 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Social Perception in Intuitive Physics
Mar 28, 2026People infer rich social information from others' actions. These inferences are often constrained by the physical world: what agents can do, what obstacles permit, and how the physical actions of agents causally change an environment and other agents' mental states and behavior. We propose that such rich social perception is more than visual pattern matching, but rather a reasoning process grounded in an integration of intuitive psychology with intuitive physics. To test this hypothesis, we introduced PHASE (PHysically grounded Abstract Social Events), a large dataset of procedurally generated animations, depicting physically simulated two-agent interactions on a 2D surface. Each animation follows the style of the Heider and Simmel movie, with systematic variation in environment geometry, object dynamics, agent capacities, goals, and relationships (friendly/adversarial/neutral). We then present a computational model, SIMPLE, a physics-grounded Bayesian inverse planning model that integrates planning, probabilistic planning, and physics simulation to infer agents' goals and relations from their trajectories. Our experimental results showed that SIMPLE achieved high accuracy and agreement with human judgments across diverse scenarios, while feedforward baseline models -- including strong vision-language models -- and physics-agnostic inverse planning failed to achieve human-level performance and did not align with human judgments. These results suggest that our model provides a computational account for how people understand physically grounded social scenes by inverting a generative model of physics and agents.
BrainBits: How Much of the Brain are Generative Reconstruction Methods Using?
Nov 05, 2024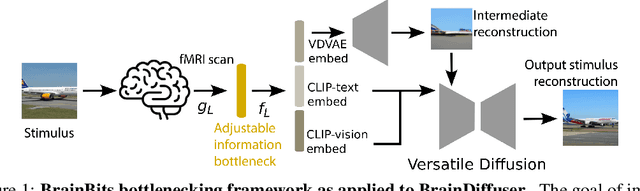

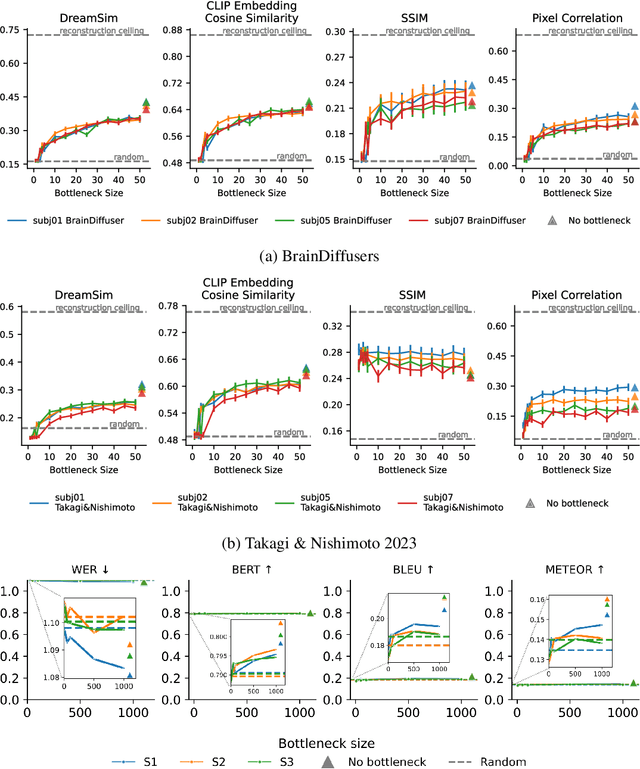
