recent successes in deep learning research successfully estimate EF values, the proposed models often lack an explanation for the prediction. However, providing clear and intuitive explanations for clinical measurement predictions would increase the trust of cardiologists in these models. In this paper, we explore predicting EF measurements with Natural Language Explanation (NLE). We propose a model that in a single forward pass combines estimation of the LV contour over multiple frames, together with a set of modules and routines for computing various motion and shape attributes that are associated with ejection fraction. It then feeds the attributes into a large language model to generate text that helps to explain the network's outcome in a human-like manner. We provide experimental evaluation of our explanatory output, as well as EF prediction, and show that our model can provide EF comparable to state-of-the-art together with meaningful and accurate natural language explanation to the prediction. The project page can be found at https://github.com/guybenyosef/EchoNarrator .
Graph Convolutional Neural Networks for Automated Echocardiography View Recognition: A Holistic Approach
Mar 01, 2024To facilitate diagnosis on cardiac ultrasound (US), clinical practice has established several standard views of the heart, which serve as reference points for diagnostic measurements and define viewports from which images are acquired. Automatic view recognition involves grouping those images into classes of standard views. Although deep learning techniques have been successful in achieving this, they still struggle with fully verifying the suitability of an image for specific measurements due to factors like the correct location, pose, and potential occlusions of cardiac structures. Our approach goes beyond view classification and incorporates a 3D mesh reconstruction of the heart that enables several more downstream tasks, like segmentation and pose estimation. In this work, we explore learning 3D heart meshes via graph convolutions, using similar techniques to learn 3D meshes in natural images, such as human pose estimation. As the availability of fully annotated 3D images is limited, we generate synthetic US images from 3D meshes by training an adversarial denoising diffusion model. Experiments were conducted on synthetic and clinical cases for view recognition and structure detection. The approach yielded good performance on synthetic images and, despite being exclusively trained on synthetic data, it already showed potential when applied to clinical images. With this proof-of-concept, we aim to demonstrate the benefits of graphs to improve cardiac view recognition that can ultimately lead to better efficiency in cardiac diagnosis.
Towards Robust Cardiac Segmentation using Graph Convolutional Networks
Oct 02, 2023



Fully automatic cardiac segmentation can be a fast and reproducible method to extract clinical measurements from an echocardiography examination. The U-Net architecture is the current state-of-the-art deep learning architecture for medical segmentation and can segment cardiac structures in real-time with average errors comparable to inter-observer variability. However, this architecture still generates large outliers that are often anatomically incorrect. This work uses the concept of graph convolutional neural networks that predict the contour points of the structures of interest instead of labeling each pixel. We propose a graph architecture that uses two convolutional rings based on cardiac anatomy and show that this eliminates anatomical incorrect multi-structure segmentations on the publicly available CAMUS dataset. Additionally, this work contributes with an ablation study on the graph convolutional architecture and an evaluation of clinical measurements on the clinical HUNT4 dataset. Finally, we propose to use the inter-model agreement of the U-Net and the graph network as a predictor of both the input and segmentation quality. We show this predictor can detect out-of-distribution and unsuitable input images in real-time. Source code is available online: https://github.com/gillesvntnu/GCN_multistructure
Light-weight spatio-temporal graphs for segmentation and ejection fraction prediction in cardiac ultrasound
Jul 06, 2022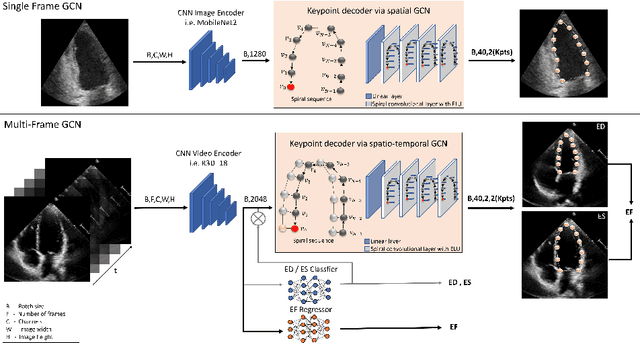
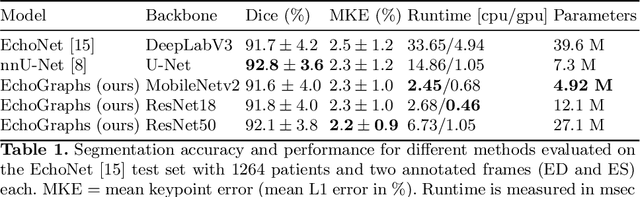
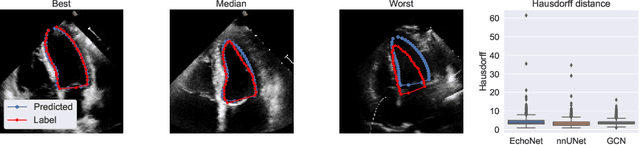
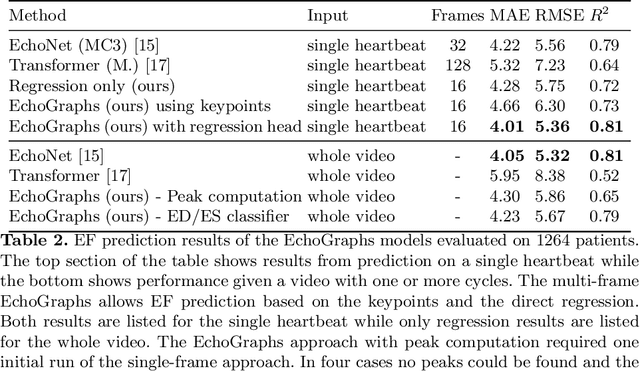
Accurate and consistent predictions of echocardiography parameters are important for cardiovascular diagnosis and treatment. In particular, segmentations of the left ventricle can be used to derive ventricular volume, ejection fraction (EF) and other relevant measurements. In this paper we propose a new automated method called EchoGraphs for predicting ejection fraction and segmenting the left ventricle by detecting anatomical keypoints. Models for direct coordinate regression based on Graph Convolutional Networks (GCNs) are used to detect the keypoints. GCNs can learn to represent the cardiac shape based on local appearance of each keypoint, as well as global spatial and temporal structures of all keypoints combined. We evaluate our EchoGraphs model on the EchoNet benchmark dataset. Compared to semantic segmentation, GCNs show accurate segmentation and improvements in robustness and inference runtime. EF is computed simultaneously to segmentations and our method also obtains state-of-the-art ejection fraction estimation. Source code is available online: https://github.com/guybenyosef/EchoGraphs.
A model for full local image interpretation
Oct 17, 2021



