 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCalEval: Benchmarking Vision-Language Models for Quantum Calibration Plot Understanding
Apr 28, 2026Quantum computing calibration depends on interpreting experimental data, and calibration plots provide the most universal human-readable representation for this task, yet no systematic evaluation exists of how well vision-language models (VLMs) interpret them. We introduce QCalEval, the first VLM benchmark for quantum calibration plots: 243 samples across 87 scenario types from 22 experiment families, spanning superconducting qubits and neutral atoms, evaluated on six question types in both zero-shot and in-context learning settings. The best general-purpose zero-shot model reaches a mean score of 72.3, and many open-weight models degrade under multi-image in-context learning, whereas frontier closed models improve substantially. A supervised fine-tuning ablation at the 9-billion-parameter scale shows that SFT improves zero-shot performance but cannot close the multimodal in-context learning gap. As a reference case study, we release NVIDIA Ising Calibration 1, an open-weight model based on Qwen3.5-35B-A3B that reaches 74.7 zero-shot average score.
Hallucination Reduction in Long Input Text Summarization
Sep 28, 2023
Hallucination in text summarization refers to the phenomenon where the model generates information that is not supported by the input source document. Hallucination poses significant obstacles to the accuracy and reliability of the generated summaries. In this paper, we aim to reduce hallucinated outputs or hallucinations in summaries of long-form text documents. We have used the PubMed dataset, which contains long scientific research documents and their abstracts. We have incorporated the techniques of data filtering and joint entity and summary generation (JAENS) in the fine-tuning of the Longformer Encoder-Decoder (LED) model to minimize hallucinations and thereby improve the quality of the generated summary. We have used the following metrics to measure factual consistency at the entity level: precision-source, and F1-target. Our experiments show that the fine-tuned LED model performs well in generating the paper abstract. Data filtering techniques based on some preprocessing steps reduce entity-level hallucinations in the generated summaries in terms of some of the factual consistency metrics.
DURableVS: Data-efficient Unsupervised Recalibrating Visual Servoing via online learning in a structured generative model
Feb 08, 2022
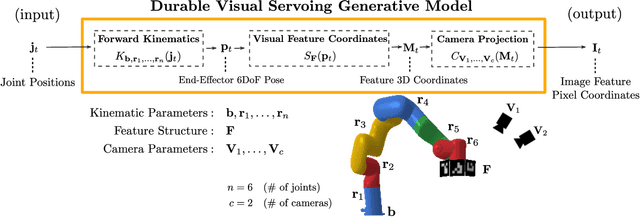
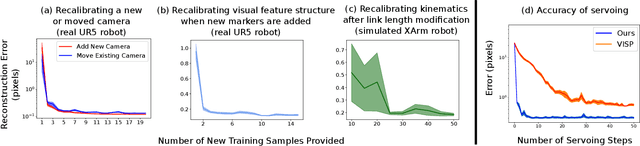

Visual servoing enables robotic systems to perform accurate closed-loop control, which is required in many applications. However, existing methods either require precise calibration of the robot kinematic model and cameras or use neural architectures that require large amounts of data to train. In this work, we present a method for unsupervised learning of visual servoing that does not require any prior calibration and is extremely data-efficient. Our key insight is that visual servoing does not depend on identifying the veridical kinematic and camera parameters, but instead only on an accurate generative model of image feature observations from the joint positions of the robot. We demonstrate that with our model architecture and learning algorithm, we can consistently learn accurate models from less than 50 training samples (which amounts to less than 1 min of unsupervised data collection), and that such data-efficient learning is not possible with standard neural architectures. Further, we show that by using the generative model in the loop and learning online, we can enable a robotic system to recover from calibration errors and to detect and quickly adapt to possibly unexpected changes in the robot-camera system (e.g. bumped camera, new objects).
Learning a generative model for robot control using visual feedback
Mar 10, 2020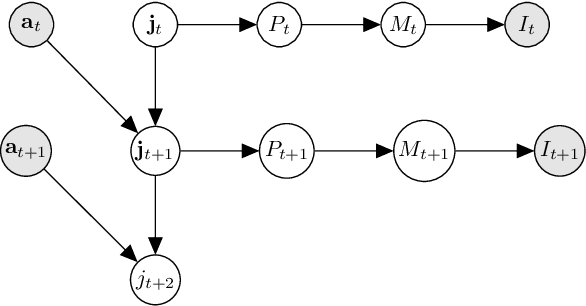