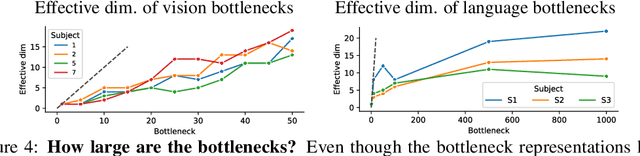
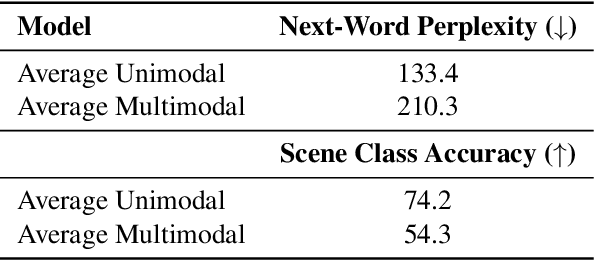
When evaluating stimuli reconstruction results it is tempting to assume that higher fidelity text and image generation is due to an improved understanding of the brain or more powerful signal extraction from neural recordings. However, in practice, new reconstruction methods could improve performance for at least three other reasons: learning more about the distribution of stimuli, becoming better at reconstructing text or images in general, or exploiting weaknesses in current image and/or text evaluation metrics. Here we disentangle how much of the reconstruction is due to these other factors vs. productively using the neural recordings. We introduce BrainBits, a method that uses a bottleneck to quantify the amount of signal extracted from neural recordings that is actually necessary to reproduce a method's reconstruction fidelity. We find that it takes surprisingly little information from the brain to produce reconstructions with high fidelity. In these cases, it is clear that the priors of the methods' generative models are so powerful that the outputs they produce extrapolate far beyond the neural signal they decode. Given that reconstructing stimuli can be improved independently by either improving signal extraction from the brain or by building more powerful generative models, improving the latter may fool us into thinking we are improving the former. We propose that methods should report a method-specific random baseline, a reconstruction ceiling, and a curve of performance as a function of bottleneck size, with the ultimate goal of using more of the neural recordings.
Training the Untrainable: Introducing Inductive Bias via Representational Alignment
Oct 26, 2024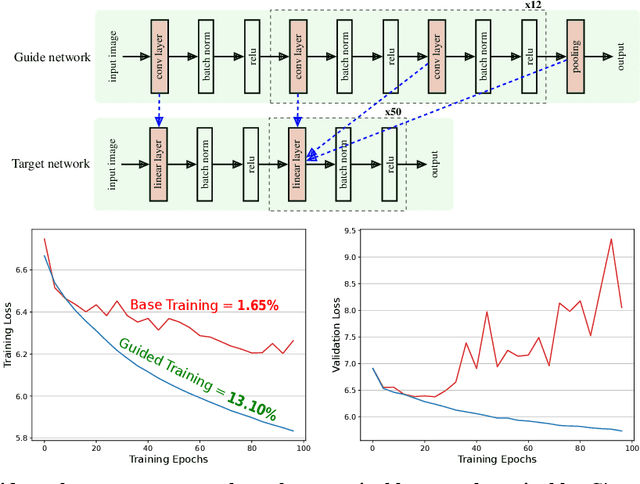
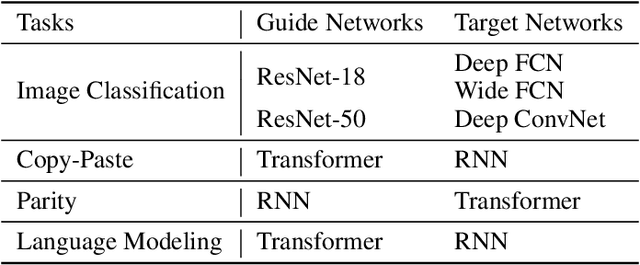
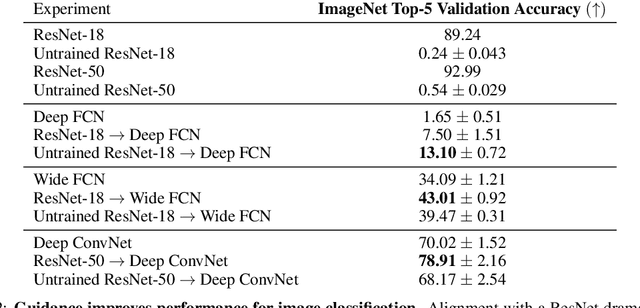
