 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACPO: Adaptive Curriculum Policy Optimization for Aligning Vision-Language Models in Complex Reasoning
Oct 01, 2025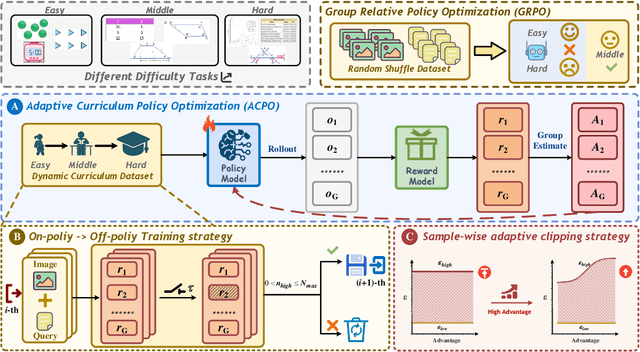


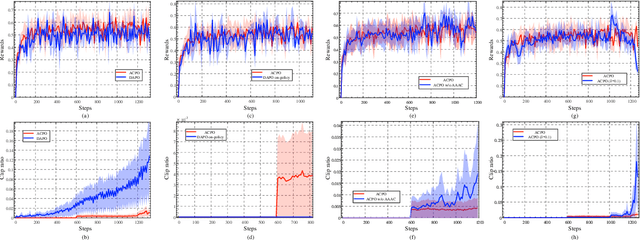
Aligning large-scale vision-language models (VLMs) for complex reasoning via reinforcement learning is often hampered by the limitations of existing policy optimization algorithms, such as static training schedules and the rigid, uniform clipping mechanism in Proximal Policy Optimization (PPO). In this work, we introduce Adaptive Curriculum Policy Optimization (ACPO), a novel framework that addresses these challenges through a dual-component adaptive learning strategy. First, ACPO employs a dynamic curriculum that orchestrates a principled transition from a stable, near on-policy exploration phase to an efficient, off-policy exploitation phase by progressively increasing sample reuse. Second, we propose an Advantage-Aware Adaptive Clipping (AAAC) mechanism that replaces the fixed clipping hyperparameter with dynamic, sample-wise bounds modulated by the normalized advantage of each token. This allows for more granular and robust policy updates, enabling larger gradients for high-potential samples while safeguarding against destructive ones. We conduct extensive experiments on a suite of challenging multimodal reasoning benchmarks, including MathVista, LogicVista, and MMMU-Pro. Results demonstrate that ACPO consistently outperforms strong baselines such as DAPO and PAPO, achieving state-of-the-art performance, accelerated convergence, and superior training stability.
Linear Preference Optimization: Decoupled Gradient Control via Absolute Regularization
Aug 20, 2025DPO (Direct Preference Optimization) has become a widely used offline preference optimization algorithm due to its simplicity and training stability. However, DPO is prone to overfitting and collapse. To address these challenges, we propose Linear Preference Optimization (LPO), a novel alignment framework featuring three key innovations. First, we introduce gradient decoupling by replacing the log-sigmoid function with an absolute difference loss, thereby isolating the optimization dynamics. Second, we improve stability through an offset constraint combined with a positive regularization term to preserve the chosen response quality. Third, we implement controllable rejection suppression using gradient separation with straightforward estimation and a tunable coefficient that linearly regulates the descent of the rejection probability. Through extensive experiments, we demonstrate that LPO consistently improves performance on various tasks, including general text tasks, math tasks, and text-to-speech (TTS) tasks. These results establish LPO as a robust and tunable paradigm for preference alignment, and we release the source code, models, and training data publicly.
Noise Analysis and Hierarchical Adaptive Body State Estimator For Biped Robot Walking With ESVC Foot
Jun 10, 2025The ESVC(Ellipse-based Segmental Varying Curvature) foot, a robot foot design inspired by the rollover shape of the human foot, significantly enhances the energy efficiency of the robot walking gait. However, due to the tilt of the supporting leg, the error of the contact model are amplified, making robot state estimation more challenging. Therefore, this paper focuses on the noise analysis and state estimation for robot walking with the ESVC foot. First, through physical robot experiments, we investigate the effect of the ESVC foot on robot measurement noise and process noise. and a noise-time regression model using sliding window strategy is developed. Then, a hierarchical adaptive state estimator for biped robots with the ESVC foot is proposed. The state estimator consists of two stages: pre-estimation and post-estimation. In the pre-estimation stage, a data fusion-based estimation is employed to process the sensory data. During post-estimation, the acceleration of center of mass is first estimated, and then the noise covariance matrices are adjusted based on the regression model. Following that, an EKF(Extended Kalman Filter) based approach is applied to estimate the centroid state during robot walking. Physical experiments demonstrate that the proposed adaptive state estimator for biped robot walking with the ESVC foot not only provides higher precision than both EKF and Adaptive EKF, but also converges faster under varying noise conditions.
