 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery The Agent: Improving sample efficiency through epistemic uncertainty estimation
Oct 05, 2022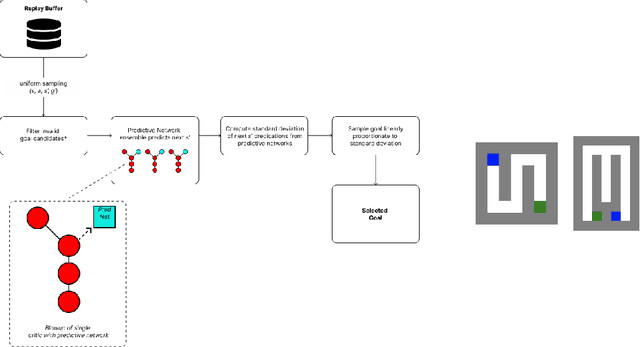
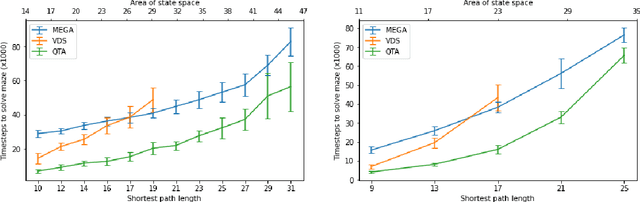
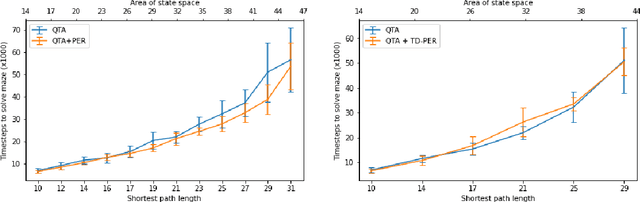
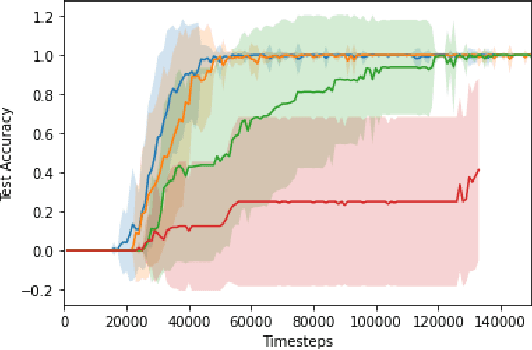
Curricula for goal-conditioned reinforcement learning agents typically rely on poor estimates of the agent's epistemic uncertainty or fail to consider the agents' epistemic uncertainty altogether, resulting in poor sample efficiency. We propose a novel algorithm, Query The Agent (QTA), which significantly improves sample efficiency by estimating the agent's epistemic uncertainty throughout the state space and setting goals in highly uncertain areas. Encouraging the agent to collect data in highly uncertain states allows the agent to improve its estimation of the value function rapidly. QTA utilizes a novel technique for estimating epistemic uncertainty, Predictive Uncertainty Networks (PUN), to allow QTA to assess the agent's uncertainty in all previously observed states. We demonstrate that QTA offers decisive sample efficiency improvements over preexisting methods.