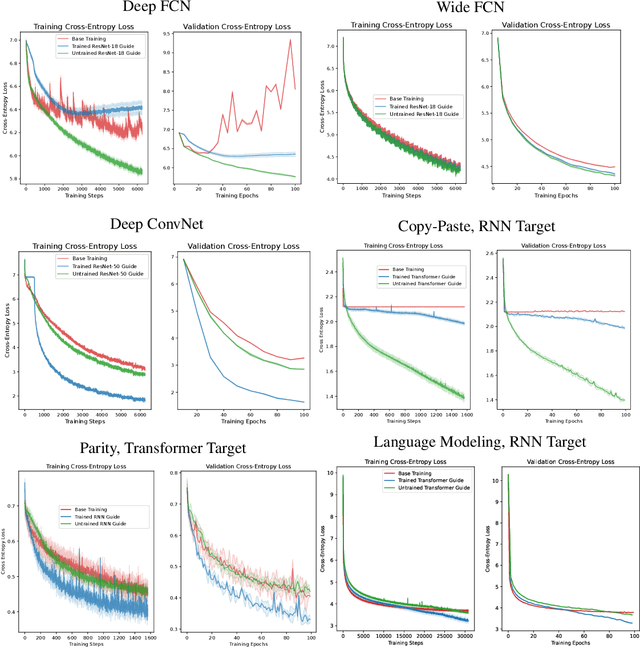
We demonstrate that architectures which traditionally are considered to be ill-suited for a task can be trained using inductive biases from another architecture. Networks are considered untrainable when they overfit, underfit, or converge to poor results even when tuning their hyperparameters. For example, plain fully connected networks overfit on object recognition while deep convolutional networks without residual connections underfit. The traditional answer is to change the architecture to impose some inductive bias, although what that bias is remains unknown. We introduce guidance, where a guide network guides a target network using a neural distance function. The target is optimized to perform well and to match its internal representations, layer-by-layer, to those of the guide; the guide is unchanged. If the guide is trained, this transfers over part of the architectural prior and knowledge of the guide to the target. If the guide is untrained, this transfers over only part of the architectural prior of the guide. In this manner, we can investigate what kinds of priors different architectures place on untrainable networks such as fully connected networks. We demonstrate that this method overcomes the immediate overfitting of fully connected networks on vision tasks, makes plain CNNs competitive to ResNets, closes much of the gap between plain vanilla RNNs and Transformers, and can even help Transformers learn tasks which RNNs can perform more easily. We also discover evidence that better initializations of fully connected networks likely exist to avoid overfitting. Our method provides a mathematical tool to investigate priors and architectures, and in the long term, may demystify the dark art of architecture creation, even perhaps turning architectures into a continuous optimizable parameter of the network.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Jun 20, 2024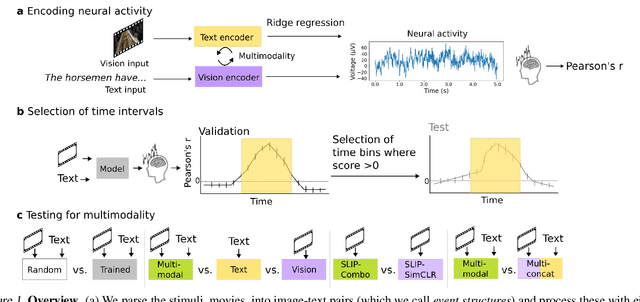