Model Analysis And Design Of Ellipse Based Segmented Varying Curved Foot For Biped Robot Walking
Jun 08, 2025This paper presents the modeling, design, and experimental validation of an Ellipse-based Segmented Varying Curvature (ESVC) foot for bipedal robots. Inspired by the segmented curvature rollover shape of human feet, the ESVC foot aims to enhance gait energy efficiency while maintaining analytical tractability for foot location based controller. First, we derive a complete analytical contact model for the ESVC foot by formulating spatial transformations of elliptical segments only using elementary functions. Then a nonlinear programming approach is engaged to determine optimal elliptical parameters of hind foot and fore foot based on a known mid-foot. An error compensation method is introduced to address approximation inaccuracies in rollover length calculation. The proposed ESVC foot is then integrated with a Hybrid Linear Inverted Pendulum model-based walking controller and validated through both simulation and physical experiments on the TT II biped robot. Experimental results across marking time, sagittal, and lateral walking tasks show that the ESVC foot consistently reduces energy consumption compared to line, and flat feet, with up to 18.52\% improvement in lateral walking. These findings demonstrate that the ESVC foot provides a practical and energy-efficient alternative for real-world bipedal locomotion. The proposed design methodology also lays a foundation for data-driven foot shape optimization in future research.
Diffusion Models for Molecules: A Survey of Methods and Tasks
Feb 13, 2025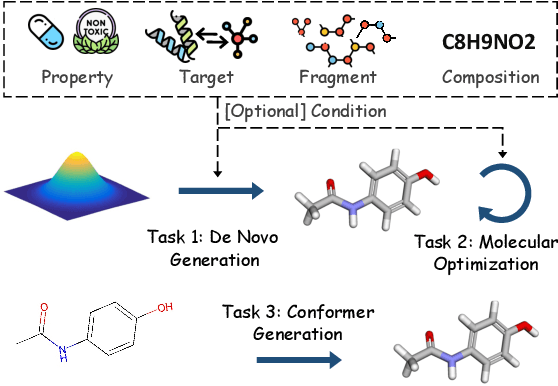
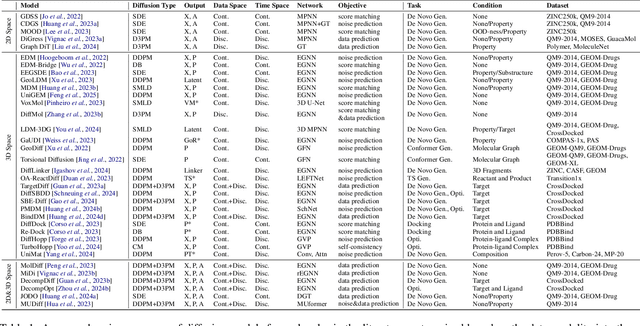
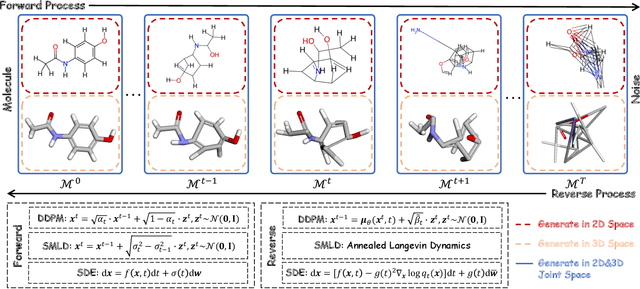
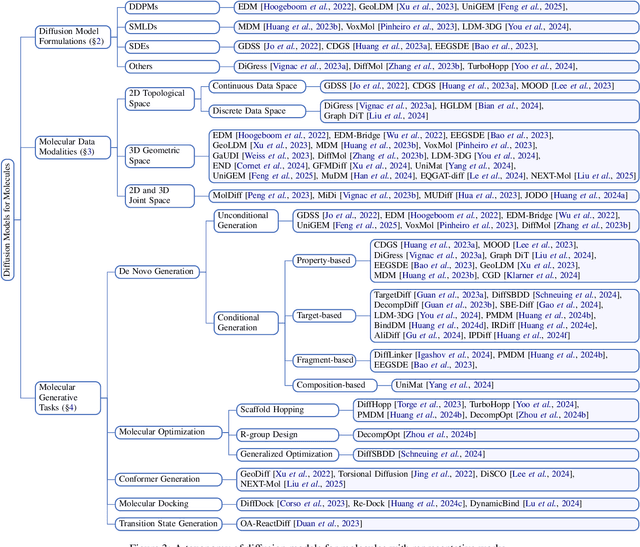
Generative tasks about molecules, including but not limited to molecule generation, are crucial for drug discovery and material design, and have consistently attracted significant attention. In recent years, diffusion models have emerged as an impressive class of deep generative models, sparking extensive research and leading to numerous studies on their application to molecular generative tasks. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. Particularly, due to the diversity of diffusion model formulations, molecular data modalities, and generative task types, the research landscape is challenging to navigate, hindering understanding and limiting the area's growth. To address this, this paper conducts a comprehensive survey of diffusion model-based molecular generative methods. We systematically review the research from the perspectives of methodological formulations, data modalities, and task types, offering a novel taxonomy. This survey aims to facilitate understanding and further flourishing development in this area. The relevant papers are summarized at: https://github.com/AzureLeon1/awesome-molecular-diffusion-models.
Probing many-body Bell correlation depth with superconducting qubits
Jun 25, 2024


