 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Relations in a Deep Structured Prediction Model for Fine Image Segmentation
Paper and Code
May 24, 2018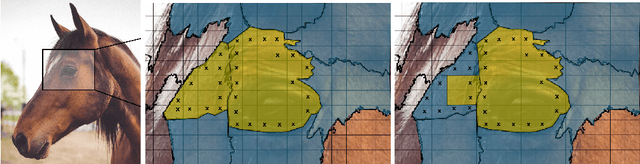
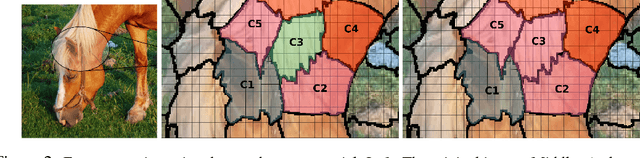
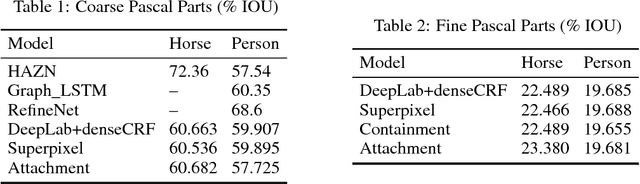

Many deep learning architectures for semantic segmentation involve a Fully Convolutional Neural Network (FCN) followed by a Conditional Random Field (CRF) to carry out inference over an image. These models typically involve unary potentials based on local appearance features computed by FCNs, and binary potentials based on the displacement between pixels. We show that while current methods succeed in segmenting whole objects, they perform poorly in situations involving a large number of object parts. We therefore suggest incorporating into the inference algorithm additional higher-order potentials inspired by the way humans identify and localize parts. We incorporate two relations that were shown to be useful to human object identification - containment and attachment - into the energy term of the CRF and evaluate their performance on the Pascal VOC Parts dataset. Our experimental results show that the segmentation of fine parts is positively affected by the addition of these two relations, and that the segmentation of fine parts can be further influenced by complex structural features.