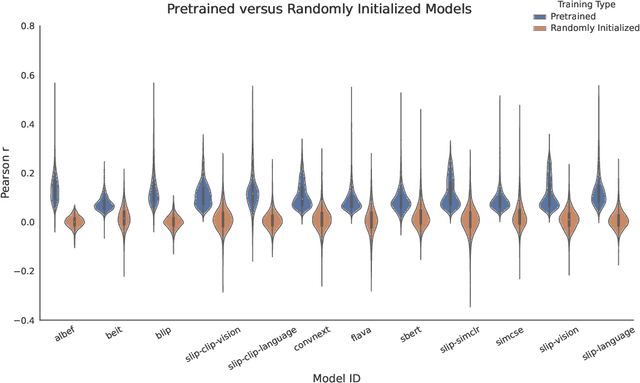
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Population Transformer: Learning Population-level Representations of Intracranial Activity
Jun 05, 2024



We present a self-supervised framework that learns population-level codes for intracranial neural recordings at scale, unlocking the benefits of representation learning for a key neuroscience recording modality. The Population Transformer (PopT) lowers the amount of data required for decoding experiments, while increasing accuracy, even on never-before-seen subjects and tasks. We address two key challenges in developing PopT: sparse electrode distribution and varying electrode location across patients. PopT stacks on top of pretrained representations and enhances downstream tasks by enabling learned aggregation of multiple spatially-sparse data channels. Beyond decoding, we interpret the pretrained PopT and fine-tuned models to show how it can be used to provide neuroscience insights learned from massive amounts of data. We release a pretrained PopT to enable off-the-shelf improvements in multi-channel intracranial data decoding and interpretability, and code is available at https://github.com/czlwang/PopulationTransformer.
SecureLLM: Using Compositionality to Build Provably Secure Language Models for Private, Sensitive, and Secret Data
May 16, 2024Traditional security mechanisms isolate resources from users who should not access them. We reflect the compositional nature of such security mechanisms back into the structure of LLMs to build a provably secure LLM; that we term SecureLLM. Other approaches to LLM safety attempt to protect against bad actors or bad outcomes, but can only do so to an extent making them inappropriate for sensitive data. SecureLLM blends access security with