Quantum nonlocality describes a stronger form of quantum correlation than that of entanglement. It refutes Einstein's belief of local realism and is among the most distinctive and enigmatic features of quantum mechanics. It is a crucial resource for achieving quantum advantages in a variety of practical applications, ranging from cryptography and certified random number generation via self-testing to machine learning. Nevertheless, the detection of nonlocality, especially in quantum many-body systems, is notoriously challenging. Here, we report an experimental certification of genuine multipartite Bell correlations, which signal nonlocality in quantum many-body systems, up to 24 qubits with a fully programmable superconducting quantum processor. In particular, we employ energy as a Bell correlation witness and variationally decrease the energy of a many-body system across a hierarchy of thresholds, below which an increasing Bell correlation depth can be certified from experimental data. As an illustrating example, we variationally prepare the low-energy state of a two-dimensional honeycomb model with 73 qubits and certify its Bell correlations by measuring an energy that surpasses the corresponding classical bound with up to 48 standard deviations. In addition, we variationally prepare a sequence of low-energy states and certify their genuine multipartite Bell correlations up to 24 qubits via energies measured efficiently by parity oscillation and multiple quantum coherence techniques. Our results establish a viable approach for preparing and certifying multipartite Bell correlations, which provide not only a finer benchmark beyond entanglement for quantum devices, but also a valuable guide towards exploiting multipartite Bell correlation in a wide spectrum of practical applications.
A Framework to Implement 1+N Multi-task Fine-tuning Pattern in LLMs Using the CGC-LORA Algorithm
Jan 22, 2024With the productive evolution of large language models (LLMs) in the field of natural language processing (NLP), tons of effort has been made to effectively fine-tune common pre-trained LLMs to fulfill a variety of tasks in one or multiple specific domain. In practice, there are two prevailing ways, in which the adaptation can be achieved: (i) Multiple Independent Models: Pre-trained LLMs are fine-tuned a few times independently using the corresponding training samples from each task. (ii) An Integrated Model: Samples from all tasks are employed to fine-tune a pre-trianed LLM unitedly. To address the high computing cost and seesawing issue simultaneously, we propose a unified framework that implements a 1 + N mutli-task fine-tuning pattern in LLMs using a novel Customized Gate Control (CGC) Low-rank Adaptation (LoRA) algorithm. Our work aims to take an advantage of both MTL (i.e., CGC) and PEFT (i.e., LoRA) scheme. For a given cluster of tasks, we design an innovative layer that contains two types of experts as additional trainable parameters to make LoRA be compatible with MTL. To comprehensively evaluate the proposed framework, we conduct well-designed experiments on two public datasets. The experimental results demonstrate that the unified framework with CGC-LoRA modules achieves higher evaluation scores than all benchmarks on both two datasets.
