 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Feb 19, 2024



This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose \textbf{S}mart \textbf{P}arallel \textbf{A}uto-\textbf{C}orrect d\textbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Jan 25, 2024Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022



Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021



There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.
Spatio-Temporal Hybrid Graph Convolutional Network for Traffic Forecasting in Telecommunication Networks
Sep 17, 2020



Telecommunication networks play a critical role in modern society. With the arrival of 5G networks, these systems are becoming even more diversified, integrated, and intelligent. Traffic forecasting is one of the key components in such a system, however, it is particularly challenging due to the complex spatial-temporal dependency. In this work, we consider this problem from the aspect of a cellular network and the interactions among its base stations. We thoroughly investigate the characteristics of cellular network traffic and shed light on the dependency complexities based on data collected from a densely populated metropolis area. Specifically, we observe that the traffic shows both dynamic and static spatial dependencies as well as diverse cyclic temporal patterns. To address these complexities, we propose an effective deep-learning-based approach, namely, Spatio-Temporal Hybrid Graph Convolutional Network (STHGCN). It employs GRUs to model the temporal dependency, while capturing the complex spatial dependency through a hybrid-GCN from three perspectives: spatial proximity, functional similarity, and recent trend similarity. We conduct extensive experiments on real-world traffic datasets collected from telecommunication networks. Our experimental results demonstrate the superiority of the proposed model in that it consistently outperforms both classical methods and state-of-the-art deep learning models, while being more robust and stable.
A Parallelizable Acceleration Framework for Packing Linear Programs
Nov 17, 2017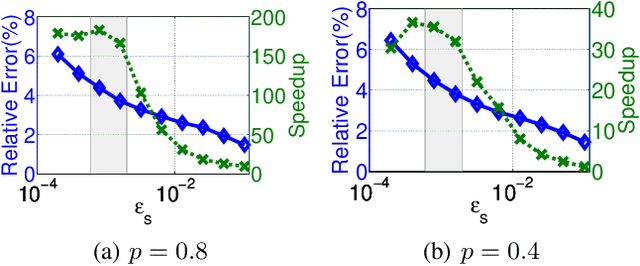
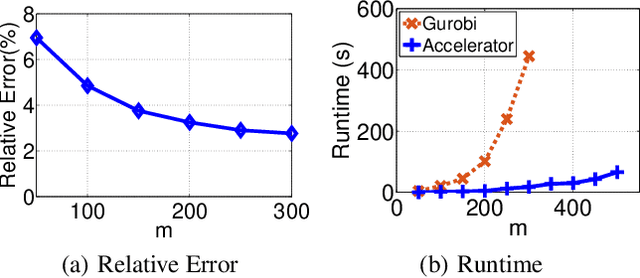
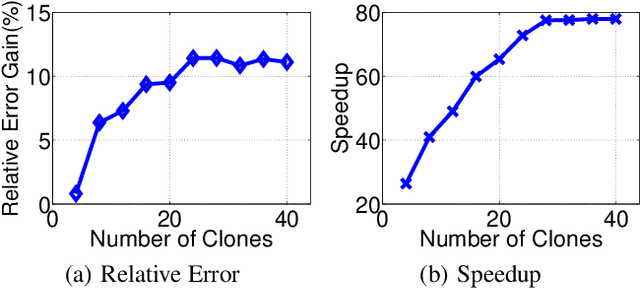
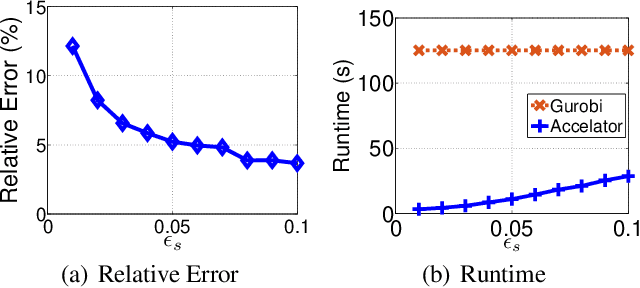
This paper presents an acceleration framework for packing linear programming problems where the amount of data available is limited, i.e., where the number of constraints m is small compared to the variable dimension n. The framework can be used as a black box to speed up linear programming solvers dramatically, by two orders of magnitude in our experiments. We present worst-case guarantees on the quality of the solution and the speedup provided by the algorithm, showing that the framework provides an approximately optimal solution while running the original solver on a much smaller problem. The framework can be used to accelerate exact solvers, approximate solvers, and parallel/distributed solvers. Further, it can be used for both linear programs and integer linear programs.