 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Counter-Examples for Active Learning with Partial labels
Jul 14, 2023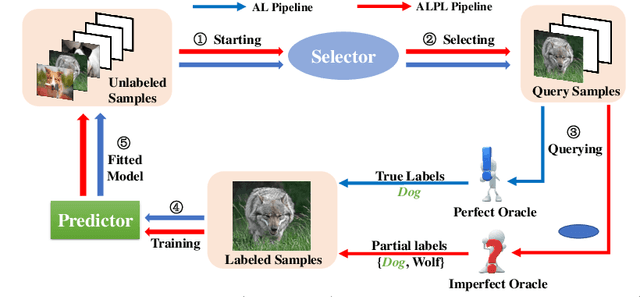
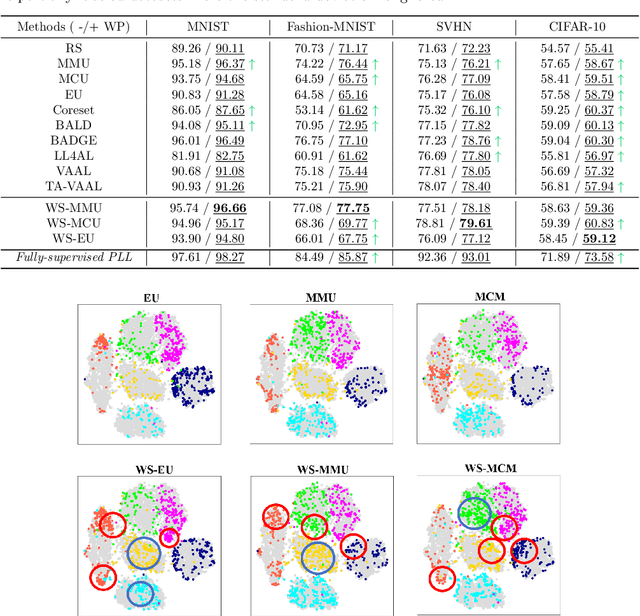
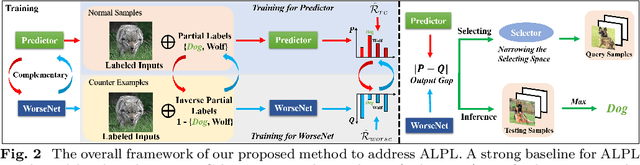
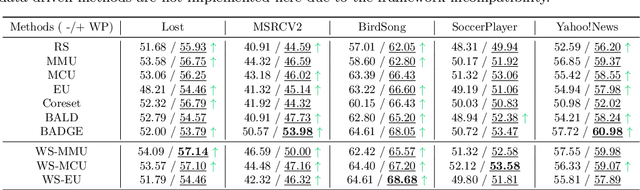
This paper studies a new problem, \emph{active learning with partial labels} (ALPL). In this setting, an oracle annotates the query samples with partial labels, relaxing the oracle from the demanding accurate labeling process. To address ALPL, we first build an intuitive baseline that can be seamlessly incorporated into existing AL frameworks. Though effective, this baseline is still susceptible to the \emph{overfitting}, and falls short of the representative partial-label-based samples during the query process. Drawing inspiration from human inference in cognitive science, where accurate inferences can be explicitly derived from \emph{counter-examples} (CEs), our objective is to leverage this human-like learning pattern to tackle the \emph{overfitting} while enhancing the process of selecting representative samples in ALPL. Specifically, we construct CEs by reversing the partial labels for each instance, and then we propose a simple but effective WorseNet to directly learn from this complementary pattern. By leveraging the distribution gap between WorseNet and the predictor, this adversarial evaluation manner could enhance both the performance of the predictor itself and the sample selection process, allowing the predictor to capture more accurate patterns in the data. Experimental results on five real-world datasets and four benchmark datasets show that our proposed method achieves comprehensive improvements over ten representative AL frameworks, highlighting the superiority of WorseNet. The source code will be available at \url{https://github.com/Ferenas/APLL}.
