 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Entity-Guided Multi-Task Learning for Infrared and Visible Image Fusion
Jan 05, 2026Existing text-driven infrared and visible image fusion approaches often rely on textual information at the sentence level, which can lead to semantic noise from redundant text and fail to fully exploit the deeper semantic value of textual information. To address these issues, we propose a novel fusion approach named Entity-Guided Multi-Task learning for infrared and visible image fusion (EGMT). Our approach includes three key innovative components: (i) A principled method is proposed to extract entity-level textual information from image captions generated by large vision-language models, eliminating semantic noise from raw text while preserving critical semantic information; (ii) A parallel multi-task learning architecture is constructed, which integrates image fusion with a multi-label classification task. By using entities as pseudo-labels, the multi-label classification task provides semantic supervision, enabling the model to achieve a deeper understanding of image content and significantly improving the quality and semantic density of the fused image; (iii) An entity-guided cross-modal interactive module is also developed to facilitate the fine-grained interaction between visual and entity-level textual features, which enhances feature representation by capturing cross-modal dependencies at both inter-visual and visual-entity levels. To promote the wide application of the entity-guided image fusion framework, we release the entity-annotated version of four public datasets (i.e., TNO, RoadScene, M3FD, and MSRS). Extensive experiments demonstrate that EGMT achieves superior performance in preserving salient targets, texture details, and semantic consistency, compared to the state-of-the-art methods. The code and dataset will be publicly available at https://github.com/wyshao-01/EGMT.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

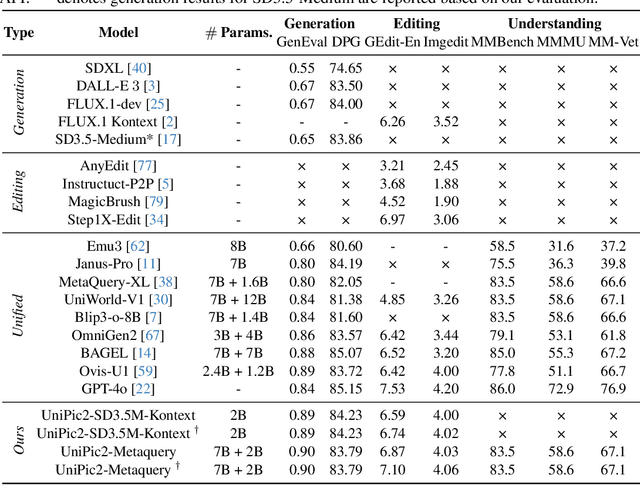
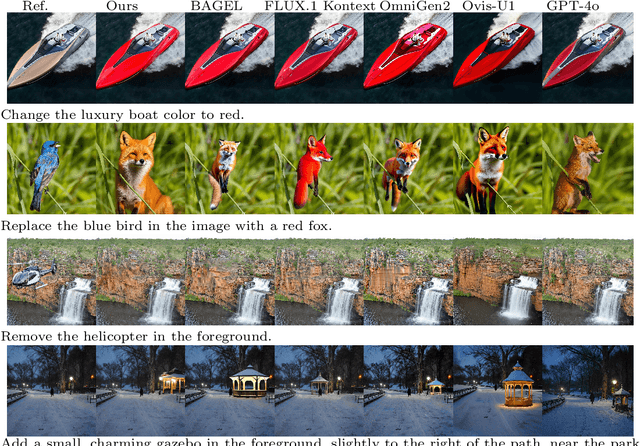
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Cut2Next: Generating Next Shot via In-Context Tuning
Aug 12, 2025Effective multi-shot generation demands purposeful, film-like transitions and strict cinematic continuity. Current methods, however, often prioritize basic visual consistency, neglecting crucial editing patterns (e.g., shot/reverse shot, cutaways) that drive narrative flow for compelling storytelling. This yields outputs that may be visually coherent but lack narrative sophistication and true cinematic integrity. To bridge this, we introduce Next Shot Generation (NSG): synthesizing a subsequent, high-quality shot that critically conforms to professional editing patterns while upholding rigorous cinematic continuity. Our framework, Cut2Next, leverages a Diffusion Transformer (DiT). It employs in-context tuning guided by a novel Hierarchical Multi-Prompting strategy. This strategy uses Relational Prompts to define overall context and inter-shot editing styles. Individual Prompts then specify per-shot content and cinematographic attributes. Together, these guide Cut2Next to generate cinematically appropriate next shots. Architectural innovations, Context-Aware Condition Injection (CACI) and Hierarchical Attention Mask (HAM), further integrate these diverse signals without introducing new parameters. We construct RawCuts (large-scale) and CuratedCuts (refined) datasets, both with hierarchical prompts, and introduce CutBench for evaluation. Experiments show Cut2Next excels in visual consistency and text fidelity. Crucially, user studies reveal a strong preference for Cut2Next, particularly for its adherence to intended editing patterns and overall cinematic continuity, validating its ability to generate high-quality, narratively expressive, and cinematically coherent subsequent shots.
ShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Jun 26, 2025Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60\% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.
Simplifying CLIP: Unleashing the Power of Large-Scale Models on Consumer-level Computers
Nov 22, 2024



