 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMatter: Perceiving Physical Objects with Generative Matter Models
Apr 24, 2026Human visual perception offers valuable insights for understanding computational principles of motion-based scene interpretation. Humans robustly detect and segment moving entities that constitute independently moveable chunks of matter, whether observing sparse moving dots, textured surfaces, or naturalistic scenes. In contrast, existing computer vision systems lack a unified approach that works across these diverse settings. Inspired by principles of human perception, we propose a generative model that hierarchically groups low-level motion cues and high-level appearance features into particles (small Gaussians representing local matter), and groups particles into clusters capturing coherently and independently moveable physical entities. We develop a hardware-accelerated inference algorithm based on parallelized block Gibbs sampling to recover stable particle motion and groupings. Our model operates on different kinds of inputs (random dots, stylized textures, or naturalistic RGB video), enabling it to work across settings where biological vision succeeds but existing computer vision approaches do not. We validate this unified framework across three domains: on 2D random dot kinematograms, our approach captures human object perception including graded uncertainty across ambiguous conditions; on a Gestalt-inspired dataset of camouflaged rotating objects, our approach recovers correct 3D structure from motion and thereby accurate 2D object segmentation; and on naturalistic RGB videos, our model tracks the moving 3D matter that makes up deforming objects, enabling robust object-level scene understanding. This work thus establishes a general framework for motion-based perception grounded in principles of human vision.
SceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Feb 26, 2026We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity. Code and models will be publicly available at https://2019epwl.github.io/SceneTransporter/.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

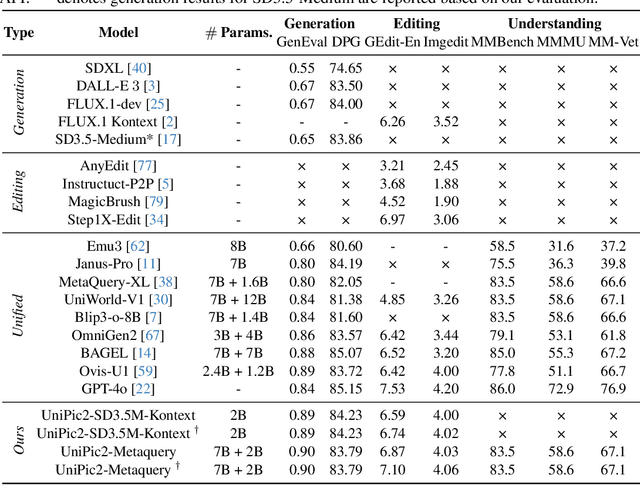
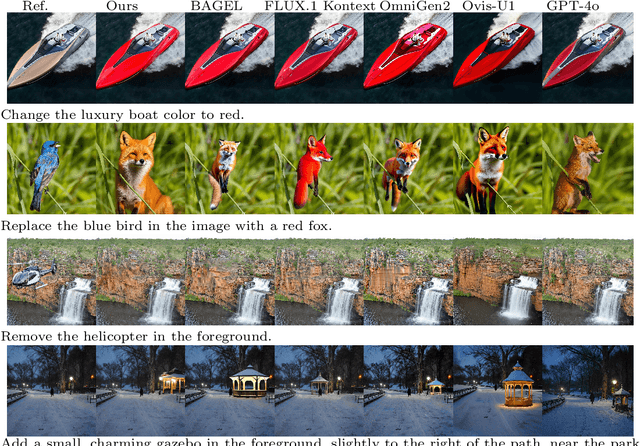
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights
Feb 18, 2025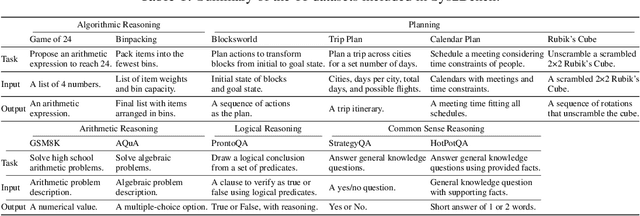

