 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3D-VLP: Dynamic 3D Vision-Language-Planning Model for Embodied Grounding and Navigation
Dec 14, 2025Embodied agents face a critical dilemma that end-to-end models lack interpretability and explicit 3D reasoning, while modular systems ignore cross-component interdependencies and synergies. To bridge this gap, we propose the Dynamic 3D Vision-Language-Planning Model (D3D-VLP). Our model introduces two key innovations: 1) A Dynamic 3D Chain-of-Thought (3D CoT) that unifies planning, grounding, navigation, and question answering within a single 3D-VLM and CoT pipeline; 2) A Synergistic Learning from Fragmented Supervision (SLFS) strategy, which uses a masked autoregressive loss to learn from massive and partially-annotated hybrid data. This allows different CoT components to mutually reinforce and implicitly supervise each other. To this end, we construct a large-scale dataset with 10M hybrid samples from 5K real scans and 20K synthetic scenes that are compatible with online learning methods such as RL and DAgger. Our D3D-VLP achieves state-of-the-art results on multiple benchmarks, including Vision-and-Language Navigation (R2R-CE, REVERIE-CE, NavRAG-CE), Object-goal Navigation (HM3D-OVON), and Task-oriented Sequential Grounding and Navigation (SG3D). Real-world mobile manipulation experiments further validate the effectiveness.
MUST: Multi-Scale Structural-Temporal Link Prediction Model for UAV Ad Hoc Networks
May 14, 2025Link prediction in unmanned aerial vehicle (UAV) ad hoc networks (UANETs) aims to predict the potential formation of future links between UAVs. In adversarial environments where the route information of UAVs is unavailable, predicting future links must rely solely on the observed historical topological information of UANETs. However, the highly dynamic and sparse nature of UANET topologies presents substantial challenges in effectively capturing meaningful structural and temporal patterns for accurate link prediction. Most existing link prediction methods focus on temporal dynamics at a single structural scale while neglecting the effects of sparsity, resulting in insufficient information capture and limited applicability to UANETs. In this paper, we propose a multi-scale structural-temporal link prediction model (MUST) for UANETs. Specifically, we first employ graph attention networks (GATs) to capture structural features at multiple levels, including the individual UAV level, the UAV community level, and the overall network level. Then, we use long short-term memory (LSTM) networks to learn the temporal dynamics of these multi-scale structural features. Additionally, we address the impact of sparsity by introducing a sophisticated loss function during model optimization. We validate the performance of MUST using several UANET datasets generated through simulations. Extensive experimental results demonstrate that MUST achieves state-of-the-art link prediction performance in highly dynamic and sparse UANETs.
UnitedVLN: Generalizable Gaussian Splatting for Continuous Vision-Language Navigation
Nov 25, 2024
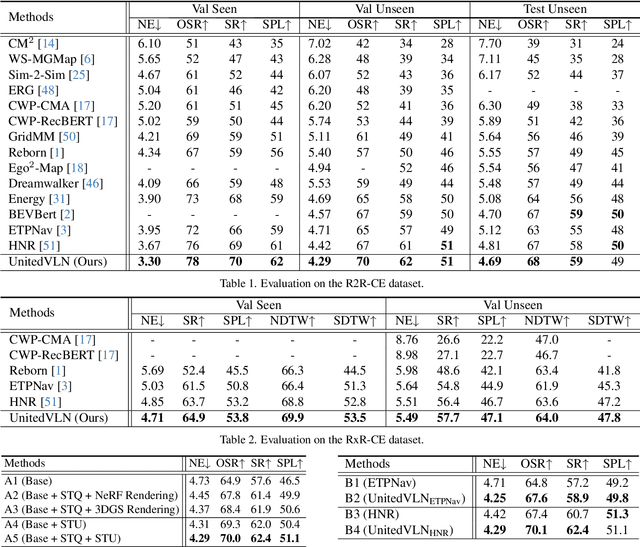
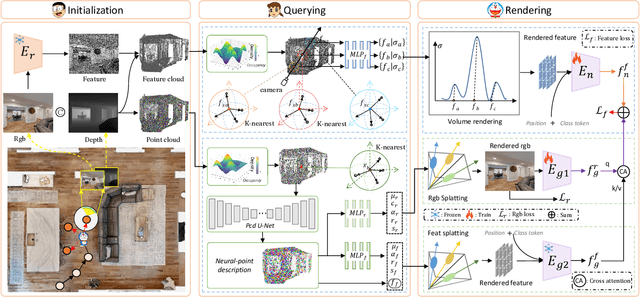
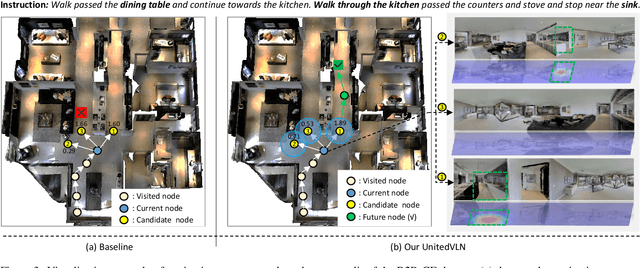
