 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Representations for Spatial Intelligence from Unposed Multi-View Images
Apr 12, 2026Robust 3D representation learning forms the perceptual foundation of spatial intelligence, enabling downstream tasks in scene understanding and embodied AI. However, learning such representations directly from unposed multi-view images remains challenging. Recent self-supervised methods attempt to unify geometry, appearance, and semantics in a feed-forward manner, but they often suffer from weak geometry induction, limited appearance detail, and inconsistencies between geometry and semantics. We introduce UniSplat, a feed-forward framework designed to address these limitations through three complementary components. First, we propose a dual-masking strategy that strengthens geometry induction in the encoder. By masking both encoder and decoder tokens, and targeting decoder masks toward geometry-rich regions, the model is forced to infer structural information from incomplete visual cues, yielding geometry-aware representations even under unposed inputs. Second, we develop a coarse-to-fine Gaussian splatting strategy that reduces appearance-semantics inconsistencies by progressively refining the radiance field. Finally, to enforce geometric-semantic consistency, we introduce a pose-conditioned recalibration mechanism that interrelates the outputs of multiple heads by re-projecting predicted 3D point and semantic maps into the image plane using estimated camera parameters, and aligning them with corresponding RGB and semantic predictions to ensure cross-task consistency, thereby resolving geometry-semantic mismatches. Together, these components yield unified 3D representations that are robust to unposed, sparse-view inputs and generalize across diverse tasks, laying a perceptual foundation for spatial intelligence.
Bilingual Text-to-Motion Generation: A New Benchmark and Baselines
Mar 26, 2026Text-to-motion generation holds significant potential for cross-linguistic applications, yet it is hindered by the lack of bilingual datasets and the poor cross-lingual semantic understanding of existing language models. To address these gaps, we introduce BiHumanML3D, the first bilingual text-to-motion benchmark, constructed via LLM-assisted annotation and rigorous manual correction. Furthermore, we propose a simple yet effective baseline, Bilingual Motion Diffusion (BiMD), featuring Cross-Lingual Alignment (CLA). CLA explicitly aligns semantic representations across languages, creating a robust conditional space that enables high-quality motion generation from bilingual inputs, including zero-shot code-switching scenarios. Extensive experiments demonstrate that BiMD with CLA achieves an FID of 0.045 vs. 0.169 and R@3 of 82.8\% vs. 80.8\%, significantly outperforms monolingual diffusion models and translation baselines on BiHumanML3D, underscoring the critical necessity and reliability of our dataset and the effectiveness of our alignment strategy for cross-lingual motion synthesis. The dataset and code are released at \href{https://wengwanjiang.github.io/BilingualT2M-page}{https://wengwanjiang.github.io/BilingualT2M-page}
Beyond Quadratic: Linear-Time Change Detection with RWKV
Mar 20, 2026Existing paradigms for remote sensing change detection are caught in a trade-off: CNNs excel at efficiency but lack global context, while Transformers capture long-range dependencies at a prohibitive computational cost. This paper introduces ChangeRWKV, a new architecture that reconciles this conflict. By building upon the Receptance Weighted Key Value (RWKV) framework, our ChangeRWKV uniquely combines the parallelizable training of Transformers with the linear-time inference of RNNs. Our approach core features two key innovations: a hierarchical RWKV encoder that builds multi-resolution feature representation, and a novel Spatial-Temporal Fusion Module (STFM) engineered to resolve spatial misalignments across scales while distilling fine-grained temporal discrepancies. ChangeRWKV not only achieves state-of-the-art performance on the LEVIR-CD benchmark, with an 85.46% IoU and 92.16% F1 score, but does so while drastically reducing parameters and FLOPs compared to previous leading methods. This work demonstrates a new, efficient, and powerful paradigm for operational-scale change detection. Our code and model are publicly available.