Contrastive Language-Image Pre-training (CLIP) has attracted a surge of attention for its superior zero-shot performance and excellent transferability to downstream tasks. However, training such large-scale models usually requires substantial computation and storage, which poses barriers for general users with consumer-level computers. Motivated by this observation, in this paper we investigate how to achieve competitive performance on only one Nvidia RTX3090 GPU and with one terabyte for storing dataset. On one hand, we simplify the transformer block structure and combine Weight Inheritance with multi-stage Knowledge Distillation (WIKD), thereby reducing the parameters and improving the inference speed during training along with deployment. On the other hand, confronted with the convergence challenge posed by small dataset, we generate synthetic captions for each sample as data augmentation, and devise a novel Pair Matching (PM) loss to fully exploit the distinguishment among positive and negative image-text pairs. Extensive experiments demonstrate that our model can achieve a new state-of-the-art datascale-parameter-accuracy tradeoff, which could further popularize the CLIP model in the related research community.
Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Sep 26, 2024



Leveraging the visual priors of pre-trained text-to-image diffusion models offers a promising solution to enhance zero-shot generalization in dense prediction tasks. However, existing methods often uncritically use the original diffusion formulation, which may not be optimal due to the fundamental differences between dense prediction and image generation. In this paper, we provide a systemic analysis of the diffusion formulation for the dense prediction, focusing on both quality and efficiency. And we find that the original parameterization type for image generation, which learns to predict noise, is harmful for dense prediction; the multi-step noising/denoising diffusion process is also unnecessary and challenging to optimize. Based on these insights, we introduce Lotus, a diffusion-based visual foundation model with a simple yet effective adaptation protocol for dense prediction. Specifically, Lotus is trained to directly predict annotations instead of noise, thereby avoiding harmful variance. We also reformulate the diffusion process into a single-step procedure, simplifying optimization and significantly boosting inference speed. Additionally, we introduce a novel tuning strategy called detail preserver, which achieves more accurate and fine-grained predictions. Without scaling up the training data or model capacity, Lotus achieves SoTA performance in zero-shot depth and normal estimation across various datasets. It also significantly enhances efficiency, being hundreds of times faster than most existing diffusion-based methods.
KUNPENG: An Embodied Large Model for Intelligent Maritime
Jul 12, 2024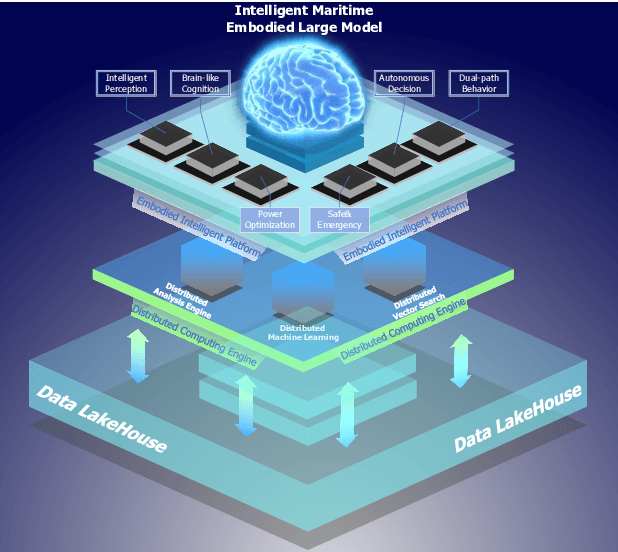
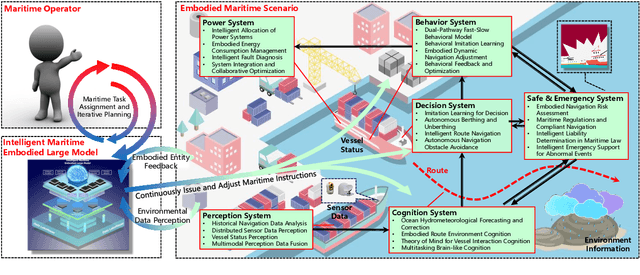
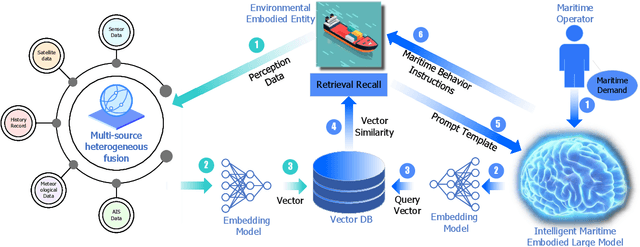
Intelligent maritime, as an essential component of smart ocean construction, deeply integrates advanced artificial intelligence technology and data analysis methods, which covers multiple aspects such as smart vessels, route optimization, safe navigation, aiming to enhance the efficiency of ocean resource utilization and the intelligence of transportation networks. However, the complex and dynamic maritime environment, along with diverse and heterogeneous large-scale data sources, present challenges for real-time decision-making in intelligent maritime. In this paper, We propose KUNPENG, the first-ever embodied large model for intelligent maritime in the smart ocean construction, which consists of six systems. The model perceives multi-source heterogeneous data for the cognition of environmental interaction and make autonomous decision strategies, which are used for intelligent vessels to perform navigation behaviors under safety and emergency guarantees and continuously optimize power to achieve embodied intelligence in maritime. In comprehensive maritime task evaluations, KUNPENG has demonstrated excellent performance.
PTM-VQA: Efficient Video Quality Assessment Leveraging Diverse PreTrained Models from the Wild
May 28, 2024

