 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Feb 19, 2024



This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose \textbf{S}mart \textbf{P}arallel \textbf{A}uto-\textbf{C}orrect d\textbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
1st Place Solution for ICDAR 2021 Competition on Mathematical Formula Detection
Jul 12, 2021
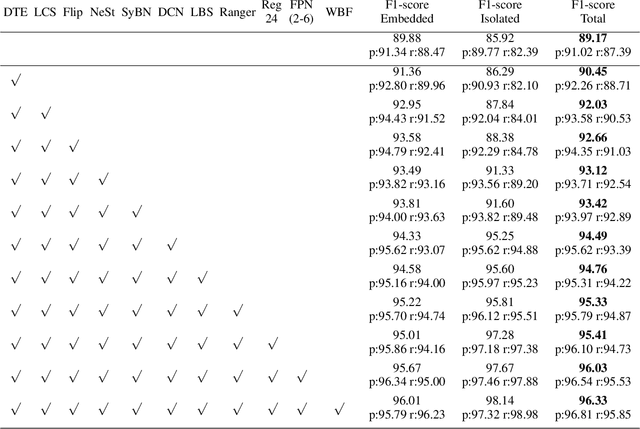
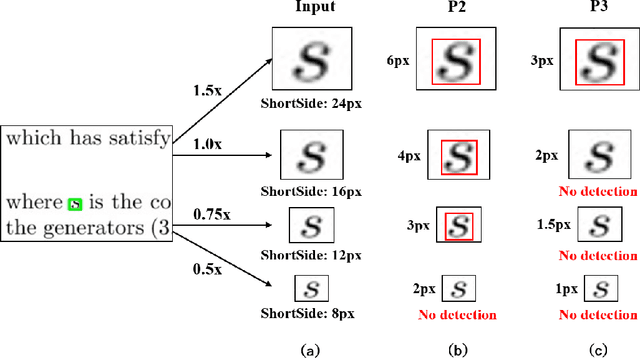
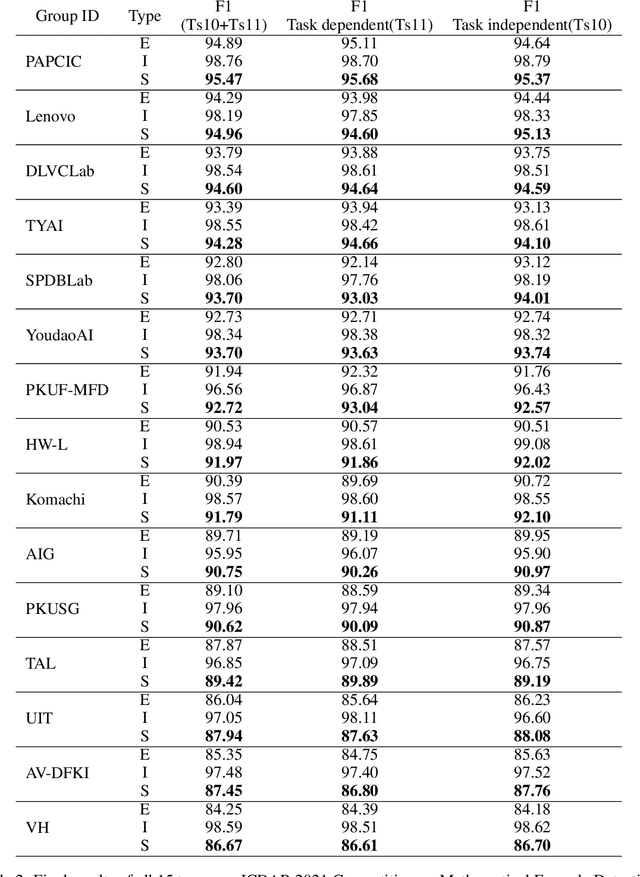
In this technical report, we present our 1st place solution for the ICDAR 2021 competition on mathematical formula detection (MFD). The MFD task has three key challenges including a large scale span, large variation of the ratio between height and width, and rich character set and mathematical expressions. Considering these challenges, we used Generalized Focal Loss (GFL), an anchor-free method, instead of the anchor-based method, and prove the Adaptive Training Sampling Strategy (ATSS) and proper Feature Pyramid Network (FPN) can well solve the important issue of scale variation. Meanwhile, we also found some tricks, e.g., Deformable Convolution Network (DCN), SyncBN, and Weighted Box Fusion (WBF), were effective in MFD task. Our proposed method ranked 1st in the final 15 teams.