PCA-Seg: Revisiting Cost Aggregation for Open-Vocabulary Semantic and Part Segmentation
Mar 18, 2026Recent advances in vision-language models (VLMs) have garnered substantial attention in open-vocabulary semantic and part segmentation (OSPS). However, existing methods extract image-text alignment cues from cost volumes through a serial structure of spatial and class aggregations, leading to knowledge interference between class-level semantics and spatial context. Therefore, this paper proposes a simple yet effective parallel cost aggregation (PCA-Seg) paradigm to alleviate the above challenge, enabling the model to capture richer vision-language alignment information from cost volumes. Specifically, we design an expert-driven perceptual learning (EPL) module that efficiently integrates semantic and contextual streams. It incorporates a multi-expert parser to extract complementary features from multiple perspectives. In addition, a coefficient mapper is designed to adaptively learn pixel-specific weights for each feature, enabling the integration of complementary knowledge into a unified and robust feature embedding. Furthermore, we propose a feature orthogonalization decoupling (FOD) strategy to mitigate redundancy between the semantic and contextual streams, which allows the EPL module to learn diverse knowledge from orthogonalized features. Extensive experiments on eight benchmarks show that each parallel block in PCA-Seg adds merely 0.35M parameters while achieving state-of-the-art OSPS performance.
Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation
Feb 06, 2026The recent introduction of \texttt{SAM3} has revolutionized Open-Vocabulary Segmentation (OVS) through \textit{promptable concept segmentation}, which grounds pixel predictions in flexible concept prompts. However, this reliance on pre-defined concepts makes the model vulnerable: when visual distributions shift (\textit{data drift}) or conditional label distributions evolve (\textit{concept drift}) in the target domain, the alignment between visual evidence and prompts breaks down. In this work, we present \textsc{ConceptBank}, a parameter-free calibration framework to restore this alignment on the fly. Instead of adhering to static prompts, we construct a dataset-specific concept bank from the target statistics. Our approach (\textit{i}) anchors target-domain evidence via class-wise visual prototypes, (\textit{ii}) mines representative supports to suppress outliers under data drift, and (\textit{iii}) fuses candidate concepts to rectify concept drift. We demonstrate that \textsc{ConceptBank} effectively adapts \texttt{SAM3} to distribution drifts, including challenging natural-scene and remote-sensing scenarios, establishing a new baseline for robustness and efficiency in OVS. Code and model are available at https://github.com/pgsmall/ConceptBank.
Spatiotemporal-Untrammelled Mixture of Experts for Multi-Person Motion Prediction
Dec 25, 2025Comprehensively and flexibly capturing the complex spatio-temporal dependencies of human motion is critical for multi-person motion prediction. Existing methods grapple with two primary limitations: i) Inflexible spatiotemporal representation due to reliance on positional encodings for capturing spatiotemporal information. ii) High computational costs stemming from the quadratic time complexity of conventional attention mechanisms. To overcome these limitations, we propose the Spatiotemporal-Untrammelled Mixture of Experts (ST-MoE), which flexibly explores complex spatio-temporal dependencies in human motion and significantly reduces computational cost. To adaptively mine complex spatio-temporal patterns from human motion, our model incorporates four distinct types of spatiotemporal experts, each specializing in capturing different spatial or temporal dependencies. To reduce the potential computational overhead while integrating multiple experts, we introduce bidirectional spatiotemporal Mamba as experts, each sharing bidirectional temporal and spatial Mamba in distinct combinations to achieve model efficiency and parameter economy. Extensive experiments on four multi-person benchmark datasets demonstrate that our approach not only outperforms state-of-art in accuracy but also reduces model parameter by 41.38% and achieves a 3.6x speedup in training. The code is available at https://github.com/alanyz106/ST-MoE.
