 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
Dec 14, 2024



Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
Improving Adversarial Robustness via Feature Pattern Consistency Constraint
Jun 13, 2024



Convolutional Neural Networks (CNNs) are well-known for their vulnerability to adversarial attacks, posing significant security concerns. In response to these threats, various defense methods have emerged to bolster the model's robustness. However, most existing methods either focus on learning from adversarial perturbations, leading to overfitting to the adversarial examples, or aim to eliminate such perturbations during inference, inevitably increasing computational burdens. Conversely, clean training, which strengthens the model's robustness by relying solely on clean examples, can address the aforementioned issues. In this paper, we align with this methodological stream and enhance its generalizability to unknown adversarial examples. This enhancement is achieved by scrutinizing the behavior of latent features within the network. Recognizing that a correct prediction relies on the correctness of the latent feature's pattern, we introduce a novel and effective Feature Pattern Consistency Constraint (FPCC) method to reinforce the latent feature's capacity to maintain the correct feature pattern. Specifically, we propose Spatial-wise Feature Modification and Channel-wise Feature Selection to enhance latent features. Subsequently, we employ the Pattern Consistency Loss to constrain the similarity between the feature pattern of the latent features and the correct feature pattern. Our experiments demonstrate that the FPCC method empowers latent features to uphold correct feature patterns even in the face of adversarial examples, resulting in inherent adversarial robustness surpassing state-of-the-art models.
Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Feb 19, 2024



This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose \textbf{S}mart \textbf{P}arallel \textbf{A}uto-\textbf{C}orrect d\textbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Jan 25, 2024Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022



Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Model Doctor: A Simple Gradient Aggregation Strategy for Diagnosing and Treating CNN Classifiers
Dec 09, 2021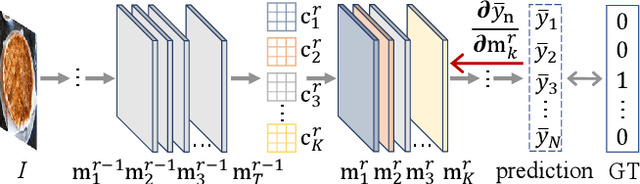
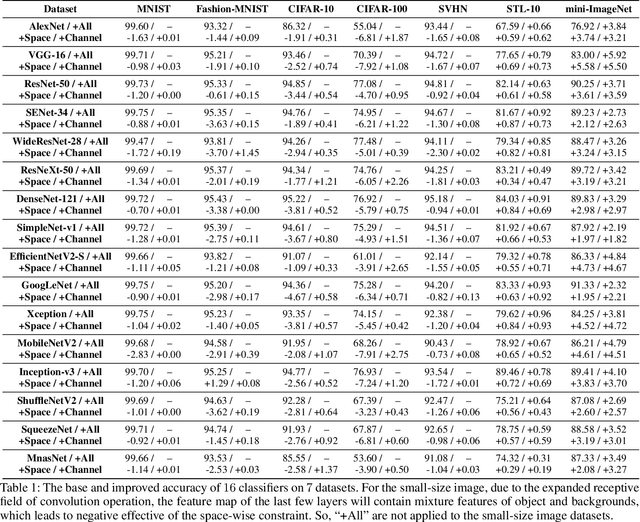
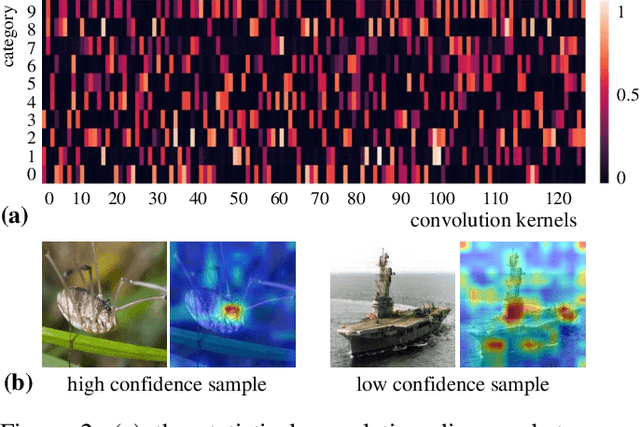

Recently, Convolutional Neural Network (CNN) has achieved excellent performance in the classification task. It is widely known that CNN is deemed as a 'black-box', which is hard for understanding the prediction mechanism and debugging the wrong prediction. Some model debugging and explanation works are developed for solving the above drawbacks. However, those methods focus on explanation and diagnosing possible causes for model prediction, based on which the researchers handle the following optimization of models manually. In this paper, we propose the first completely automatic model diagnosing and treating tool, termed as Model Doctor. Based on two discoveries that 1) each category is only correlated with sparse and specific convolution kernels, and 2) adversarial samples are isolated while normal samples are successive in the feature space, a simple aggregate gradient constraint is devised for effectively diagnosing and optimizing CNN classifiers. The aggregate gradient strategy is a versatile module for mainstream CNN classifiers. Extensive experiments demonstrate that the proposed Model Doctor applies to all existing CNN classifiers, and improves the accuracy of $16$ mainstream CNN classifiers by 1%-5%.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021



There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.
Contextual Bandits with Random Projection
Mar 20, 2019Contextual bandits with linear payoffs, which are also known as linear bandits, provide a powerful alternative for solving practical problems of sequential decisions, e.g., online advertisements. In the era of big data, contextual data usually tend to be high-dimensional, which leads to new challenges for traditional linear bandits mostly designed for the setting of low-dimensional contextual data. Due to the curse of dimensionality, there are two challenges in most of the current bandit algorithms: the first is high time-complexity; and the second is extreme large upper regret bounds with high-dimensional data. In this paper, in order to attack the above two challenges effectively, we develop an algorithm of Contextual Bandits via RAndom Projection (\texttt{CBRAP}) in the setting of linear payoffs, which works especially for high-dimensional contextual data. The proposed \texttt{CBRAP} algorithm is time-efficient and flexible, because it enables players to choose an arm in a low-dimensional space, and relaxes the sparsity assumption of constant number of non-zero components in previous work. Besides, we provide a linear upper regret bound for the proposed algorithm, which is associated with reduced dimensions.
Almost Optimal Algorithms for Linear Stochastic Bandits with Heavy-Tailed Payoffs
Oct 25, 2018



In linear stochastic bandits, it is commonly assumed that payoffs are with sub-Gaussian noises. In this paper, under a weaker assumption on noises, we study the problem of \underline{lin}ear stochastic {\underline b}andits with h{\underline e}avy-{\underline t}ailed payoffs (LinBET), where the distributions have finite moments of order $1+\epsilon$, for some $\epsilon\in (0,1]$. We rigorously analyze the regret lower bound of LinBET as $\Omega(T^{\frac{1}{1+\epsilon}})$, implying that finite moments of order 2 (i.e., finite variances) yield the bound of $\Omega(\sqrt{T})$, with $T$ being the total number of rounds to play bandits. The provided lower bound also indicates that the state-of-the-art algorithms for LinBET are far from optimal. By adopting median of means with a well-designed allocation of decisions and truncation based on historical information, we develop two novel bandit algorithms, where the regret upper bounds match the lower bound up to polylogarithmic factors. To the best of our knowledge, we are the first to solve LinBET optimally in the sense of the polynomial order on $T$. Our proposed algorithms are evaluated based on synthetic datasets, and outperform the state-of-the-art results.