 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGformer: Sign-aware Graph Transformer for Recommendation
Apr 18, 2024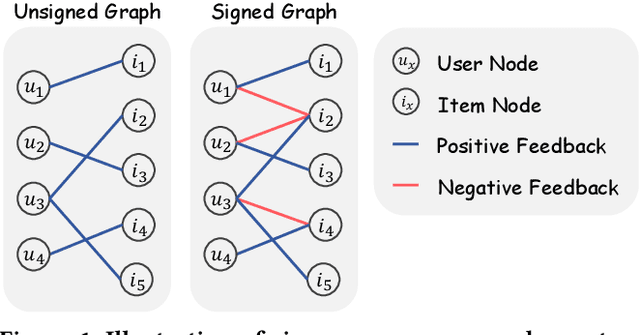
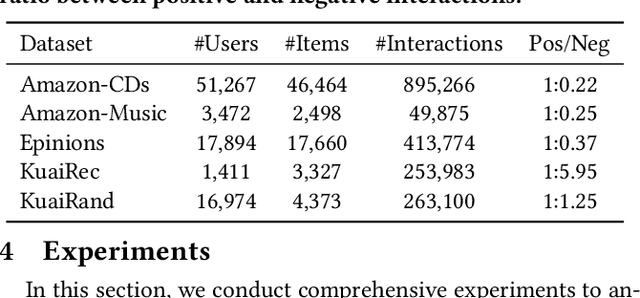
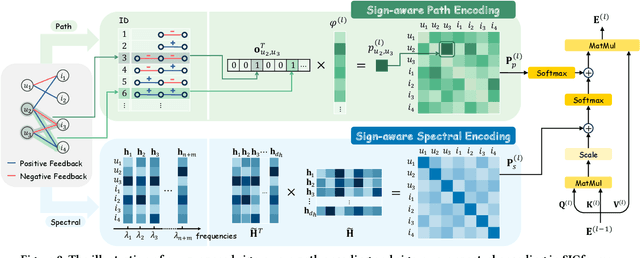
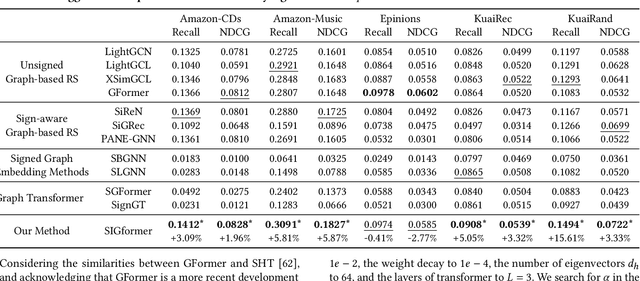
In recommender systems, most graph-based methods focus on positive user feedback, while overlooking the valuable negative feedback. Integrating both positive and negative feedback to form a signed graph can lead to a more comprehensive understanding of user preferences. However, the existing efforts to incorporate both types of feedback are sparse and face two main limitations: 1) They process positive and negative feedback separately, which fails to holistically leverage the collaborative information within the signed graph; 2) They rely on MLPs or GNNs for information extraction from negative feedback, which may not be effective. To overcome these limitations, we introduce SIGformer, a new method that employs the transformer architecture to sign-aware graph-based recommendation. SIGformer incorporates two innovative positional encodings that capture the spectral properties and path patterns of the signed graph, enabling the full exploitation of the entire graph. Our extensive experiments across five real-world datasets demonstrate the superiority of SIGformer over state-of-the-art methods. The code is available at https://github.com/StupidThree/SIGformer.
An Ensemble Noise-Robust K-fold Cross-Validation Selection Method for Noisy Labels
Jul 06, 2021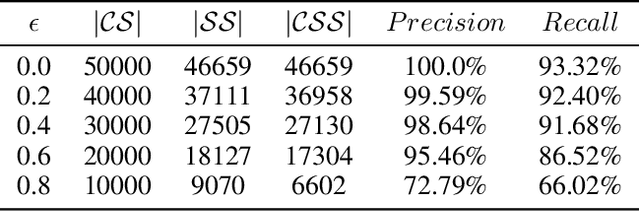


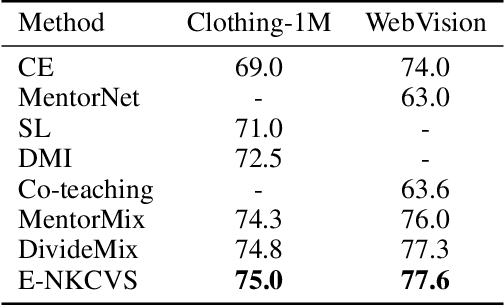
We consider the problem of training robust and accurate deep neural networks (DNNs) when subject to various proportions of noisy labels. Large-scale datasets tend to contain mislabeled samples that can be memorized by DNNs, impeding the performance. With appropriate handling, this degradation can be alleviated. There are two problems to consider: how to distinguish clean samples and how to deal with noisy samples. In this paper, we present Ensemble Noise-robust K-fold Cross-Validation Selection (E-NKCVS) to effectively select clean samples from noisy data, solving the first problem. For the second problem, we create a new pseudo label for any sample determined to have an uncertain or likely corrupt label. E-NKCVS obtains multiple predicted labels for each sample and the entropy of these labels is used to tune the weight given to the pseudo label and the given label. Theoretical analysis and extensive verification of the algorithms in the noisy label setting are provided. We evaluate our approach on various image and text classification tasks where the labels have been manually corrupted with different noise ratios. Additionally, two large real-world noisy datasets are also used, Clothing-1M and WebVision. E-NKCVS is empirically shown to be highly tolerant to considerable proportions of label noise and has a consistent improvement over state-of-the-art methods. Especially on more difficult datasets with higher noise ratios, we can achieve a significant improvement over the second-best model. Moreover, our proposed approach can easily be integrated into existing DNN methods to improve their robustness against label noise.