MUST: Multi-Scale Structural-Temporal Link Prediction Model for UAV Ad Hoc Networks
May 14, 2025Link prediction in unmanned aerial vehicle (UAV) ad hoc networks (UANETs) aims to predict the potential formation of future links between UAVs. In adversarial environments where the route information of UAVs is unavailable, predicting future links must rely solely on the observed historical topological information of UANETs. However, the highly dynamic and sparse nature of UANET topologies presents substantial challenges in effectively capturing meaningful structural and temporal patterns for accurate link prediction. Most existing link prediction methods focus on temporal dynamics at a single structural scale while neglecting the effects of sparsity, resulting in insufficient information capture and limited applicability to UANETs. In this paper, we propose a multi-scale structural-temporal link prediction model (MUST) for UANETs. Specifically, we first employ graph attention networks (GATs) to capture structural features at multiple levels, including the individual UAV level, the UAV community level, and the overall network level. Then, we use long short-term memory (LSTM) networks to learn the temporal dynamics of these multi-scale structural features. Additionally, we address the impact of sparsity by introducing a sophisticated loss function during model optimization. We validate the performance of MUST using several UANET datasets generated through simulations. Extensive experimental results demonstrate that MUST achieves state-of-the-art link prediction performance in highly dynamic and sparse UANETs.
Hierarchical Relation-augmented Representation Generalization for Few-shot Action Recognition
Apr 14, 2025Few-shot action recognition (FSAR) aims to recognize novel action categories with few exemplars. Existing methods typically learn frame-level representations independently for each video by designing various inter-frame temporal modeling strategies. However, they neglect explicit relation modeling between videos and tasks, thus failing to capture shared temporal patterns across videos and reuse temporal knowledge from historical tasks. In light of this, we propose HR2G-shot, a Hierarchical Relation-augmented Representation Generalization framework for FSAR, which unifies three types of relation modeling (inter-frame, inter-video, and inter-task) to learn task-specific temporal patterns from a holistic view. In addition to conducting inter-frame temporal interactions, we further devise two components to respectively explore inter-video and inter-task relationships: i) Inter-video Semantic Correlation (ISC) performs cross-video frame-level interactions in a fine-grained manner, thereby capturing task-specific query features and learning intra- and inter-class temporal correlations among support features; ii) Inter-task Knowledge Transfer (IKT) retrieves and aggregates relevant temporal knowledge from the bank, which stores diverse temporal patterns from historical tasks. Extensive experiments on five benchmarks show that HR2G-shot outperforms current top-leading FSAR methods.
Learning Clustering-based Prototypes for Compositional Zero-shot Learning
Feb 10, 2025



Learning primitive (i.e., attribute and object) concepts from seen compositions is the primary challenge of Compositional Zero-Shot Learning (CZSL). Existing CZSL solutions typically rely on oversimplified data assumptions, e.g., modeling each primitive with a single centroid primitive representation, ignoring the natural diversities of the attribute (resp. object) when coupled with different objects (resp. attribute). In this work, we develop ClusPro, a robust clustering-based prototype mining framework for CZSL that defines the conceptual boundaries of primitives through a set of diversified prototypes. Specifically, ClusPro conducts within-primitive clustering on the embedding space for automatically discovering and dynamically updating prototypes. These representative prototypes are subsequently used to repaint a well-structured and independent primitive embedding space, ensuring intra-primitive separation and inter-primitive decorrelation through prototype-based contrastive learning and decorrelation learning. Moreover, ClusPro efficiently performs prototype clustering in a non-parametric fashion without the introduction of additional learnable parameters or computational budget during testing. Experiments on three benchmarks demonstrate ClusPro outperforms various top-leading CZSL solutions under both closed-world and open-world settings.
