 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Domain Randomization for Learning and Sequencing Robotic Skills
Feb 03, 2025



Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies trained in simulation. By randomizing environment properties during training, the learned policy can become robust to uncertainties along the randomized dimensions. While the environment distribution is typically specified by hand, in this paper we investigate automatically discovering a sampling distribution via entropy-regularized reward maximization of a normalizing-flow-based neural sampling distribution. We show that this architecture is more flexible and provides greater robustness than existing approaches that learn simpler, parameterized sampling distributions, as demonstrated in six simulated and one real-world robotics domain. Lastly, we explore how these learned sampling distributions, combined with a privileged value function, can be used for out-of-distribution detection in an uncertainty-aware multi-step manipulation planner.
Partially Observable Task and Motion Planning with Uncertainty and Risk Awareness
Mar 15, 2024

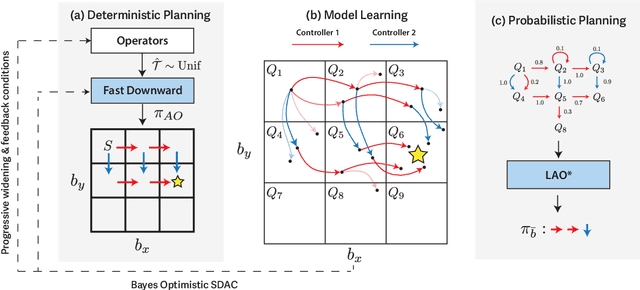

Integrated task and motion planning (TAMP) has proven to be a valuable approach to generalizable long-horizon robotic manipulation and navigation problems. However, the typical TAMP problem formulation assumes full observability and deterministic action effects. These assumptions limit the ability of the planner to gather information and make decisions that are risk-aware. We propose a strategy for TAMP with Uncertainty and Risk Awareness (TAMPURA) that is capable of efficiently solving long-horizon planning problems with initial-state and action outcome uncertainty, including problems that require information gathering and avoiding undesirable and irreversible outcomes. Our planner reasons under uncertainty at both the abstract task level and continuous controller level. Given a set of closed-loop goal-conditioned controllers operating in the primitive action space and a description of their preconditions and potential capabilities, we learn a high-level abstraction that can be solved efficiently and then refined to continuous actions for execution. We demonstrate our approach on several robotics problems where uncertainty is a crucial factor and show that reasoning under uncertainty in these problems outperforms previously proposed determinized planning, direct search, and reinforcement learning strategies. Lastly, we demonstrate our planner on two real-world robotics problems using recent advancements in probabilistic perception.
Bayes3D: fast learning and inference in structured generative models of 3D objects and scenes
Dec 14, 2023



Robots cannot yet match humans' ability to rapidly learn the shapes of novel 3D objects and recognize them robustly despite clutter and occlusion. We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. Quantitative experiments show that Bayes3D can learn 3D models of novel objects from just a handful of views, recognizing them more robustly and with orders of magnitude less training data than neural baselines, and tracking 3D objects faster than real time on a single GPU. We also demonstrate that Bayes3D learns complex 3D object models and accurately infers 3D scene composition when used on a Panda robot in a tabletop scenario.
3D Neural Embedding Likelihood for Robust Sim-to-Real Transfer in Inverse Graphics
Feb 07, 2023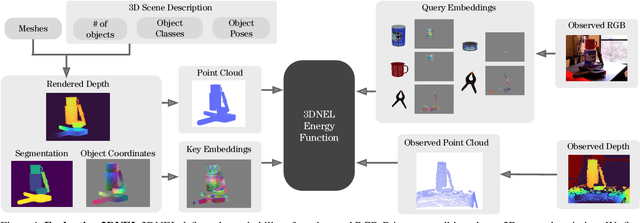