Out-of-distribution Detection with Implicit Outlier Transformation
Mar 09, 2023Outlier exposure (OE) is powerful in out-of-distribution (OOD) detection, enhancing detection capability via model fine-tuning with surrogate OOD data. However, surrogate data typically deviate from test OOD data. Thus, the performance of OE, when facing unseen OOD data, can be weakened. To address this issue, we propose a novel OE-based approach that makes the model perform well for unseen OOD situations, even for unseen OOD cases. It leads to a min-max learning scheme -- searching to synthesize OOD data that leads to worst judgments and learning from such OOD data for uniform performance in OOD detection. In our realization, these worst OOD data are synthesized by transforming original surrogate ones. Specifically, the associated transform functions are learned implicitly based on our novel insight that model perturbation leads to data transformation. Our methodology offers an efficient way of synthesizing OOD data, which can further benefit the detection model, besides the surrogate OOD data. We conduct extensive experiments under various OOD detection setups, demonstrating the effectiveness of our method against its advanced counterparts.
Exploit CAM by itself: Complementary Learning System for Weakly Supervised Semantic Segmentation
Mar 04, 2023



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has long been suffering from fragmentary object regions led by Class Activation Map (CAM), which is incapable of generating fine-grained masks for semantic segmentation. To guide CAM to find more non-discriminating object patterns, this paper turns to an interesting working mechanism in agent learning named Complementary Learning System (CLS). CLS holds that the neocortex builds a sensation of general knowledge, while the hippocampus specially learns specific details, completing the learned patterns. Motivated by this simple but effective learning pattern, we propose a General-Specific Learning Mechanism (GSLM) to explicitly drive a coarse-grained CAM to a fine-grained pseudo mask. Specifically, GSLM develops a General Learning Module (GLM) and a Specific Learning Module (SLM). The GLM is trained with image-level supervision to extract coarse and general localization representations from CAM. Based on the general knowledge in the GLM, the SLM progressively exploits the specific spatial knowledge from the localization representations, expanding the CAM in an explicit way. To this end, we propose the Seed Reactivation to help SLM reactivate non-discriminating regions by setting a boundary for activation values, which successively identifies more regions of CAM. Without extra refinement processes, our method is able to achieve breakthrough improvements for CAM of over 20.0% mIoU on PASCAL VOC 2012 and 10.0% mIoU on MS COCO 2014 datasets, representing a new state-of-the-art among existing WSSS methods.