We describe a computational model of humans' ability to provide a detailed interpretation of components in a scene. Humans can identify in an image meaningful components almost everywhere, and identifying these components is an essential part of the visual process, and of understanding the surrounding scene and its potential meaning to the viewer. Detailed interpretation is beyond the scope of current models of visual recognition. Our model suggests that this is a fundamental limitation, related to the fact that existing models rely on feed-forward but limited top-down processing. In our model, a first recognition stage leads to the initial activation of class candidates, which is incomplete and with limited accuracy. This stage then triggers the application of class-specific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. We discuss implications of the model for visual interpretation by humans and by computer vision models.
* Published in the Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci), 2015
Parallel mesh reconstruction streams for pose estimation of interacting hands
Apr 25, 2021
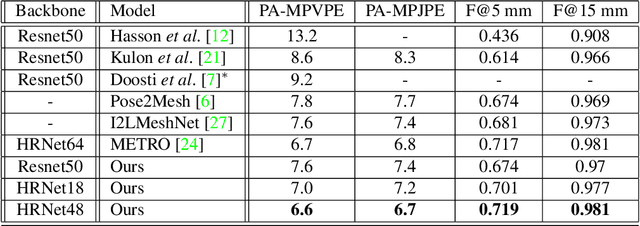
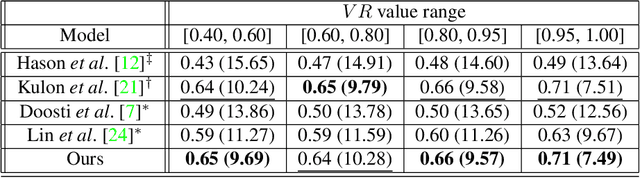
We present a new multi-stream 3D mesh reconstruction network (MSMR-Net) for hand pose estimation from a single RGB image. Our model consists of an image encoder followed by a mesh-convolution decoder composed of connected graph convolution layers. In contrast to previous models that form a single mesh decoding path, our decoder network incorporates multiple cross-resolution trajectories that are executed in parallel. Thus, global and local information are shared to form rich decoding representations at minor additional parameter cost compared to the single trajectory network. We demonstrate the effectiveness of our method in hand-hand and hand-object interaction scenarios at various levels of interaction. To evaluate the former scenario, we propose a method to generate RGB images of closely interacting hands. Moreoever, we suggest a metric to quantify the degree of interaction and show that close hand interactions are particularly challenging. Experimental results show that the MSMR-Net outperforms existing algorithms on the hand-object FreiHAND dataset as well as on our own hand-hand dataset.
What can human minimal videos tell us about dynamic recognition models?
Apr 19, 2021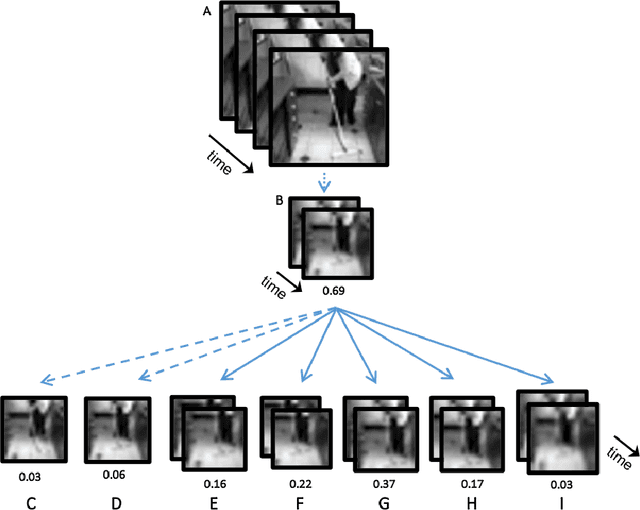

