 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
How Much Reasoning Do Retrieval-Augmented Models Add beyond LLMs? A Benchmarking Framework for Multi-Hop Inference over Hybrid Knowledge
Feb 10, 2026Large language models (LLMs) continue to struggle with knowledge-intensive questions that require up-to-date information and multi-hop reasoning. Augmenting LLMs with hybrid external knowledge, such as unstructured text and structured knowledge graphs, offers a promising alternative to costly continual pretraining. As such, reliable evaluation of their retrieval and reasoning capabilities becomes critical. However, many existing benchmarks increasingly overlap with LLM pretraining data, which means answers or supporting knowledge may already be encoded in model parameters, making it difficult to distinguish genuine retrieval and reasoning from parametric recall. We introduce HybridRAG-Bench, a framework for constructing benchmarks to evaluate retrieval-intensive, multi-hop reasoning over hybrid knowledge. HybridRAG-Bench automatically couples unstructured text and structured knowledge graph representations derived from recent scientific literature on arXiv, and generates knowledge-intensive question-answer pairs grounded in explicit reasoning paths. The framework supports flexible domain and time-frame selection, enabling contamination-aware and customizable evaluation as models and knowledge evolve. Experiments across three domains (artificial intelligence, governance and policy, and bioinformatics) demonstrate that HybridRAG-Bench rewards genuine retrieval and reasoning rather than parametric recall, offering a principled testbed for evaluating hybrid knowledge-augmented reasoning systems. We release our code and data at github.com/junhongmit/HybridRAG-Bench.
BOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization
Dec 29, 2025Large language models (LLMs) have shown strong reasoning and coding capabilities, yet they struggle to generalize to real-world software engineering (SWE) problems that are long-horizon and out of distribution. Existing systems often rely on a single agent to handle the entire workflow-interpreting issues, navigating large codebases, and implementing fixes-within one reasoning chain. Such monolithic designs force the model to retain irrelevant context, leading to spurious correlations and poor generalization. Motivated by how human engineers decompose complex problems, we propose structuring SWE agents as orchestrators coordinating specialized sub-agents for sub-tasks such as localization, editing, and validation. The challenge lies in discovering effective hierarchies automatically: as the number of sub-agents grows, the search space becomes combinatorial, and it is difficult to attribute credit to individual sub-agents within a team. We address these challenges by