RiskLoc: Localization of Multi-dimensional Root Causes by Weighted Risk
May 20, 2022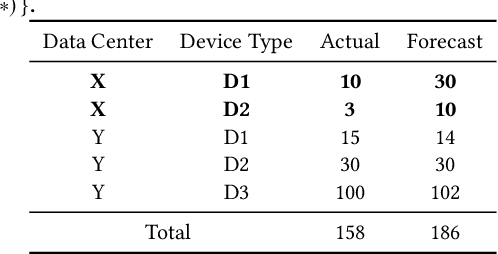
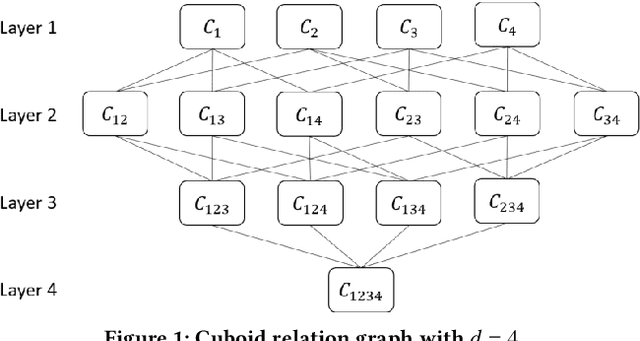
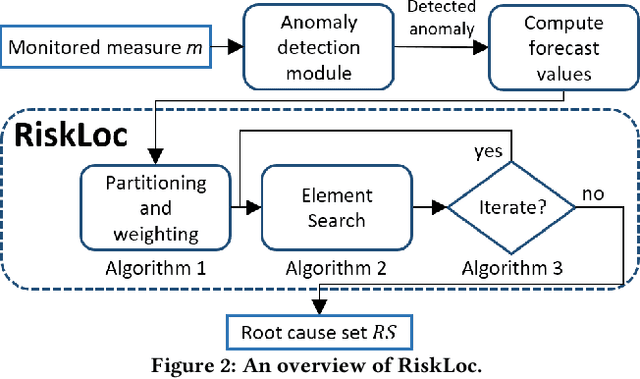
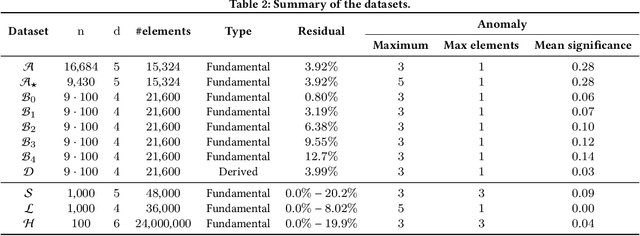
Failures and anomalies in large-scale software systems are unavoidable incidents. When an issue is detected, operators need to quickly and correctly identify its location to facilitate a swift repair. In this work, we consider the problem of identifying the root cause set that best explains an anomaly in multi-dimensional time series with categorical attributes. The huge search space is the main challenge, even for a small number of attributes and small value sets, the number of theoretical combinations is too large to brute force. Previous approaches have thus focused on reducing the search space, but they all suffer from various issues, requiring extensive manual parameter tuning, being too slow and thus impractical, or being incapable of finding more complex root causes. We propose RiskLoc to solve the problem of multidimensional root cause localization. RiskLoc applies a 2-way partitioning scheme and assigns element weights that linearly increase with the distance from the partitioning point. A risk score is assigned to each element that integrates two factors, 1) its weighted proportion within the abnormal partition, and 2) the relative change in the deviation score adjusted for the ripple effect property. Extensive experiments on multiple datasets verify the effectiveness and efficiency of RiskLoc, and for a comprehensive evaluation, we introduce three synthetically generated datasets that complement existing datasets. We demonstrate that RiskLoc consistently outperforms state-of-the-art baselines, especially in more challenging root cause scenarios, with gains in F1-score up to 57% over the second-best approach with comparable running times.
gCastle: A Python Toolbox for Causal Discovery
Nov 30, 2021
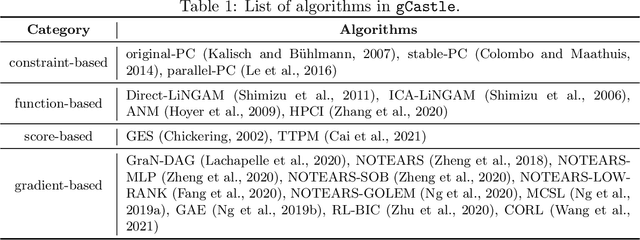
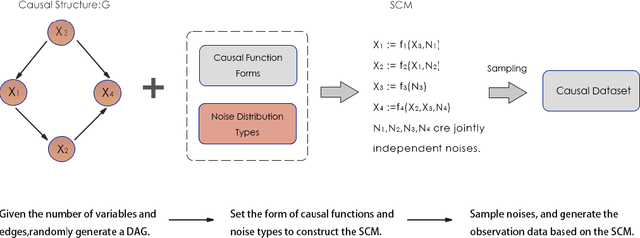
$\texttt{gCastle}$ is an end-to-end Python toolbox for causal structure learning. It provides functionalities of generating data from either simulator or real-world dataset, learning causal structure from the data, and evaluating the learned graph, together with useful practices such as prior knowledge insertion, preliminary neighborhood selection, and post-processing to remove false discoveries. Compared with related packages, $\texttt{gCastle}$ includes many recently developed gradient-based causal discovery methods with optional GPU acceleration. $\texttt{gCastle}$ brings convenience to researchers who may directly experiment with the code as well as practitioners with graphical user interference. Three real-world datasets in telecommunications are also provided in the current version. $\texttt{gCastle}$ is available under Apache License 2.0 at \url{https://github.com/huawei-noah/trustworthyAI/tree/master/gcastle}.