In human vision objects and their parts can be visually recognized from purely spatial or purely temporal information but the mechanisms integrating space and time are poorly understood. Here we show that human visual recognition of objects and actions can be achieved by efficiently combining spatial and motion cues in configurations where each source on its own is insufficient for recognition. This analysis is obtained by identifying minimal videos: these are short and tiny video clips in which objects, parts, and actions can be reliably recognized, but any reduction in either space or time makes them unrecognizable. State-of-the-art deep networks for dynamic visual recognition cannot replicate human behavior in these configurations. This gap between humans and machines points to critical mechanisms in human dynamic vision that are lacking in current models.
Minimal Images in Deep Neural Networks: Fragile Object Recognition in Natural Images
Feb 08, 2019


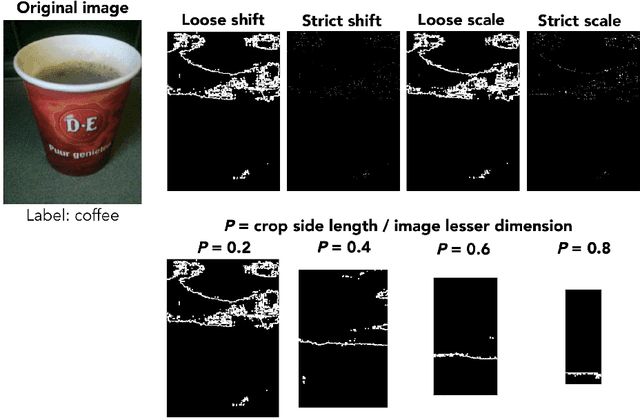
The human ability to recognize objects is impaired when the object is not shown in full. "Minimal images" are the smallest regions of an image that remain recognizable for humans. Ullman et al. 2016 show that a slight modification of the location and size of the visible region of the minimal image produces a sharp drop in human recognition accuracy. In this paper, we demonstrate that such drops in accuracy due to changes of the visible region are a common phenomenon between humans and existing state-of-the-art deep neural networks (DNNs), and are much more prominent in DNNs. We found many cases where DNNs classified one region correctly and the other incorrectly, though they only differed by one row or column of pixels, and were often bigger than the average human minimal image size. We show that this phenomenon is independent from previous works that have reported lack of invariance to minor modifications in object location in DNNs. Our results thus reveal a new failure mode of DNNs that also affects humans to a much lesser degree. They expose how fragile DNN recognition ability is for natural images even without adversarial patterns being introduced. Bringing the robustness of DNNs in natural images to the human level remains an open challenge for the community.
Complex Relations in a Deep Structured Prediction Model for Fine Image Segmentation
May 24, 2018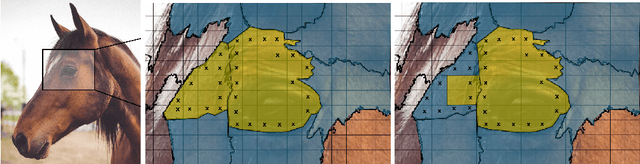
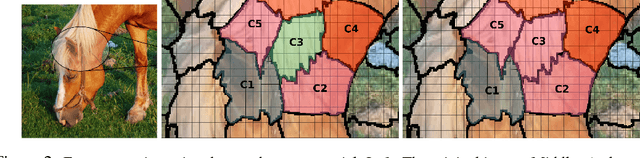
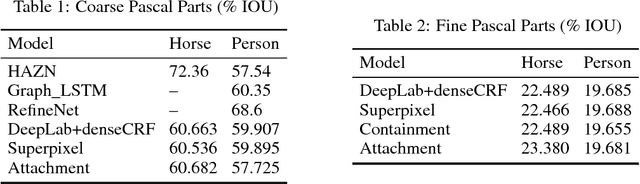

Many deep learning architectures for semantic segmentation involve a Fully Convolutional Neural Network (FCN) followed by a Conditional Random Field (CRF) to carry out inference over an image. These models typically involve unary potentials based on local appearance features computed by FCNs, and binary potentials based on the displacement between pixels. We show that while current methods succeed in segmenting whole objects, they perform poorly in situations involving a large number of object parts. We therefore suggest incorporating into the inference algorithm additional higher-order potentials inspired by the way humans identify and localize parts. We incorporate two relations that were shown to be useful to human object identification - containment and attachment - into the energy term of the CRF and evaluate their performance on the Pascal VOC Parts dataset. Our experimental results show that the segmentation of fine parts is positively affected by the addition of these two relations, and that the segmentation of fine parts can be further influenced by complex structural features.