formulating hierarchy discovery as a multi-armed bandit (MAB) problem, where each arm represents a candidate sub-agent and the reward measures its helpfulness when collaborating with others. This framework, termed Bandit Optimization for Agent Design (BOAD), enables efficient exploration of sub-agent designs under limited evaluation budgets. On SWE-bench-Verified, BOAD outperforms single-agent and manually designed multi-agent systems. On SWE-bench-Live, featuring more recent and out-of-distribution issues, our 36B system ranks second on the leaderboard at the time of evaluation, surpassing larger models such as GPT-4 and Claude. These results demonstrate that automatically discovered hierarchical multi-agent systems significantly improve generalization on challenging long-horizon SWE tasks. Code is available at https://github.com/iamxjy/BOAD-SWE-Agent.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025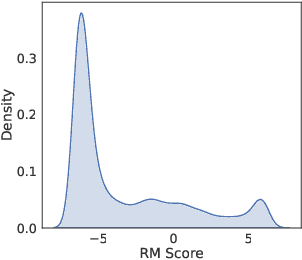
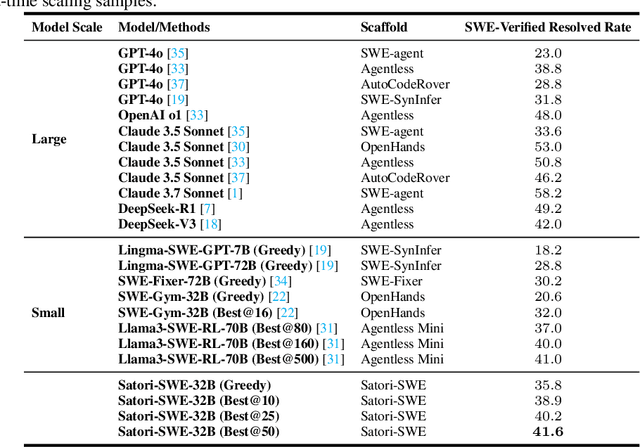

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
LInK: Learning Joint Representations of Design and Performance Spaces through Contrastive Learning for Mechanism Synthesis
May 31, 2024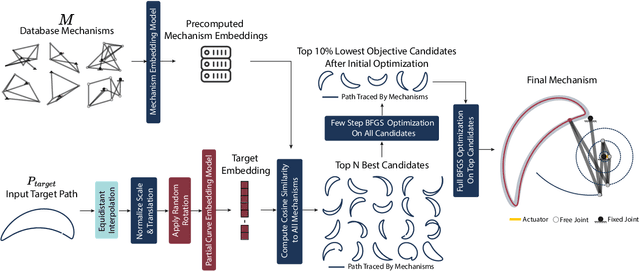

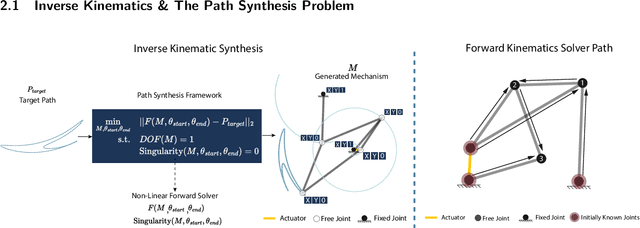
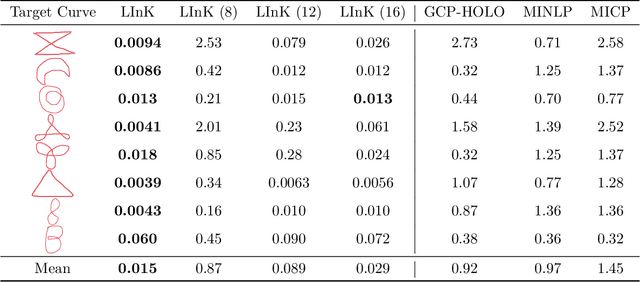
In this paper, we introduce LInK, a novel framework that integrates contrastive learning of performance and design space with optimization techniques for solving complex inverse problems in engineering design with discrete and continuous variables. We focus on the path synthesis problem for planar linkage mechanisms. By leveraging a multi-modal and transformation-invariant contrastive learning framework, LInK learns a joint representation that captures complex physics and design representations of mechanisms, enabling rapid retrieval from a vast dataset of over 10 million mechanisms. This approach improves precision through the warm start of a hierarchical unconstrained nonlinear optimization algorithm, combining the robustness of traditional optimization with the speed and adaptability of modern deep learning methods. Our results on an existing benchmark demonstrate that LInK outperforms existing methods with 28 times less error compared to a state-of-the-art approach while taking 20 times less time on an existing benchmark. Moreover, we introduce a significantly more challenging benchmark, named LINK-ABC, which involves synthesizing linkages that trace the trajectories of English capital alphabets - an inverse design benchmark task that existing methods struggle with due to large non-linearities and tiny feasible space. Our results demonstrate that LInK not only advances the field of mechanism design but also broadens the applicability of contrastive learning and optimization to other areas of engineering.