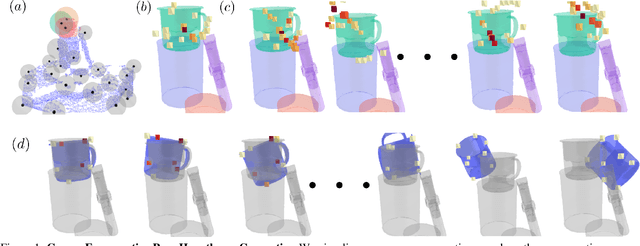
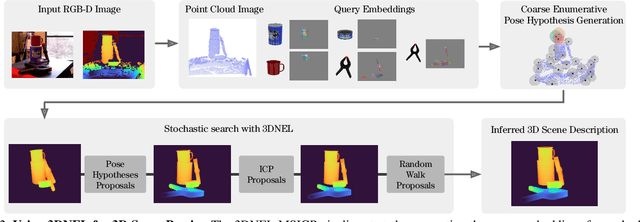
A central challenge in 3D scene perception via inverse graphics is robustly modeling the gap between 3D graphics and real-world data. We propose a novel 3D Neural Embedding Likelihood (3DNEL) over RGB-D images to address this gap. 3DNEL uses neural embeddings to predict 2D-3D correspondences from RGB and combines this with depth in a principled manner. 3DNEL is trained entirely from synthetic images and generalizes to real-world data. To showcase this capability, we develop a multi-stage inverse graphics pipeline that uses 3DNEL for 6D object pose estimation from real RGB-D images. Our method outperforms the previous state-of-the-art in sim-to-real pose estimation on the YCB-Video dataset, and improves robustness, with significantly fewer large-error predictions. Unlike existing bottom-up, discriminative approaches that are specialized for pose estimation, 3DNEL adopts a probabilistic generative formulation that jointly models multi-object scenes. This generative formulation enables easy extension of 3DNEL to additional tasks like object and camera tracking from video, using principled inference in the same probabilistic model without task specific retraining.
Solving the Baby Intuitions Benchmark with a Hierarchically Bayesian Theory of Mind
Aug 04, 2022


To facilitate the development of new models to bridge the gap between machine and human social intelligence, the recently proposed Baby Intuitions Benchmark (arXiv:2102.11938) provides a suite of tasks designed to evaluate commonsense reasoning about agents' goals and actions that even young infants exhibit. Here we present a principled Bayesian solution to this benchmark, based on a hierarchically Bayesian Theory of Mind (HBToM). By including hierarchical priors on agent goals and dispositions, inference over our HBToM model enables few-shot learning of the efficiency and preferences of an agent, which can then be used in commonsense plausibility judgements about subsequent agent behavior. This approach achieves near-perfect accuracy on most benchmark tasks, outperforming deep learning and imitation learning baselines while producing interpretable human-like inferences, demonstrating the advantages of structured Bayesian models of human social cognition.
DURableVS: Data-efficient Unsupervised Recalibrating Visual Servoing via online learning in a structured generative model
Feb 08, 2022
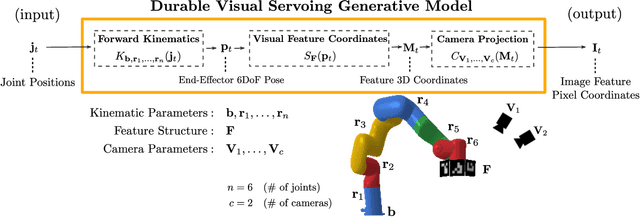
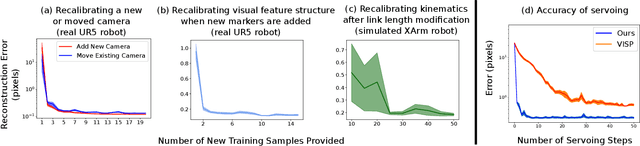

