 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee the Text: From Tokenization to Visual Reading
Oct 21, 2025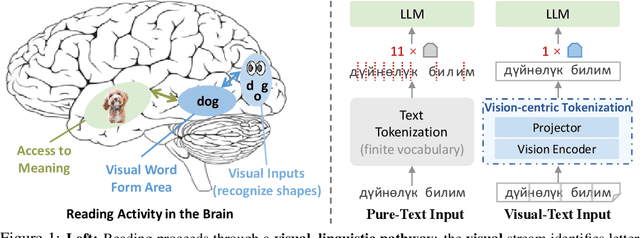

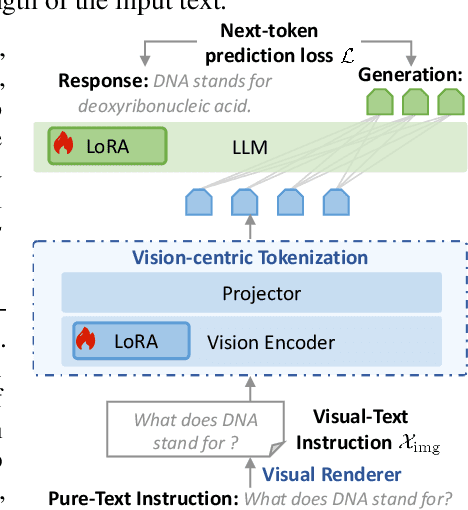

People see text. Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively. Modern large language models (LLMs), however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation. In this work, we challenge this entrenched paradigm and move toward a vision-centric alternative. Our method, SeeTok, renders text as images (visual-text) and leverages pretrained multimodal LLMs to interpret them, reusing strong OCR and text-vision alignment abilities learned from large-scale multimodal training. Across three different language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43 times fewer tokens and reducing FLOPs by 70.5%, with additional gains in cross-lingual generalization, robustness to typographic noise, and linguistic hierarchy. SeeTok signals a shift from symbolic tokenization to human-like visual reading, and takes a step toward more natural and cognitively inspired language models.
Hierarchical Relation-augmented Representation Generalization for Few-shot Action Recognition
Apr 14, 2025Few-shot action recognition (FSAR) aims to recognize novel action categories with few exemplars. Existing methods typically learn frame-level representations independently for each video by designing various inter-frame temporal modeling strategies. However, they neglect explicit relation modeling between videos and tasks, thus failing to capture shared temporal patterns across videos and reuse temporal knowledge from historical tasks. In light of this, we propose HR2G-shot, a Hierarchical Relation-augmented Representation Generalization framework for FSAR, which unifies three types of relation modeling (inter-frame, inter-video, and inter-task) to learn task-specific temporal patterns from a holistic view. In addition to conducting inter-frame temporal interactions, we further devise two components to respectively explore inter-video and inter-task relationships: i) Inter-video Semantic Correlation (ISC) performs cross-video frame-level interactions in a fine-grained manner, thereby capturing task-specific query features and learning intra- and inter-class temporal correlations among support features; ii) Inter-task Knowledge Transfer (IKT) retrieves and aggregates relevant temporal knowledge from the bank, which stores diverse temporal patterns from historical tasks. Extensive experiments on five benchmarks show that HR2G-shot outperforms current top-leading FSAR methods.
Vision-centric Token Compression in Large Language Model
Feb 04, 2025



Large Language Models (LLMs) have revolutionized natural language processing, excelling in handling longer sequences. However, the inefficiency and redundancy in processing extended in-context tokens remain a challenge. Many attempts to address this rely on compressing tokens with smaller text encoders, yet we question whether text encoders are truly indispensable. Our journey leads to an unexpected discovery-a much smaller vision encoder, applied directly to sequences of text tokens, can rival text encoders on text tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small text understanding benchmarks, VIST leads to comparable results with 16% fewer FLOPs and 50% less memory usage. We further uncover significant token redundancy and devise a frequency-based masking strategy to guide the focus of the visual encoder toward the most critical tokens. Interestingly, we observe the trained visual encoder performs like a summarizer, selectively ignoring less important words such as prepositions and conjunctions. This approach delivers remarkable results, outperforming traditional text encoder-based methods by 5.7% on average over benchmarks like TriviaQA, NQ, PopQA, TREF, SST2, and SST5, setting a new standard for token efficiency in LLMs.
Locality-aware Cross-modal Correspondence Learning for Dense Audio-Visual Events Localization
Sep 12, 2024



Dense-localization Audio-Visual Events (DAVE) aims to identify time boundaries and corresponding categories for events that can be heard and seen concurrently in an untrimmed video. Existing methods typically encode audio and visual representation separately without any explicit cross-modal alignment constraint. Then they adopt dense cross-modal attention to integrate multimodal information for DAVE. Thus these methods inevitably aggregate irrelevant noise and events, especially in complex and long videos, leading to imprecise detection. In this paper, we present LOCO, a Locality-aware cross-modal Correspondence learning framework for DAVE. The core idea is to explore local temporal continuity nature of audio-visual events, which serves as informative yet free supervision signals to guide the filtering of irrelevant information and inspire the extraction of complementary multimodal information during both unimodal and cross-modal learning stages. i) Specifically, LOCO applies Locality-aware Correspondence Correction (LCC) to uni-modal features via leveraging cross-modal local-correlated properties without any extra annotations. This enforces uni-modal encoders to highlight similar semantics shared by audio and visual features. ii) To better aggregate such audio and visual features, we further customize Cross-modal Dynamic Perception layer (CDP) in cross-modal feature pyramid to understand local temporal patterns of audio-visual events by imposing local consistency within multimodal features in a data-driven manner. By incorporating LCC and CDP, LOCO provides solid performance gains and outperforms existing methods for DAVE. The source code will be released.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022



Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021



There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.