Kernel-Aware Graph Prompt Learning for Few-Shot Anomaly Detection
Dec 23, 2024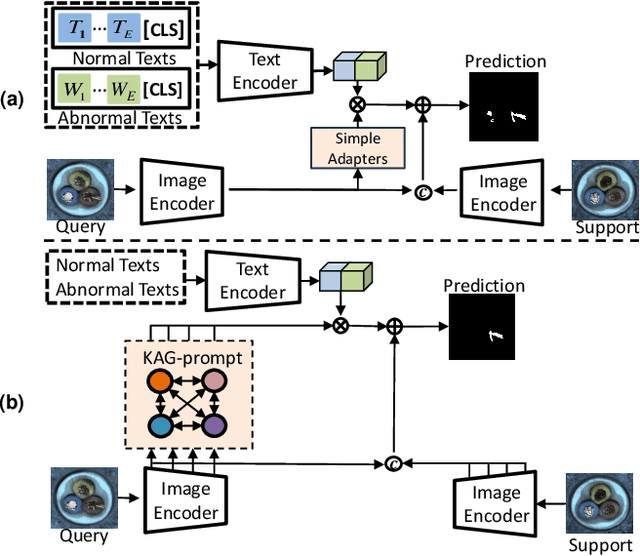
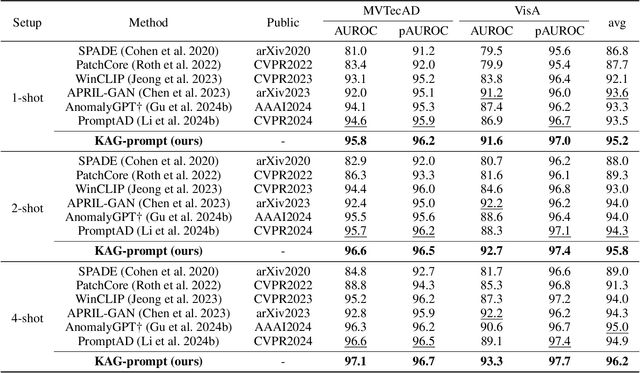
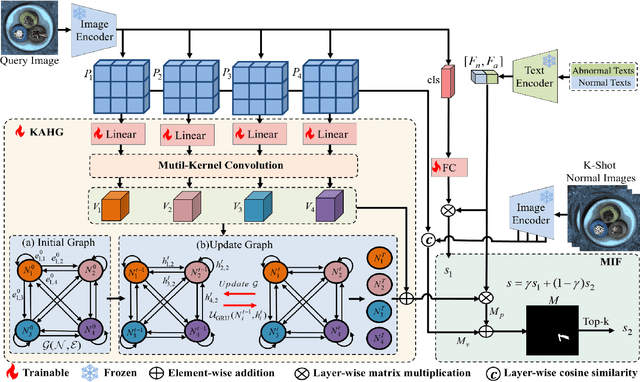
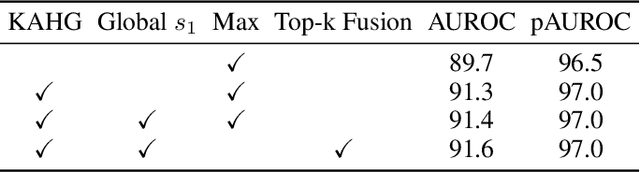
Few-shot anomaly detection (FSAD) aims to detect unseen anomaly regions with the guidance of very few normal support images from the same class. Existing FSAD methods usually find anomalies by directly designing complex text prompts to align them with visual features under the prevailing large vision-language model paradigm. However, these methods, almost always, neglect intrinsic contextual information in visual features, e.g., the interaction relationships between different vision layers, which is an important clue for detecting anomalies comprehensively. To this end, we propose a kernel-aware graph prompt learning framework, termed as KAG-prompt, by reasoning the cross-layer relations among visual features for FSAD. Specifically, a kernel-aware hierarchical graph is built by taking the different layer features focusing on anomalous regions of different sizes as nodes, meanwhile, the relationships between arbitrary pairs of nodes stand for the edges of the graph. By message passing over this graph, KAG-prompt can capture cross-layer contextual information, thus leading to more accurate anomaly prediction. Moreover, to integrate the information of multiple important anomaly signals in the prediction map, we propose a novel image-level scoring method based on multi-level information fusion. Extensive experiments on MVTecAD and VisA datasets show that KAG-prompt achieves state-of-the-art FSAD results for image-level/pixel-level anomaly detection. Code is available at https://github.com/CVL-hub/KAG-prompt.git.