Learning from Invalid Data: On Constraint Satisfaction in Generative Models
Jun 27, 2023Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. This is particularly problematic when the generated data must satisfy constraints, for example, to meet product specifications in engineering design or to adhere to the laws of physics in a natural scene. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like GANs and DDPMs that we augment to train with invalid data vastly outperform their standard counterparts which solely train on valid data points. For example, our training procedure generates up to 98 % fewer invalid samples on 2D densities, improves connectivity and stability four-fold on a stacking block problem, and improves constraint satisfaction by 15 % on a structural topology optimization benchmark in engineering design. We also analyze how the quality of the invalid data affects the learning procedure and the generalization properties of models. Finally, we demonstrate significant improvements in sample efficiency, showing that a tenfold increase in valid samples leads to a negligible difference in constraint satisfaction, while less than 10 % invalid samples lead to a tenfold improvement. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023



Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
3D Neural Embedding Likelihood for Robust Sim-to-Real Transfer in Inverse Graphics
Feb 07, 2023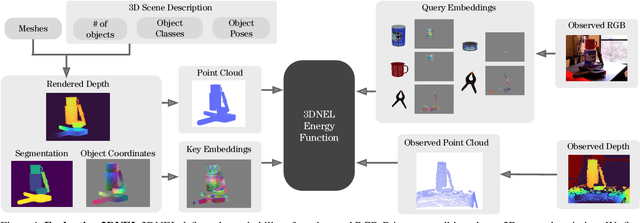

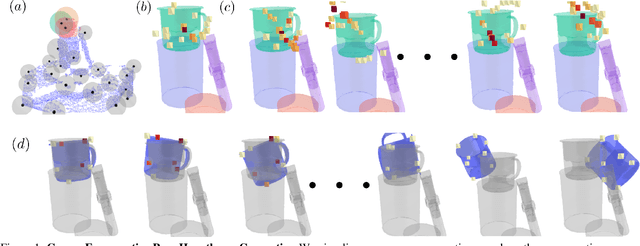
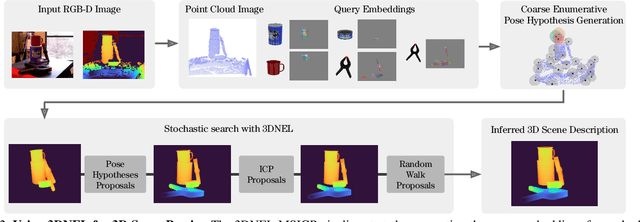
A central challenge in 3D scene perception via inverse graphics is robustly modeling the gap between 3D graphics and real-world data. We propose a novel 3D Neural Embedding Likelihood (3DNEL) over RGB-D images to address this gap. 3DNEL uses neural embeddings to predict 2D-3D correspondences from RGB and combines this with depth in a principled manner. 3DNEL is trained entirely from synthetic images and generalizes to real-world data. To showcase this capability, we develop a multi-stage inverse graphics pipeline that uses 3DNEL for 6D object pose estimation from real RGB-D images. Our method outperforms the previous state-of-the-art in sim-to-real pose estimation on the YCB-Video dataset, and improves robustness, with significantly fewer large-error predictions. Unlike existing bottom-up, discriminative approaches that are specialized for pose estimation, 3DNEL adopts a probabilistic generative formulation that jointly models multi-object scenes. This generative formulation enables easy extension of 3DNEL to additional tasks like object and camera tracking from video, using principled inference in the same probabilistic model without task specific retraining.
