 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Collapse-Aware multi-Scale Topology Fusion for Multimodal Coreset Selection
May 12, 2026The training of large multimodal models fundamentally relies on massive image-text datasets, which inevitably incur prohibitive computational overhead. Dataset selection offers a promising paradigm by identifying a highly informative coreset. However, existing approaches suffer from two critical limitations: (i) single-modality-dominated sampling methods, which ignore the fine-grained cross-modal information imbalance inherent in multimodal datasets and thus lead to semantic loss in the other modality; and (ii) coarse-grained sample-scoring-based sampling methods, where the selected coreset tends to be biased toward the scoring model, making it difficult to guarantee distributional equivalence between the coreset and the original dataset. Meanwhile, existing distribution matching and discrete sampling strategies often fail to jointly account for global semantic structure, local fine-grained details, and redundancy-aware coverage in dense regions. To this end, we propose CAST, a Collapse-Aware multi-Scale Topology fusion framework for multimodal coreset selection. We first construct image- and text-modality topologies, and derive a unified topology via local-collapse-aware refinement and cross-modal fusion. We then introduce a multi-scale distribution matching criterion in the diffusion wavelet domain, encouraging the coreset to approximate the original dataset at multiple scales. Finally, we introduce a local soft relational coverage mechanism that extends pure geometric coverage to relation-aware indirect coverage, penalizing redundant selections in dense clusters. Extensive experiments on Flickr30K and MS-COCO show that CAST outperforms existing dataset selection baselines, showcasing great superiority in cross-architecture generalization and energy efficiency over state-of-the-art multimodal synthesis methods.
SIGformer: Sign-aware Graph Transformer for Recommendation
Apr 18, 2024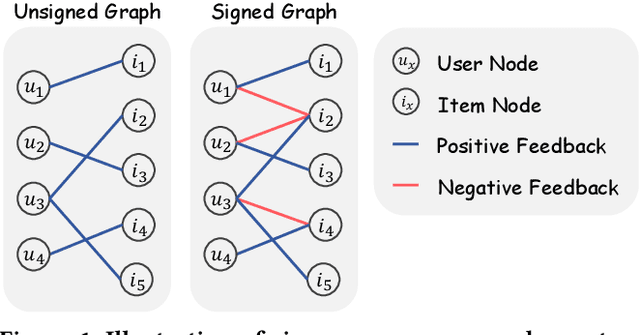
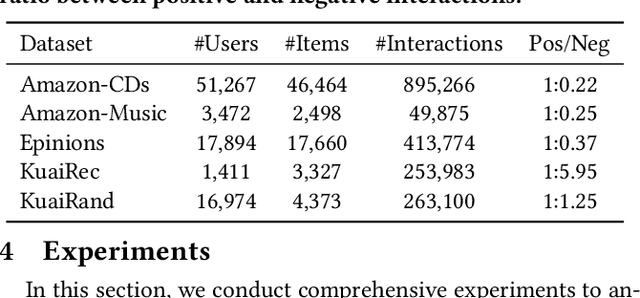
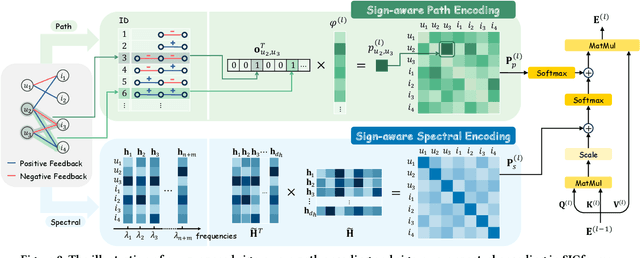
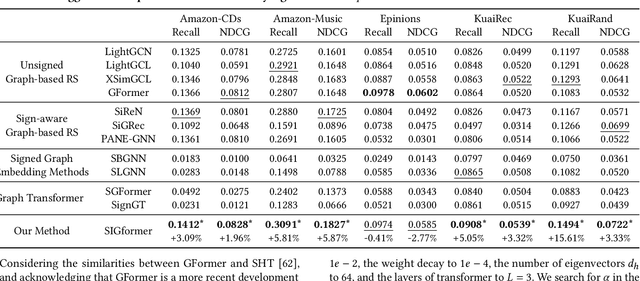
In recommender systems, most graph-based methods focus on positive user feedback, while overlooking the valuable negative feedback. Integrating both positive and negative feedback to form a signed graph can lead to a more comprehensive understanding of user preferences. However, the existing efforts to incorporate both types of feedback are sparse and face two main limitations: 1) They process positive and negative feedback separately, which fails to holistically leverage the collaborative information within the signed graph; 2) They rely on MLPs or GNNs for information extraction from negative feedback, which may not be effective. To overcome these limitations, we introduce SIGformer, a new method that employs the transformer architecture to sign-aware graph-based recommendation. SIGformer incorporates two innovative positional encodings that capture the spectral properties and path patterns of the signed graph, enabling the full exploitation of the entire graph. Our extensive experiments across five real-world datasets demonstrate the superiority of SIGformer over state-of-the-art methods. The code is available at https://github.com/StupidThree/SIGformer.