Visual servoing enables robotic systems to perform accurate closed-loop control, which is required in many applications. However, existing methods either require precise calibration of the robot kinematic model and cameras or use neural architectures that require large amounts of data to train. In this work, we present a method for unsupervised learning of visual servoing that does not require any prior calibration and is extremely data-efficient. Our key insight is that visual servoing does not depend on identifying the veridical kinematic and camera parameters, but instead only on an accurate generative model of image feature observations from the joint positions of the robot. We demonstrate that with our model architecture and learning algorithm, we can consistently learn accurate models from less than 50 training samples (which amounts to less than 1 min of unsupervised data collection), and that such data-efficient learning is not possible with standard neural architectures. Further, we show that by using the generative model in the loop and learning online, we can enable a robotic system to recover from calibration errors and to detect and quickly adapt to possibly unexpected changes in the robot-camera system (e.g. bumped camera, new objects).
3DP3: 3D Scene Perception via Probabilistic Programming
Oct 30, 2021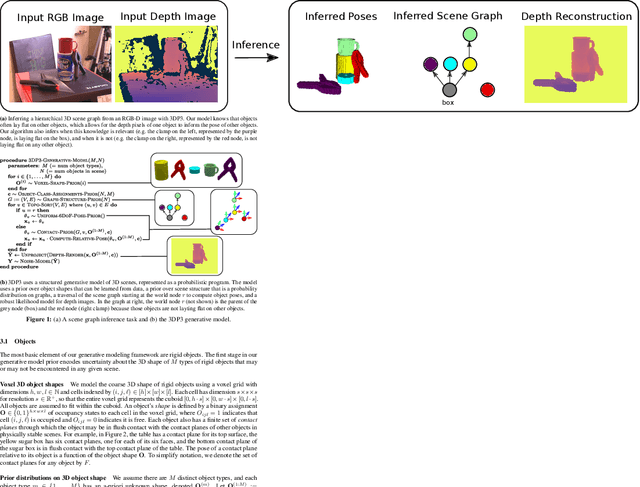
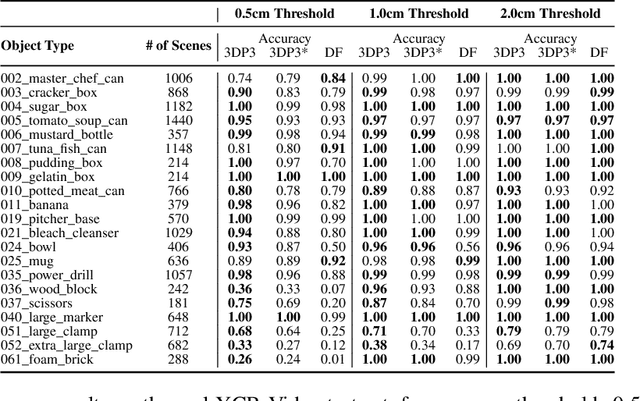
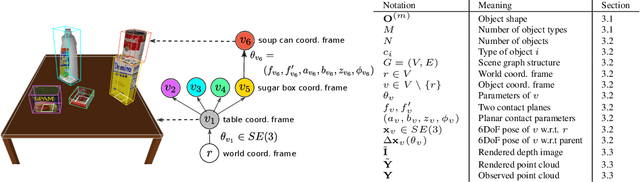
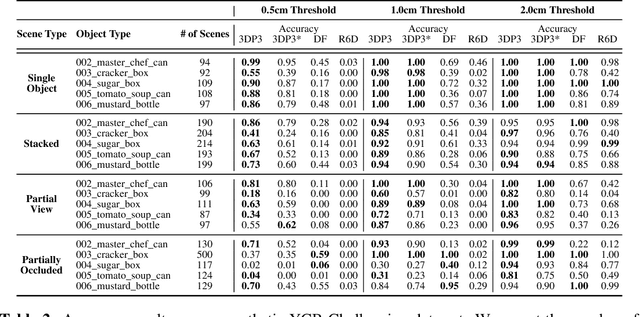
We present 3DP3, a framework for inverse graphics that uses inference in a structured generative model of objects, scenes, and images. 3DP3 uses (i) voxel models to represent the 3D shape of objects, (ii) hierarchical scene graphs to decompose scenes into objects and the contacts between them, and (iii) depth image likelihoods based on real-time graphics. Given an observed RGB-D image, 3DP3's inference algorithm infers the underlying latent 3D scene, including the object poses and a parsimonious joint parametrization of these poses, using fast bottom-up pose proposals, novel involutive MCMC updates of the scene graph structure, and, optionally, neural object detectors and pose estimators. We show that 3DP3 enables scene understanding that is aware of 3D shape, occlusion, and contact structure. Our results demonstrate that 3DP3 is more accurate at 6DoF object pose estimation from real images than deep learning baselines and shows better generalization to challenging scenes with novel viewpoints, contact, and partial observability.
Query Training: Learning and inference for directed and undirected graphical models
Jun 18, 2020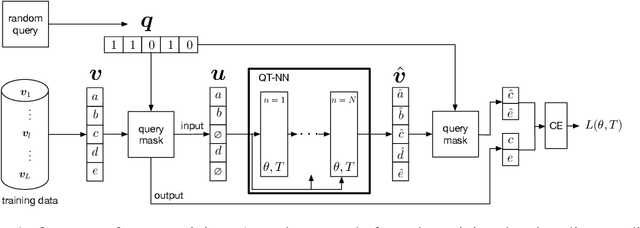
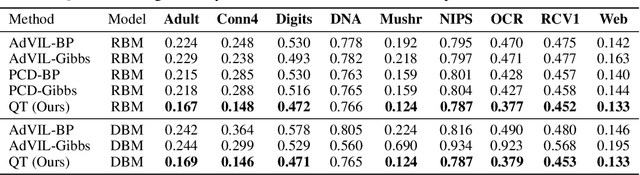
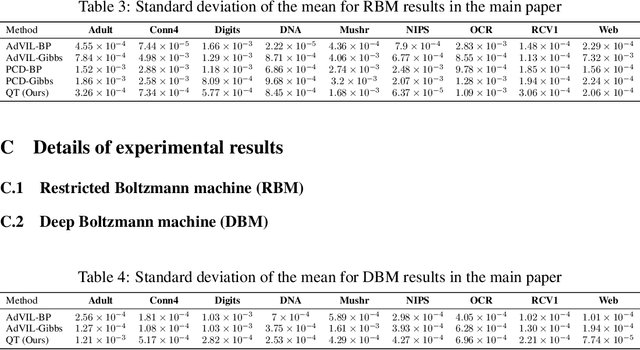
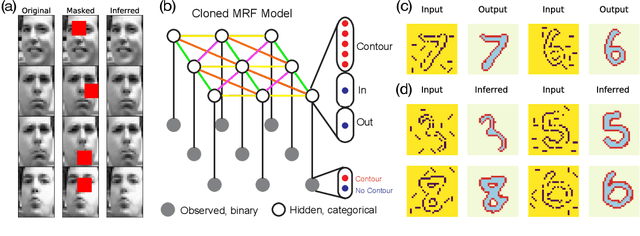
Probabilistic graphical models (PGMs) provide a compact representation of knowledge that can be queried in a flexible way: after learning the parameters of a graphical model, new probabilistic queries can be answered at test time without retraining. However, learning undirected graphical models is notoriously hard due to the intractability of the partition function. For directed models, a popular approach is to use variational autoencoders, but there is no systematic way to choose the encoder architecture given the PGM, and the encoder only amortizes inference for a single probabilistic query (i.e., new queries require separate training). We introduce Query Training (QT), a systematic method to turn any PGM structure (directed or not, with or without hidden variables) into a trainable inference network. This single network can approximate any inference query. We demonstrate experimentally that QT can be used to learn a challenging 8-connected grid Markov random field with hidden variables and that it consistently outperforms the state-of-the-art AdVIL when tested on three undirected models across multiple datasets.
From proprioception to long-horizon planning in novel environments: A hierarchical RL model
Jun 11, 2020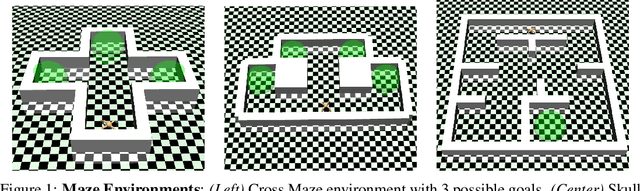