Discrete-time Temporal Network Embedding via Implicit Hierarchical Learning in Hyperbolic Space
Jul 08, 2021

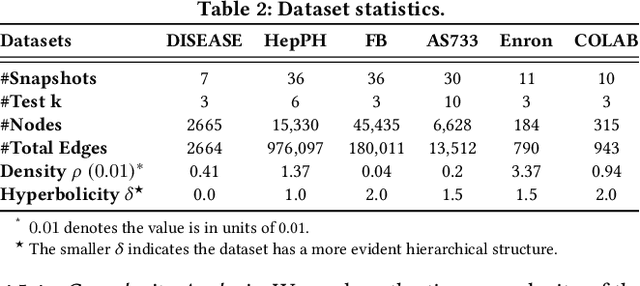
Representation learning over temporal networks has drawn considerable attention in recent years. Efforts are mainly focused on modeling structural dependencies and temporal evolving regularities in Euclidean space which, however, underestimates the inherent complex and hierarchical properties in many real-world temporal networks, leading to sub-optimal embeddings. To explore these properties of a complex temporal network, we propose a hyperbolic temporal graph network (HTGN) that fully takes advantage of the exponential capacity and hierarchical awareness of hyperbolic geometry. More specially, HTGN maps the temporal graph into hyperbolic space, and incorporates hyperbolic graph neural network and hyperbolic gated recurrent neural network, to capture the evolving behaviors and implicitly preserve hierarchical information simultaneously. Furthermore, in the hyperbolic space, we propose two important modules that enable HTGN to successfully model temporal networks: (1) hyperbolic temporal contextual self-attention (HTA) module to attend to historical states and (2) hyperbolic temporal consistency (HTC) module to ensure stability and generalization. Experimental results on multiple real-world datasets demonstrate the superiority of HTGN for temporal graph embedding, as it consistently outperforms competing methods by significant margins in various temporal link prediction tasks. Specifically, HTGN achieves AUC improvement up to 9.98% for link prediction and 11.4% for new link prediction. Moreover, the ablation study further validates the representational ability of hyperbolic geometry and the effectiveness of the proposed HTA and HTC modules.
An Ensemble Noise-Robust K-fold Cross-Validation Selection Method for Noisy Labels
Jul 06, 2021


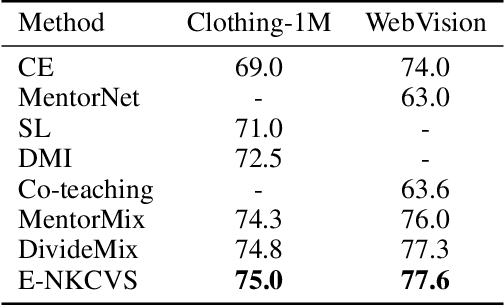
We consider the problem of training robust and accurate deep neural networks (DNNs) when subject to various proportions of noisy labels. Large-scale datasets tend to contain mislabeled samples that can be memorized by DNNs, impeding the performance. With appropriate handling, this degradation can be alleviated. There are two problems to consider: how to distinguish clean samples and how to deal with noisy samples. In this paper, we present Ensemble Noise-robust K-fold Cross-Validation Selection (E-NKCVS) to effectively select clean samples from noisy data, solving the first problem. For the second problem, we create a new pseudo label for any sample determined to have an uncertain or likely corrupt label. E-NKCVS obtains multiple predicted labels for each sample and the entropy of these labels is used to tune the weight given to the pseudo label and the given label. Theoretical analysis and extensive verification of the algorithms in the noisy label setting are provided. We evaluate our approach on various image and text classification tasks where the labels have been manually corrupted with different noise ratios. Additionally, two large real-world noisy datasets are also used, Clothing-1M and WebVision. E-NKCVS is empirically shown to be highly tolerant to considerable proportions of label noise and has a consistent improvement over state-of-the-art methods. Especially on more difficult datasets with higher noise ratios, we can achieve a significant improvement over the second-best model. Moreover, our proposed approach can easily be integrated into existing DNN methods to improve their robustness against label noise.