fine-tuning methods. Each data silo has associated with it a separate fine-tuning and a user has access only to the collection of fine-tunings that they have permission for. The model must then perform on compositional tasks at the intersection of those data silos with the combination of those individual fine-tunings. While applicable to any task like document QA or making API calls, in this work we concern ourselves with models that learn the layouts of new SQL databases to provide natural-language-to-SQL translation capabilities. Existing fine-tuning composition methods fail in this challenging environment, as they are not well-equipped for handling compositional tasks. Compositionality remains a challenge for LLMs. We contribute both a difficult new compositional natural-language-to-SQL translation task and a new perspective on LLM security that allows models to be deployed to secure environments today.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023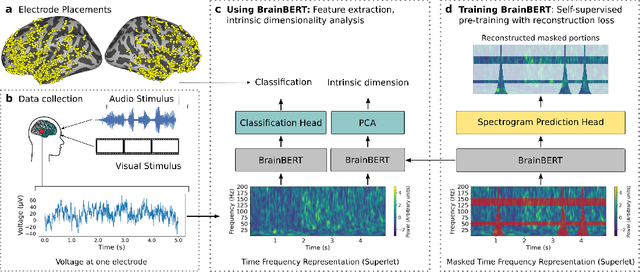
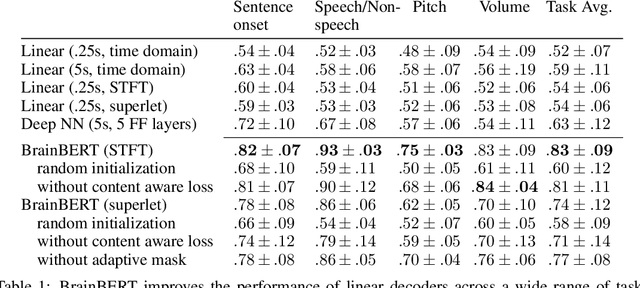
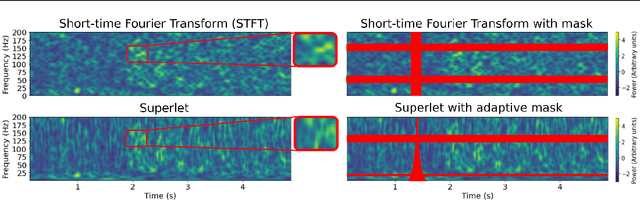
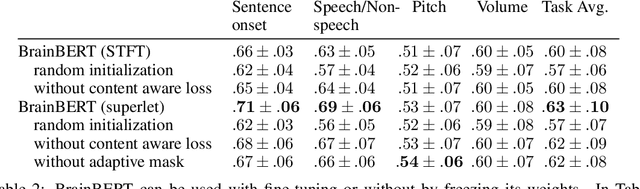
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Query The Agent: Improving sample efficiency through epistemic uncertainty estimation
Oct 05, 2022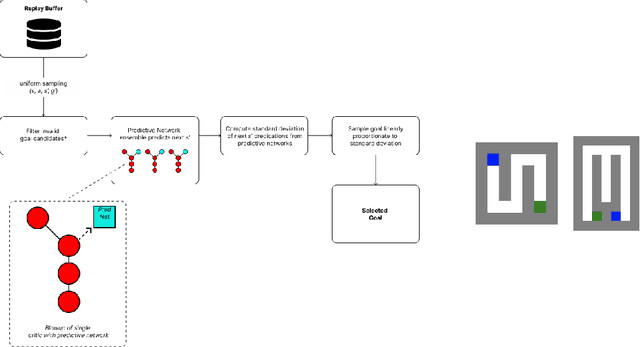
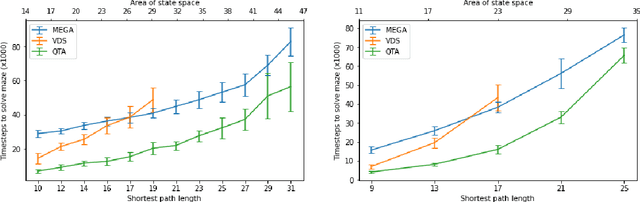
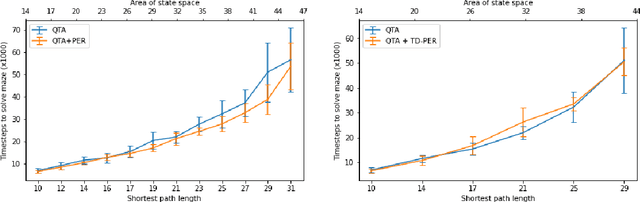
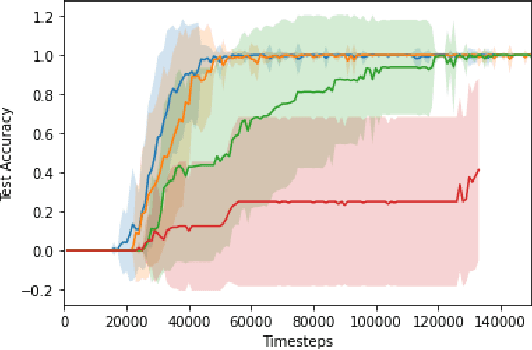
Curricula for goal-conditioned reinforcement learning agents typically rely on poor estimates of the agent's epistemic uncertainty or fail to consider the agents' epistemic uncertainty altogether, resulting in poor sample efficiency. We propose a novel algorithm, Query The Agent (QTA), which significantly improves sample efficiency by estimating the agent's epistemic uncertainty throughout the state space and setting goals in highly uncertain