For an intelligent agent to flexibly and efficiently operate in complex environments, they must be able to reason at multiple levels of temporal, spatial, and conceptual abstraction. At the lower levels, the agent must interpret their proprioceptive inputs and control their muscles, and at the higher levels, the agent must select goals and plan how they will achieve those goals. It is clear that each of these types of reasoning is amenable to different types of representations, algorithms, and inputs. In this work, we introduce a simple, three-level hierarchical architecture that reflects these distinctions. The low-level controller operates on the continuous proprioceptive inputs, using model-free learning to acquire useful behaviors. These in turn induce a set of mid-level dynamics, which are learned by the mid-level controller and used for model-predictive control, to select a behavior to activate at each timestep. The high-level controller leverages a discrete, graph representation for goal selection and path planning to specify targets for the mid-level controller. We apply our method to a series of navigation tasks in the Mujoco Ant environment, consistently demonstrating significant improvements in sample-efficiency compared to prior model-free, model-based, and hierarchical RL methods. Finally, as an illustrative example of the advantages of our architecture, we apply our method to a complex maze environment that requires efficient exploration and long-horizon planning.
Learning a generative model for robot control using visual feedback
Mar 10, 2020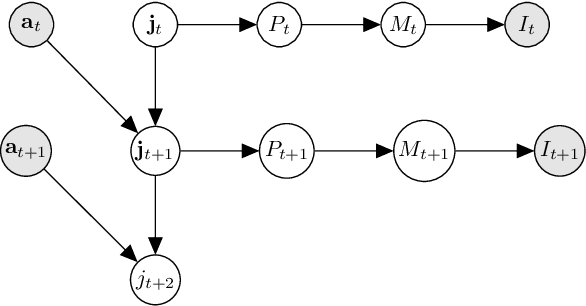

