 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitedVLN: Generalizable Gaussian Splatting for Continuous Vision-Language Navigation
Paper and Code
Nov 25, 2024
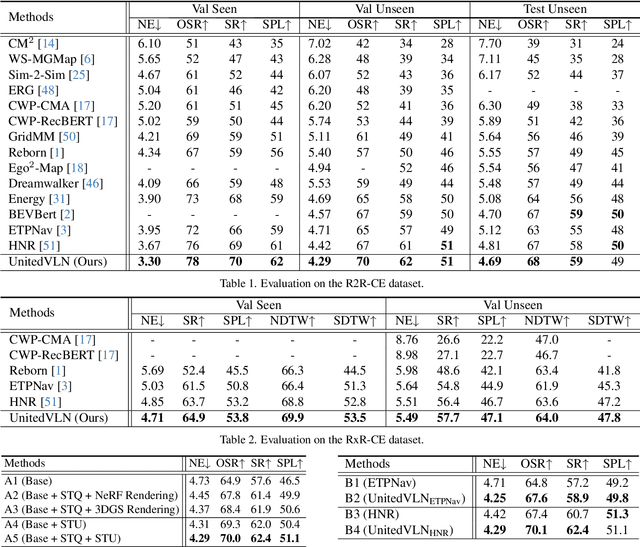
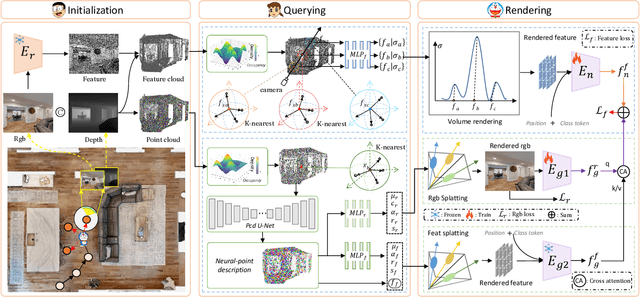
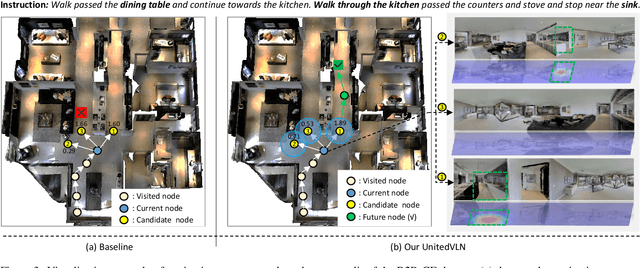
Vision-and-Language Navigation (VLN), where an agent follows instructions to reach a target destination, has recently seen significant advancements. In contrast to navigation in discrete environments with predefined trajectories, VLN in Continuous Environments (VLN-CE) presents greater challenges, as the agent is free to navigate any unobstructed location and is more vulnerable to visual occlusions or blind spots. Recent approaches have attempted to address this by imagining future environments, either through predicted future visual images or semantic features, rather than relying solely on current observations. However, these RGB-based and feature-based methods lack intuitive appearance-level information or high-level semantic complexity crucial for effective navigation. To overcome these limitations, we introduce a novel, generalizable 3DGS-based pre-training paradigm, called UnitedVLN, which enables agents to better explore future environments by unitedly rendering high-fidelity 360 visual images and semantic features. UnitedVLN employs two key schemes: search-then-query sampling and separate-then-united rendering, which facilitate efficient exploitation of neural primitives, helping to integrate both appearance and semantic information for more robust navigation. Extensive experiments demonstrate that UnitedVLN outperforms state-of-the-art methods on existing VLN-CE benchmarks.