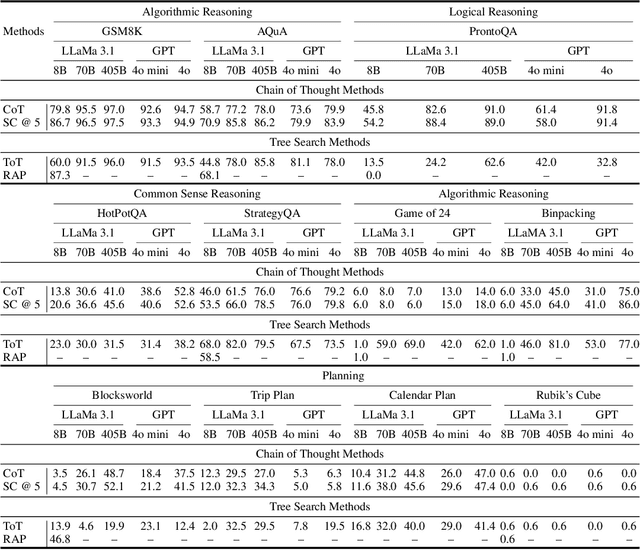

We examine the reasoning and planning capabilities of large language models (LLMs) in solving complex tasks. Recent advances in inference-time techniques demonstrate the potential to enhance LLM reasoning without additional training by exploring intermediate steps during inference. Notably, OpenAI's o1 model shows promising performance through its novel use of multi-step reasoning and verification. Here, we explore how scaling inference-time techniques can improve reasoning and planning, focusing on understanding the tradeoff between computational cost and performance. To this end, we construct a comprehensive benchmark, known as Sys2Bench, and perform extensive experiments evaluating existing inference-time techniques on eleven diverse tasks across five categories, including arithmetic reasoning, logical reasoning, common sense reasoning, algorithmic reasoning, and planning. Our findings indicate that simply scaling inference-time computation has limitations, as no single inference-time technique consistently performs well across all reasoning and planning tasks.
Flow-based Domain Randomization for Learning and Sequencing Robotic Skills
Feb 03, 2025



Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies trained in simulation. By randomizing environment properties during training, the learned policy can become robust to uncertainties along the randomized dimensions. While the environment distribution is typically specified by hand, in this paper we investigate automatically discovering a sampling distribution via entropy-regularized reward maximization of a normalizing-flow-based neural sampling distribution. We show that this architecture is more flexible and provides greater robustness than existing approaches that learn simpler, parameterized sampling distributions, as demonstrated in six simulated and one real-world robotics domain. Lastly, we explore how these learned sampling distributions, combined with a privileged value function, can be used for out-of-distribution detection in an uncertainty-aware multi-step manipulation planner.
WebSuite: Systematically Evaluating Why Web Agents Fail
Jun 01, 2024
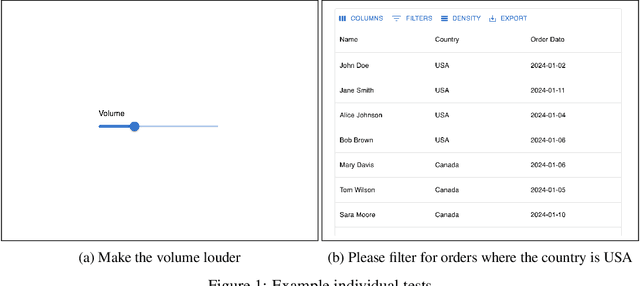

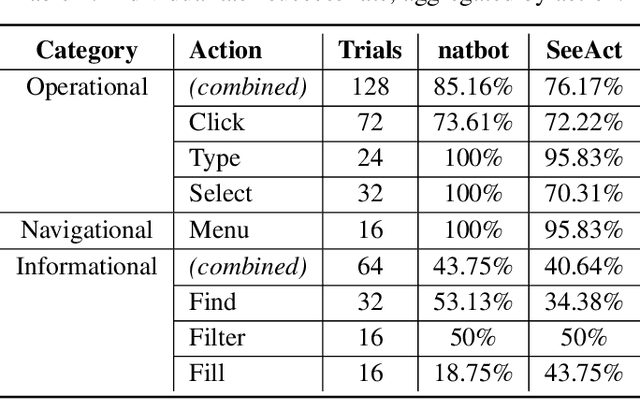
We describe WebSuite, the first diagnostic benchmark for generalist web agents, designed to systematically evaluate why agents fail. Advances in AI have led to the rise of numerous web agents that autonomously operate a browser to complete tasks. However, most existing benchmarks focus on strictly measuring whether an agent can or cannot complete a task, without giving insight on why. In this paper, we 1) develop a taxonomy of web actions to facilitate identifying common failure patterns, and 2) create an extensible benchmark suite to assess agents' performance on our taxonomized actions. This benchmark suite consists of both individual tasks, such as clicking a button, and end-to-end tasks, such as adding an item to a cart, and is designed such that any failure of a task can be attributed directly to a failure of a specific web action. We evaluate two popular generalist web agents, one text-based and one multimodal, and identify unique weaknesses for each agent. Because WebSuite can disaggregate task failures into specific action failures, this enables granular identification of which UX flows an individual agent has trouble with and immediately highlights promising avenues for improvement. These findings highlight the need for more focused benchmarking on where web agents go wrong to effectively improve agents beyond their weaker performance today.
Bayes3D: fast learning and inference in structured generative models of 3D objects and scenes
Dec 14, 2023



Robots cannot yet match humans' ability to rapidly learn the shapes of novel 3D objects and recognize them robustly despite clutter and occlusion. We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. Quantitative experiments show that Bayes3D can learn 3D models of novel objects from just a handful of views, recognizing them more robustly and with orders of magnitude less training data than neural baselines, and tracking 3D objects faster than real time on a single GPU. We also demonstrate that Bayes3D learns complex 3D object models and accurately infers 3D scene composition when used on a Panda robot in a tabletop scenario.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.