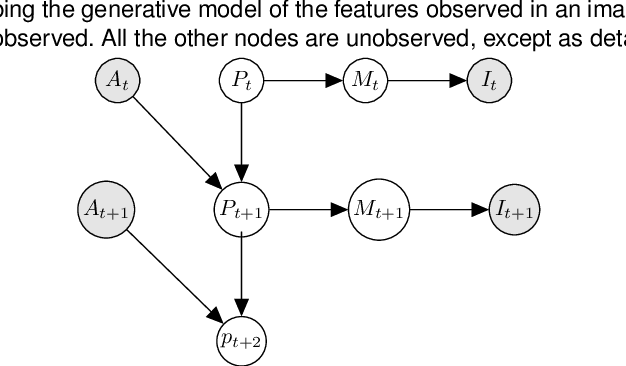

We introduce a novel formulation for incorporating visual feedback in controlling robots. We define a generative model from actions to image observations of features on the end-effector. Inference in the model allows us to infer the robot state corresponding to target locations of the features. This, in turn, guides motion of the robot and allows for matching the target locations of the features in significantly fewer steps than state-of-the-art visual servoing methods. The training procedure for our model enables effective learning of the kinematics, feature structure, and camera parameters, simultaneously. This can be done with no prior information about the robot, structure, and cameras that observe it. Learning is done sample-efficiently and shows strong generalization to test data. Since our formulation is modular, we can modify components of our setup, like cameras and objects, and relearn them quickly online. Our method can handle noise in the observed state and noise in the controllers that we interact with. We demonstrate the effectiveness of our method by executing grasping and tight-fit insertions on robots with inaccurate controllers.