An Influence-based Approach for Root Cause Alarm Discovery in Telecom Networks
May 07, 2021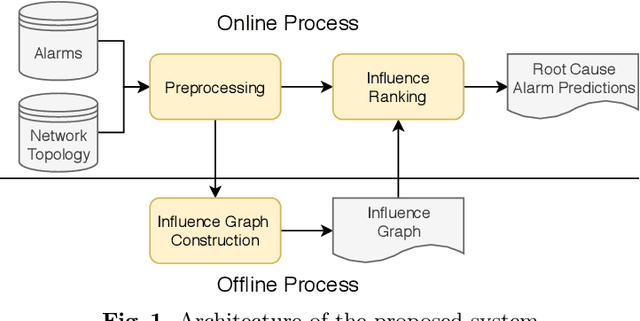
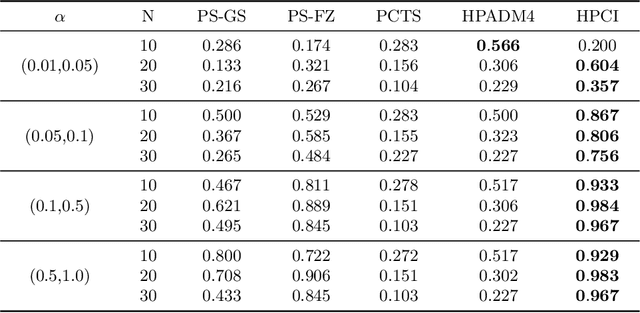
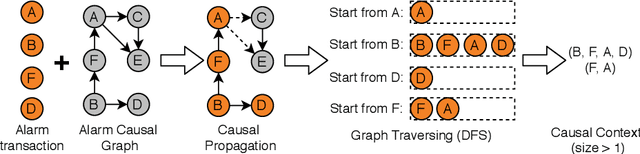
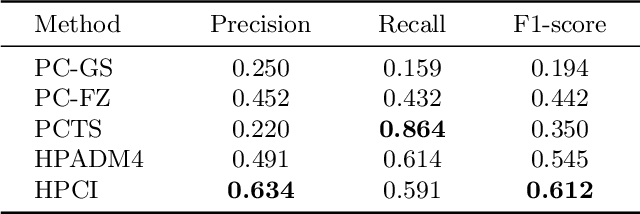
Alarm root cause analysis is a significant component in the day-to-day telecommunication network maintenance, and it is critical for efficient and accurate fault localization and failure recovery. In practice, accurate and self-adjustable alarm root cause analysis is a great challenge due to network complexity and vast amounts of alarms. A popular approach for failure root cause identification is to construct a graph with approximate edges, commonly based on either event co-occurrences or conditional independence tests. However, considerable expert knowledge is typically required for edge pruning. We propose a novel data-driven framework for root cause alarm localization, combining both causal inference and network embedding techniques. In this framework, we design a hybrid causal graph learning method (HPCI), which combines Hawkes Process with Conditional Independence tests, as well as propose a novel Causal Propagation-Based Embedding algorithm (CPBE) to infer edge weights. We subsequently discover root cause alarms in a real-time data stream by applying an influence maximization algorithm on the weighted graph. We evaluate our method on artificial data and real-world telecom data, showing a significant improvement over the best baselines.
Spatio-Temporal Hybrid Graph Convolutional Network for Traffic Forecasting in Telecommunication Networks
Sep 17, 2020



Telecommunication networks play a critical role in modern society. With the arrival of 5G networks, these systems are becoming even more diversified, integrated, and intelligent. Traffic forecasting is one of the key components in such a system, however, it is particularly challenging due to the complex spatial-temporal dependency. In this work, we consider this problem from the aspect of a cellular network and the interactions among its base stations. We thoroughly investigate the characteristics of cellular network traffic and shed light on the dependency complexities based on data collected from a densely populated metropolis area. Specifically, we observe that the traffic shows both dynamic and static spatial dependencies as well as diverse cyclic temporal patterns. To address these complexities, we propose an effective deep-learning-based approach, namely, Spatio-Temporal Hybrid Graph Convolutional Network (STHGCN). It employs GRUs to model the temporal dependency, while capturing the complex spatial dependency through a hybrid-GCN from three perspectives: spatial proximity, functional similarity, and recent trend similarity. We conduct extensive experiments on real-world traffic datasets collected from telecommunication networks. Our experimental results demonstrate the superiority of the proposed model in that it consistently outperforms both classical methods and state-of-the-art deep learning models, while being more robust and stable.