AdaptSSR: Pre-training User Model with Augmentation-Adaptive Self-Supervised Ranking
Oct 24, 2023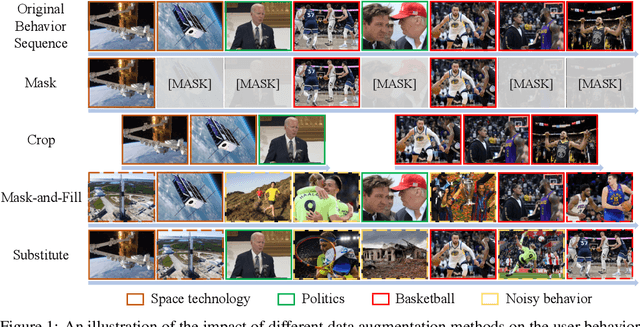
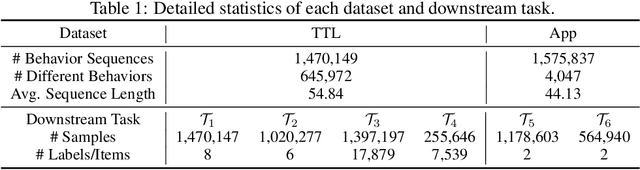
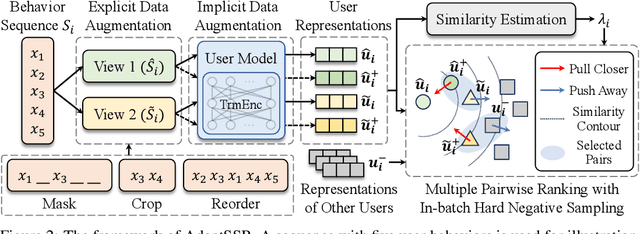
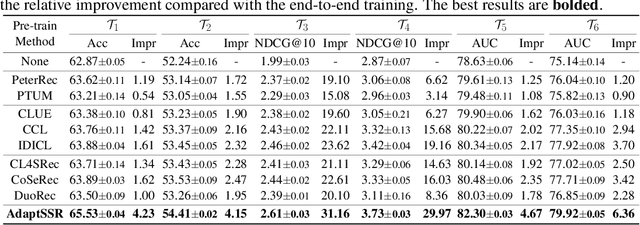
User modeling, which aims to capture users' characteristics or interests, heavily relies on task-specific labeled data and suffers from the data sparsity issue. Several recent studies tackled this problem by pre-training the user model on massive user behavior sequences with a contrastive learning task. Generally, these methods assume different views of the same behavior sequence constructed via data augmentation are semantically consistent, i.e., reflecting similar characteristics or interests of the user, and thus maximizing their agreement in the feature space. However, due to the diverse interests and heavy noise in user behaviors, existing augmentation methods tend to lose certain characteristics of the user or introduce noisy behaviors. Thus, forcing the user model to directly maximize the similarity between the augmented views may result in a negative transfer. To this end, we propose to replace the contrastive learning task with a new pretext task: Augmentation-Adaptive SelfSupervised Ranking (AdaptSSR), which alleviates the requirement of semantic consistency between the augmented views while pre-training a discriminative user model. Specifically, we adopt a multiple pairwise ranking loss which trains the user model to capture the similarity orders between the implicitly augmented view, the explicitly augmented view, and views from other users. We further employ an in-batch hard negative sampling strategy to facilitate model training. Moreover, considering the distinct impacts of data augmentation on different behavior sequences, we design an augmentation-adaptive fusion mechanism to automatically adjust the similarity order constraint applied to each sample based on the estimated similarity between the augmented views. Extensive experiments on both public and industrial datasets with six downstream tasks verify the effectiveness of AdaptSSR.