Vision-and-Language Navigation (VLN), where an agent follows instructions to reach a target destination, has recently seen significant advancements. In contrast to navigation in discrete environments with predefined trajectories, VLN in Continuous Environments (VLN-CE) presents greater challenges, as the agent is free to navigate any unobstructed location and is more vulnerable to visual occlusions or blind spots. Recent approaches have attempted to address this by imagining future environments, either through predicted future visual images or semantic features, rather than relying solely on current observations. However, these RGB-based and feature-based methods lack intuitive appearance-level information or high-level semantic complexity crucial for effective navigation. To overcome these limitations, we introduce a novel, generalizable 3DGS-based pre-training paradigm, called UnitedVLN, which enables agents to better explore future environments by unitedly rendering high-fidelity 360 visual images and semantic features. UnitedVLN employs two key schemes: search-then-query sampling and separate-then-united rendering, which facilitate efficient exploitation of neural primitives, helping to integrate both appearance and semantic information for more robust navigation. Extensive experiments demonstrate that UnitedVLN outperforms state-of-the-art methods on existing VLN-CE benchmarks.
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition
May 04, 2024Panoramic Activity Recognition (PAR) aims to identify multi-granularity behaviors performed by multiple persons in panoramic scenes, including individual activities, group activities, and global activities. Previous methods 1) heavily rely on manually annotated detection boxes in training and inference, hindering further practical deployment; or 2) directly employ normal detectors to detect multiple persons with varying size and spatial occlusion in panoramic scenes, blocking the performance gain of PAR. To this end, we consider learning a detector adapting varying-size occluded persons, which is optimized along with the recognition module in the all-in-one framework. Therefore, we propose a novel Adapt-Focused bi-Propagating Prototype learning (AdaFPP) framework to jointly recognize individual, group, and global activities in panoramic activity scenes by learning an adapt-focused detector and multi-granularity prototypes as the pretext tasks in an end-to-end way. Specifically, to accommodate the varying sizes and spatial occlusion of multiple persons in crowed panoramic scenes, we introduce a panoramic adapt-focuser, achieving the size-adapting detection of individuals by comprehensively selecting and performing fine-grained detections on object-dense sub-regions identified through original detections. In addition, to mitigate information loss due to inaccurate individual localizations, we introduce a bi-propagation prototyper that promotes closed-loop interaction and informative consistency across different granularities by facilitating bidirectional information propagation among the individual, group, and global levels. Extensive experiments demonstrate the significant performance of AdaFPP and emphasize its powerful applicability for PAR.
GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition
Jan 18, 2024Vision-Language Models (VLMs), pre-trained on large-scale datasets, have shown impressive performance in various visual recognition tasks. This advancement paves the way for notable performance in Zero-Shot Egocentric Action Recognition (ZS-EAR). Typically, VLMs handle ZS-EAR as a global video-text matching task, which often leads to suboptimal alignment of vision and linguistic knowledge. We propose a refined approach for ZS-EAR using VLMs, emphasizing fine-grained concept-description alignment that capitalizes on the rich semantic and contextual details in egocentric videos. In this paper, we introduce GPT4Ego, a straightforward yet remarkably potent VLM framework for ZS-EAR, designed to enhance the fine-grained alignment of concept and description between vision and language. Extensive experiments demonstrate GPT4Ego significantly outperforms existing VLMs on three large-scale egocentric video benchmarks, i.e., EPIC-KITCHENS-100 (33.2%, +9.4%), EGTEA (39.6%, +5.5%), and CharadesEgo (31.5%, +2.6%).