 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a generative model for robot control using visual feedback
Paper and Code
Mar 10, 2020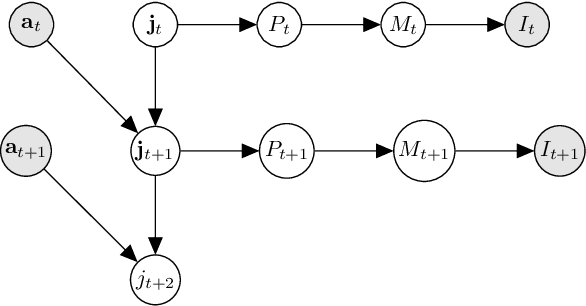

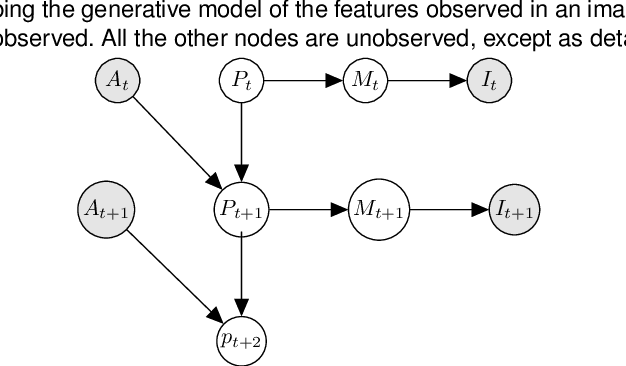

We introduce a novel formulation for incorporating visual feedback in controlling robots. We define a generative model from actions to image observations of features on the end-effector. Inference in the model allows us to infer the robot state corresponding to target locations of the features. This, in turn, guides motion of the robot and allows for matching the target locations of the features in significantly fewer steps than state-of-the-art visual servoing methods. The training procedure for our model enables effective learning of the kinematics, feature structure, and camera parameters, simultaneously. This can be done with no prior information about the robot, structure, and cameras that observe it. Learning is done sample-efficiently and shows strong generalization to test data. Since our formulation is modular, we can modify components of our setup, like cameras and objects, and relearn them quickly online. Our method can handle noise in the observed state and noise in the controllers that we interact with. We demonstrate the effectiveness of our method by executing grasping and tight-fit insertions on robots with inaccurate controllers.