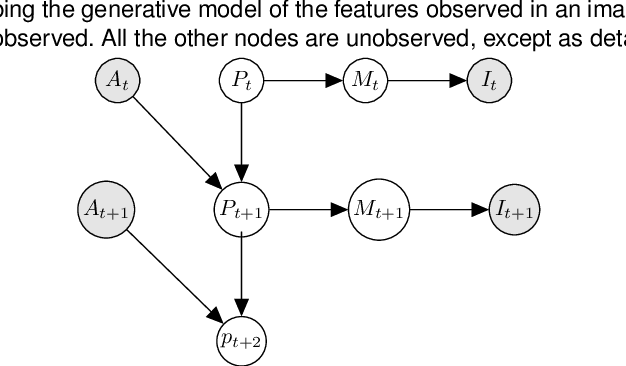

We introduce a novel formulation for incorporating visual feedback in controlling robots. We define a generative model from actions to image observations of features on the end-effector. Inference in the model allows us to infer the robot state corresponding to target locations of the features. This, in turn, guides motion of the robot and allows for matching the target locations of the features in significantly fewer steps than state-of-the-art visual servoing methods. The training procedure for our model enables effective learning of the kinematics, feature structure, and camera parameters, simultaneously. This can be done with no prior information about the robot, structure, and cameras that observe it. Learning is done sample-efficiently and shows strong generalization to test data. Since our formulation is modular, we can modify components of our setup, like cameras and objects, and relearn them quickly online. Our method can handle noise in the observed state and noise in the controllers that we interact with. We demonstrate the effectiveness of our method by executing grasping and tight-fit insertions on robots with inaccurate controllers.
EDUQA: Educational Domain Question Answering System using Conceptual Network Mapping
Nov 12, 2019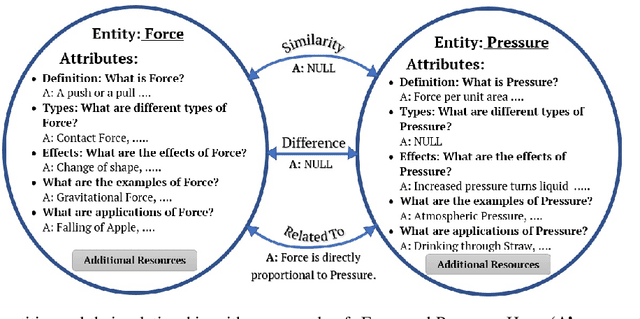

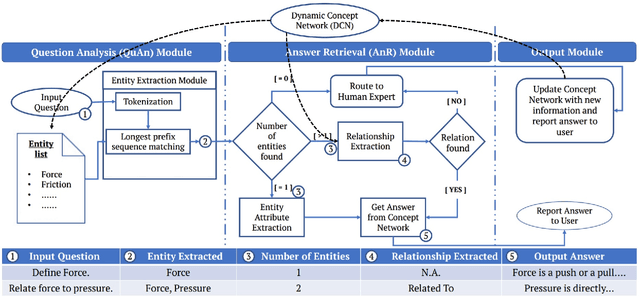

Most of the existing question answering models can be largely compiled into two categories: i) open domain question answering models that answer generic questions and use large-scale knowledge base along with the targeted web-corpus retrieval and ii) closed domain question answering models that address focused questioning area and use complex deep learning models. Both the above models derive answers through textual comprehension methods. Due to their inability to capture the pedagogical meaning of textual content, these models are not appropriately suited to the educational field for pedagogy. In this paper, we propose an on-the-fly conceptual network model that incorporates educational semantics. The proposed model preserves correlations between conceptual entities by applying intelligent indexing algorithms on the concept network so as to improve answer generation. This model can be utilized for building interactive conversational agents for aiding classroom learning.
* Published in the 44th International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2019
Online Convex Dictionary Learning
Apr 04, 2019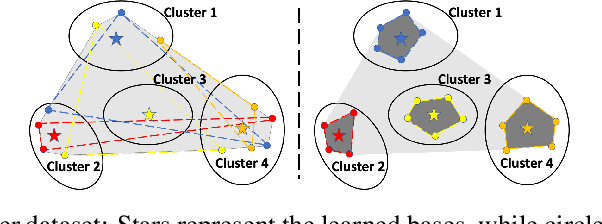
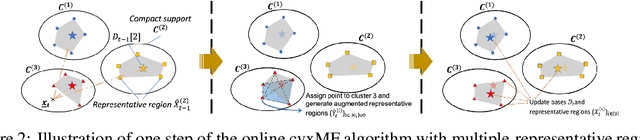


Dictionary learning is a dimensionality reduction technique widely used in data mining, machine learning and signal processing alike. Nevertheless, many dictionary learning algorithms such as variants of Matrix Factorization (MF) do not adequately scale with the size of available datasets. Furthermore, scalable dictionary learning methods lack interpretability of the derived dictionary matrix. To mitigate these two issues, we propose a novel low-complexity, batch online convex dictionary learning algorithm. The algorithm sequentially processes small batches of data maintained in a fixed amount of storage space, and produces meaningful dictionaries that satisfy convexity constraints. Our analytical results are two-fold. First, we establish convergence guarantees for the proposed online learning scheme. Second, we show that a subsequence of the generated dictionaries converges to a stationary point of the approximation-error function. Experimental results on synthetic and real world datasets demonstrate both the computational savings of the proposed online method with respect to convex non-negative MF, and performance guarantees comparable to those of online non-convex learning.