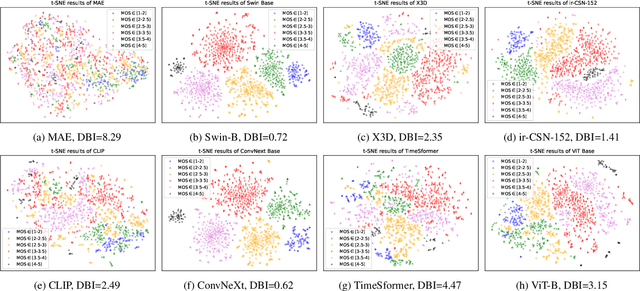

Video quality assessment (VQA) is a challenging problem due to the numerous factors that can affect the perceptual quality of a video, \eg, content attractiveness, distortion type, motion pattern, and level. However, annotating the Mean opinion score (MOS) for videos is expensive and time-consuming, which limits the scale of VQA datasets, and poses a significant obstacle for deep learning-based methods. In this paper, we propose a VQA method named PTM-VQA, which leverages PreTrained Models to transfer knowledge from models pretrained on various pre-tasks, enabling benefits for VQA from different aspects. Specifically, we extract features of videos from different pretrained models with frozen weights and integrate them to generate representation. Since these models possess various fields of knowledge and are often trained with labels irrelevant to quality, we propose an Intra-Consistency and Inter-Divisibility (ICID) loss to impose constraints on features extracted by multiple pretrained models. The intra-consistency constraint ensures that features extracted by different pretrained models are in the same unified quality-aware latent space, while the inter-divisibility introduces pseudo clusters based on the annotation of samples and tries to separate features of samples from different clusters. Furthermore, with a constantly growing number of pretrained models, it is crucial to determine which models to use and how to use them. To address this problem, we propose an efficient scheme to select suitable candidates. Models with better clustering performance on VQA datasets are chosen to be our candidates. Extensive experiments demonstrate the effectiveness of the proposed method.