AdaptSSR: Pre-training User Model with Augmentation-Adaptive Self-Supervised Ranking
Oct 24, 2023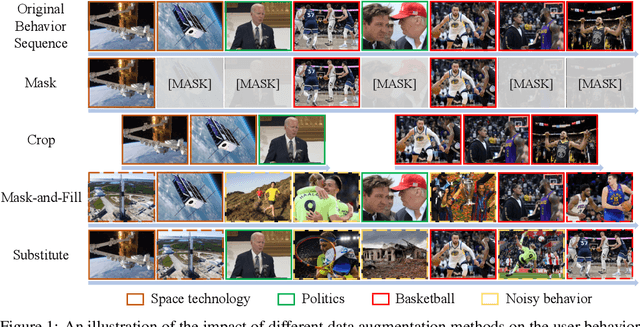
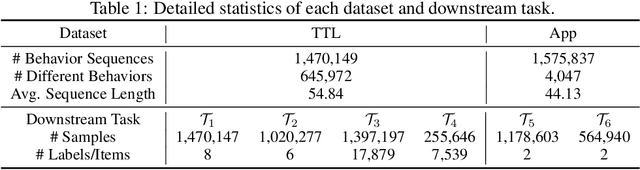
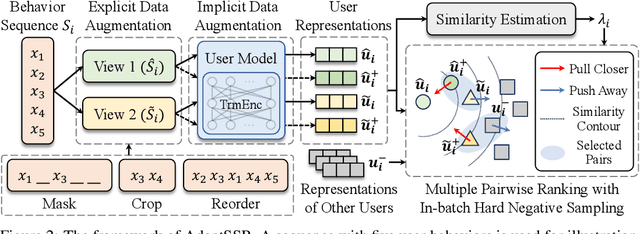
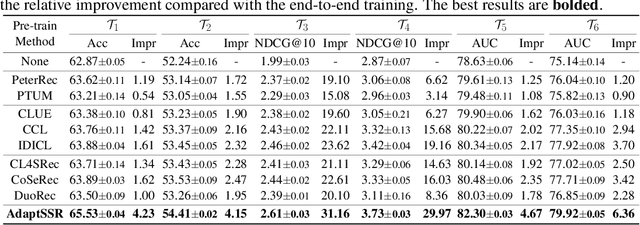
User modeling, which aims to capture users' characteristics or interests, heavily relies on task-specific labeled data and suffers from the data sparsity issue. Several recent studies tackled this problem by pre-training the user model on massive user behavior sequences with a contrastive learning task. Generally, these methods assume different views of the same behavior sequence constructed via data augmentation are semantically consistent, i.e., reflecting similar characteristics or interests of the user, and thus maximizing their agreement in the feature space. However, due to the diverse interests and heavy noise in user behaviors, existing augmentation methods tend to lose certain characteristics of the user or introduce noisy behaviors. Thus, forcing the user model to directly maximize the similarity between the augmented views may result in a negative transfer. To this end, we propose to replace the contrastive learning task with a new pretext task: Augmentation-Adaptive SelfSupervised Ranking (AdaptSSR), which alleviates the requirement of semantic consistency between the augmented views while pre-training a discriminative user model. Specifically, we adopt a multiple pairwise ranking loss which trains the user model to capture the similarity orders between the implicitly augmented view, the explicitly augmented view, and views from other users. We further employ an in-batch hard negative sampling strategy to facilitate model training. Moreover, considering the distinct impacts of data augmentation on different behavior sequences, we design an augmentation-adaptive fusion mechanism to automatically adjust the similarity order constraint applied to each sample based on the estimated similarity between the augmented views. Extensive experiments on both public and industrial datasets with six downstream tasks verify the effectiveness of AdaptSSR.