areas. Encouraging the agent to collect data in highly uncertain states allows the agent to improve its estimation of the value function rapidly. QTA utilizes a novel technique for estimating epistemic uncertainty, Predictive Uncertainty Networks (PUN), to allow QTA to assess the agent's uncertainty in all previously observed states. We demonstrate that QTA offers decisive sample efficiency improvements over preexisting methods.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022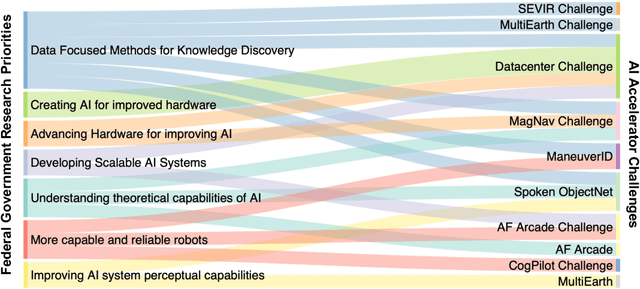

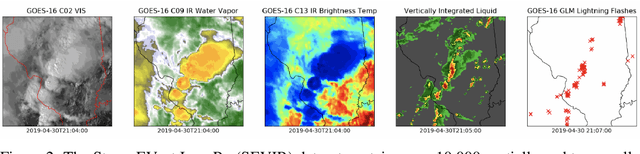
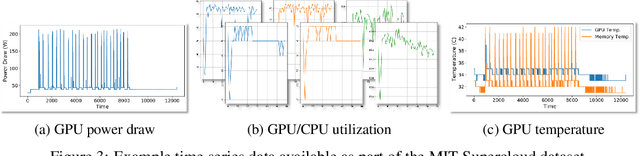
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
Incorporating Rich Social Interactions Into MDPs
Oct 22, 2021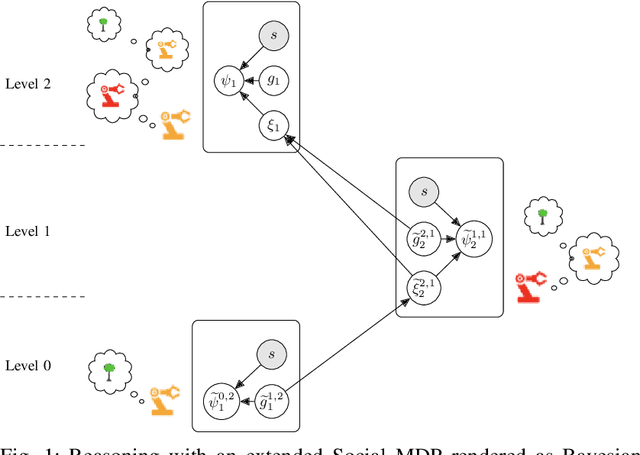

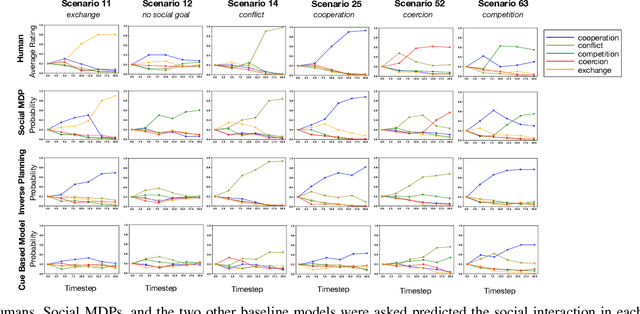

Much of what we do as humans is engage socially with other agents, a skill that robots must also eventually possess. We demonstrate that a rich theory of social interactions originating from microsociology and economics can be formalized by extending a nested MDP where agents reason about arbitrary functions of each other's hidden rewards. This extended Social MDP allows us to encode the five basic interactions that underlie microsociology: cooperation, conflict, coercion, competition, and exchange. The result is a robotic agent capable of executing social interactions zero-shot in new environments; like humans it can engage socially in novel ways even without a single example of that social interaction. Moreover, the judgments of these Social MDPs align closely with those of humans when considering which social interaction is taking place in an environment. This method both sheds light on the nature of social interactions, by providing concrete mathematical definitions, and brings rich social interactions into a mathematical framework that has proven to be natural for robotics, MDPs.