LINKS: A dataset of a hundred million planar linkage mechanisms for data-driven kinematic design
Aug 30, 2022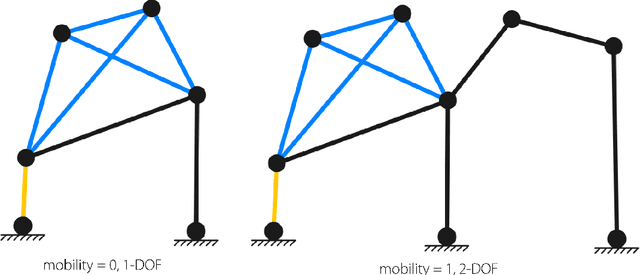

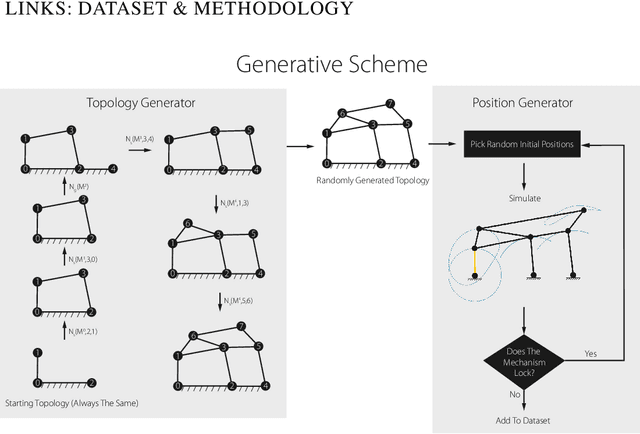
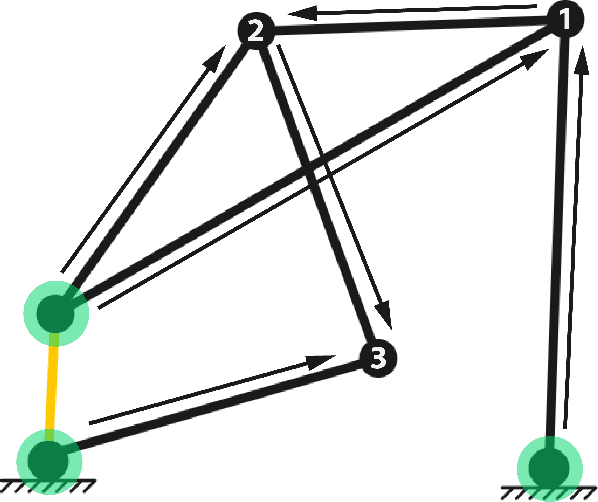
In this paper, we introduce LINKS, a dataset of 100 million one degree of freedom planar linkage mechanisms and 1.1 billion coupler curves, which is more than 1000 times larger than any existing database of planar mechanisms and is not limited to specific kinds of mechanisms such as four-bars, six-bars, \etc which are typically what most databases include. LINKS is made up of various components including 100 million mechanisms, the simulation data for each mechanism, normalized paths generated by each mechanism, a curated set of paths, the code used to generate the data and simulate mechanisms, and a live web demo for interactive design of linkage mechanisms. The curated paths are provided as a measure for removing biases in the paths generated by mechanisms that enable a more even design space representation. In this paper, we discuss the details of how we can generate such a large dataset and how we can overcome major issues with such scales. To be able to generate such a large dataset we introduce a new operator to generate 1-DOF mechanism topologies, furthermore, we take many steps to speed up slow simulations of mechanisms by vectorizing our simulations and parallelizing our simulator on a large number of threads, which leads to a simulation 800 times faster than the simple simulation algorithm. This is necessary given on average, 1 out of 500 candidates that are generated are valid~(and all must be simulated to determine their validity), which means billions of simulations must be performed for the generation of this dataset. Then we demonstrate the depth of our dataset through a bi-directional chamfer distance-based shape retrieval study where we show how our dataset can be used directly to find mechanisms that can trace paths very close to desired target paths.
Solving the Baby Intuitions Benchmark with a Hierarchically Bayesian Theory of Mind
Aug 04, 2022


To facilitate the development of new models to bridge the gap between machine and human social intelligence, the recently proposed Baby Intuitions Benchmark (arXiv:2102.11938) provides a suite of tasks designed to evaluate commonsense reasoning about agents' goals and actions that even young infants exhibit. Here we present a principled Bayesian solution to this benchmark, based on a hierarchically Bayesian Theory of Mind (HBToM). By including hierarchical priors on agent goals and dispositions, inference over our HBToM model enables few-shot learning of the efficiency and preferences of an agent, which can then be used in commonsense plausibility judgements about subsequent agent behavior. This approach achieves near-perfect accuracy on most benchmark tasks, outperforming deep learning and imitation learning baselines while producing interpretable human-like inferences, demonstrating the advantages of structured Bayesian models of human social cognition.