G2PTL: A Pre-trained Model for Delivery Address and its Applications in Logistics System
Apr 04, 2023



Text-based delivery addresses, as the data foundation for logistics systems, contain abundant and crucial location information. How to effectively encode the delivery address is a core task to boost the performance of downstream tasks in the logistics system. Pre-trained Models (PTMs) designed for Natural Language Process (NLP) have emerged as the dominant tools for encoding semantic information in text. Though promising, those NLP-based PTMs fall short of encoding geographic knowledge in the delivery address, which considerably trims down the performance of delivery-related tasks in logistic systems such as Cainiao. To tackle the above problem, we propose a domain-specific pre-trained model, named G2PTL, a Geography-Graph Pre-trained model for delivery address in Logistics field. G2PTL combines the semantic learning capabilities of text pre-training with the geographical-relationship encoding abilities of graph modeling. Specifically, we first utilize real-world logistics delivery data to construct a large-scale heterogeneous graph of delivery addresses, which contains abundant geographic knowledge and delivery information. Then, G2PTL is pre-trained with subgraphs sampled from the heterogeneous graph. Comprehensive experiments are conducted to demonstrate the effectiveness of G2PTL through four downstream tasks in logistics systems on real-world datasets. G2PTL has been deployed in production in Cainiao's logistics system, which significantly improves the performance of delivery-related tasks.
Siamese Encoder-based Spatial-Temporal Mixer for Growth Trend Prediction of Lung Nodules on CT Scans
Jun 07, 2022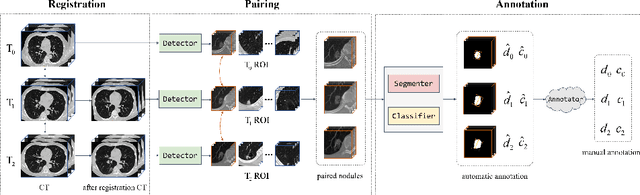
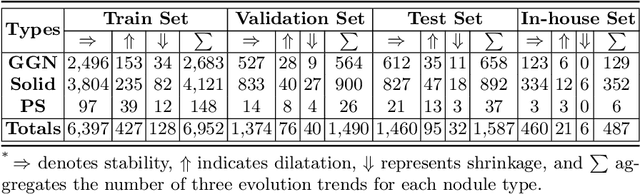
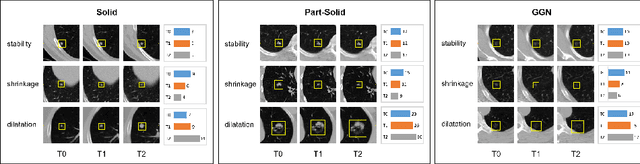
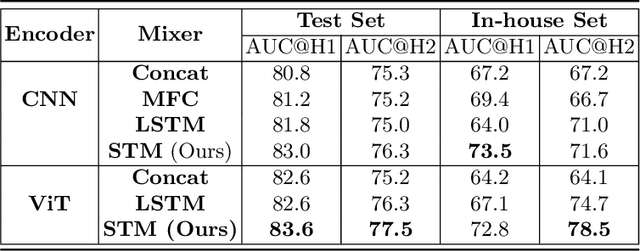
In the management of lung nodules, we are desirable to predict nodule evolution in terms of its diameter variation on Computed Tomography (CT) scans and then provide a follow-up recommendation according to the predicted result of the growing trend of the nodule. In order to improve the performance of growth trend prediction for lung nodules, it is vital to compare the changes of the same nodule in consecutive CT scans. Motivated by this, we screened out 4,666 subjects with more than two consecutive CT scans from the National Lung Screening Trial (NLST) dataset to organize a temporal dataset called NLSTt. In specific, we first detect and pair regions of interest (ROIs) covering the same nodule based on registered CT scans. After that, we predict the texture category and diameter size of the nodules through models. Last, we annotate the evolution class of each nodule according to its changes in diameter. Based on the built NLSTt dataset, we propose a siamese encoder to simultaneously exploit the discriminative features of 3D ROIs detected from consecutive CT scans. Then we novelly design a spatial-temporal mixer (STM) to leverage the interval changes of the same nodule in sequential 3D ROIs and capture spatial dependencies of nodule regions and the current 3D ROI. According to the clinical diagnosis routine, we employ hierarchical loss to pay more attention to growing nodules. The extensive experiments on our organized dataset demonstrate the advantage of our proposed method. We also conduct experiments on an in-house dataset to evaluate the clinical utility of our method by comparing it against skilled clinicians.